排障指标革命性新突破,北极星指标让故障无所遁形--北极星因果指标产品正式发布

传统排障方法的局限性
传统故障排查的痛点
在复杂的分布式系统中,故障排查一直是一个让人头疼的问题,其中机器宕机、进程存活、程序异常报错等故障相对而言比较好排查,有直接的指标能够反应出问题,难排查的问题是流量突增,时延变化等故障,特别是在分布式系统中,这类故障更难排查。传统的方法往往需要工程师逐一排查各种可能性,耗费大量时间和精力,效率低下且盲目。
传统故障排查方法的低效性主要源于以下几点:
- 时间消耗巨大: 需要逐一检查系统中的各个组件和指标,排查流程繁琐,耗时长。
- 盲目性: 没有明确的线索指引,排查过程中往往需要凭借经验和直觉,试错成本高。
- 数据分散: 各类监控指�标彼此独立,缺乏统一的视图,导致难以全面了解系统状态。
这些痛点的根源在于我们所使用的指标大多是结果性指标,指向性不明确。例如,CPU利用率、内存使用率等指标只能反映系统的当前状态,却无法直接指出问题的根源,给故障排查带来了巨大的挑战。
常规的指标局限
在实际应用中,工程师们常常依赖于各种常规的性能指标,例如:
- CPU指标: 反映系统的计算资源使用情况。高CPU使用率可能是由于多个原因导致的,例如某个服务在进行高计算密集型操作。但是,CPU指标并不能告诉我们具体是哪个请求导致了高CPU使用率,通过人为分析才能知道是哪个进程的CPU使用率高,然后借助更多的工具才能知道可能是哪一段代码导致的,但是业界还缺少业务视角关联,没有办法知道哪个URL导致了CPU升高。
- 网络指标: 反映网络传输的性能。无法明确是哪一个具体请求导致的带宽占用,例如一个文件服务器在处理多个文件上传和下载请求。网络指标只能显示整体的网络带宽使用情况上升,却不能确定是哪个具体请求导致的带宽占用增加,也缺少业务视角关联。
- 文件指标: 反映磁盘I/O操作的效率。高磁盘IO使用可能是因为某些请求涉及大量的文件读写操作。然而无法具体指明是哪一个请求导致的磁盘IO高使用,缺少业务关联视角。
- 内存指标: 反映系统的内存使用情况,同理缺少业务关联视角。
- GC指标: 反映垃圾回收的频率和时间,同理缺少业�务关联视角。
虽然这些指标在一定程度上帮助我们了解系统的运行状态,但它们彼此独立,无法构建出一个完整的故障图景。这种独立性导致了以下问题:
- 无法关联: 各个指标之间缺乏关联,难以看出它们之间的因果关系。
- 片面视角: 只能看到单个指标的表现,无法形成整体视图。
- 低效排查: 无法通过单一指标判断问题的根源,需要逐一排除各种可能性,效率低下。
常规指标的这种局限性导致在排障过程中,我们常常需要逐一排查每一个可能的原因,耗费大量时间和精力,难以快速定位问题。
北极星指标带来的革命性变化

业界提供因果性的工具
为了应对复杂系统中的故障排查问题,业界提出了一些具有间接因果性的工具。然而,这些工具和方法也有其局限性:
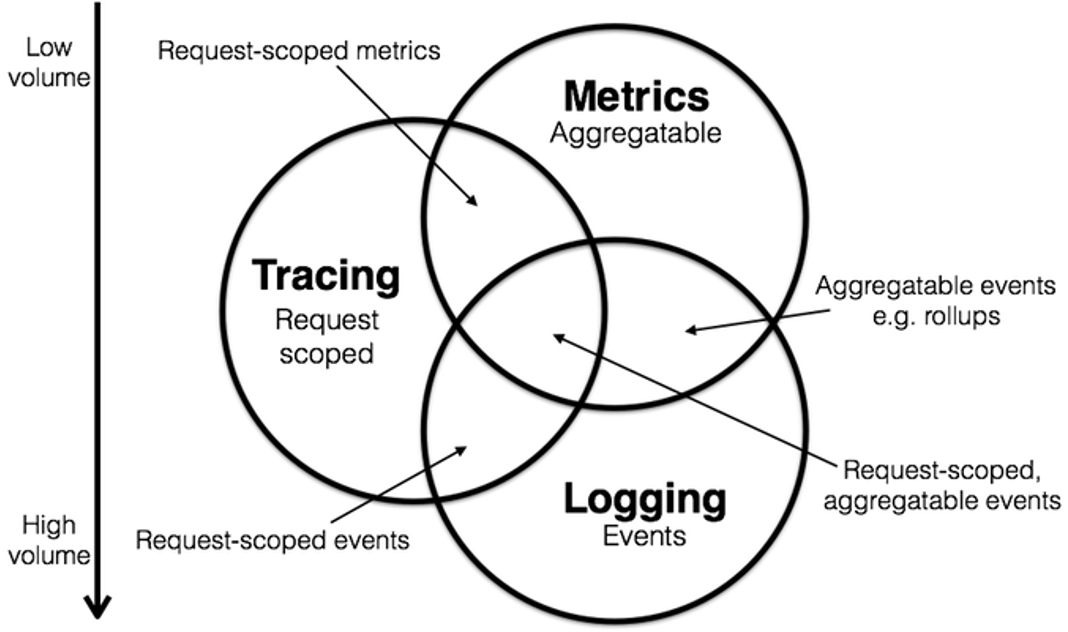
- 分布式追踪(Distributed Tracing):
○优点: 提供请求的完整路径信息,详细展示每个服务调用的耗时,帮助识别系统中的延迟和瓶颈。
○局限性: 在稍微复杂的场景下,因噪音和故障级联的存在,瓶颈点经常会被误判。需要结合业务逻辑和经验分析,才能推断因果关系,找到真正的瓶颈点。
- 依赖图(Dependency Graph):
○优点: 展示系统组件之间的依赖关系,便于理解系统架构,帮助识别关键路径和潜在的瓶颈。
○局限性: 依赖图是静态分析工具,无法实时反映系统运行状态。随着系统规模的增加,依赖图的复杂性也增加,难以管理和维护。
- 日志(Logging):
○优点: 详细记录系统运行状态和事件,便于追踪和分析,具有高度的定制性,可以记录各种所需的信息。
○局限性: 需要精心设计和管理日志记录策略,否则会产生大量无用数据。分析日志数据需要强大的工具和技术,如ELK栈。日志数据分散,难以直接构建因果关系,需要结合其他数据进行综合分析。
- 事件监控(Event Monitoring):
○优点: 可以实时监控系统中的各种事件,如错误、警告等,帮助快速响应和处理异常事件。
○局限性: 事件监控通常是离散的,难以直接构建事件之间的因果关系。需要结合历史数据和上下文信息进行分析和推断。
利用eBPF技术获取北极星指标
北极星因果指标的获取依赖于先进的分布式追踪技术和内核级数据关联。具体过程如下:
- 分布式追踪: 首先,通过分布式追踪技术,捕获每个请求的完整路径信息。这包括请求在不同服务节点之间的传递和处理时间。
- eBPF在内核追踪线程信号: 在系统内核中,追踪执行请求的线程信号。这些信号反映了线程在处理请求过程中的各个状态变化和资源使用情况。
- eBPF在内核实现系统调用信号关联: 将分布式追踪数据与系统调用信号关联起来,形成对请求处理全过程的详细分解。这一步骤涉及将应用层的请求数据与内核层的系统调用数据进行关联,确保每个请求的所有资源使用情况都被捕获和分析。
通过这种方法,我们能够生成北极星因果指标。该指标不仅提供了各个性能指标的详细数据,还展示了它们之间的因果关系,从而帮助工程师快速定位故障根源,提升排障效率。
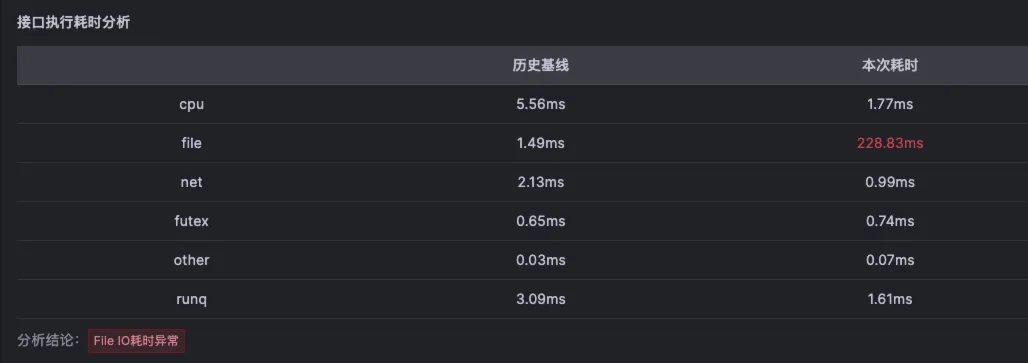
北极星因果指标的组成: 一次业务视角的请求耗时被完美且完整拆解成以下指标

CPU耗时
- 定义和意义
○指请求在CPU上消耗的时间。
- 如何影响请求处理
○高CPU耗时可能指向计算密集型任务比如循环和递归。
网络耗时
- 定义和意义
○指请求在网络传输中消耗的时间。
- 如何影响请求处理
○高网络耗时可能指向网络延迟、带宽不足或下游节点代码执行异常,典型的就是SQL语句执行慢。
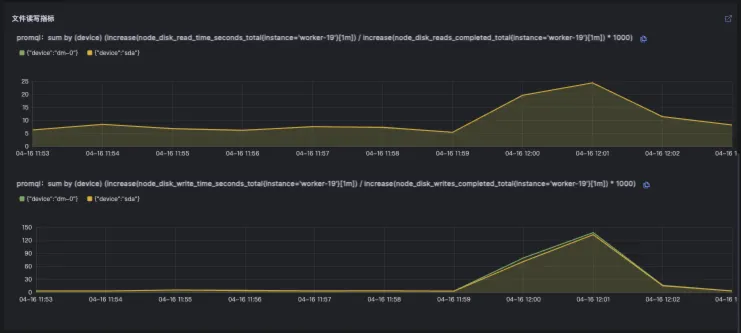
文件读写耗时
- 定义和意义
○指请求在文件系统读写操作中消耗的时间。
- 如何影响请求处理
○高文件读写耗时可能指向磁盘I/O瓶颈或文件系统问题。
内存消耗耗时
- 定义和意义
○指请求在内存分配和管理中消耗的时间。
- 如何影响请求处理
○高内存耗时可能指向内存泄漏、内存分配不当或频繁触发Pagefault。
锁耗时
- 定义和意义
○指请求在等待锁资源中消耗的时间。
- 如何影响请求处理
○高锁耗时可能指向锁争用、死锁或锁机制设计不合理, 绝大多数都是代码类库使用了隐藏锁而开发人员不自知,比如数据�库连接池锁等。
GC耗时
- 定义和意义
○指请求在垃圾回收过程中消耗的时间。
- 如何影响请求处理
○高GC耗时可能指向内存管理不当或垃圾回收频繁触发。
CPU调度耗时
- 定义和意义
○指请求在执行过程中,由于CPU调度而产生的延时
- 如何影响请求处理
○高CPU调度耗时,意味着容器的CPU资源不充分。
为什么北极星因果指标是排障的最关键指标
基于北极星因果指标排障,立刻获得了多个性能指标的关联分析结果,有了系统的整体视图。
北极星因果指标具有以下独特优势:
- 因果性:
○北极星指标通过数据关联和因果关系分析,提供了请求处理过程中的详细分解。各个指标之间的因果关系明确,能够帮助工程师快速定位问题根源。
- 全面性且无盲区遗漏:
○北极星指标覆盖了请求处理的全过程,从CPU耗时、网络耗时、文件读写耗时,到内存消耗耗时、锁耗时和GC耗时,确保了指标的全面性并且没有盲区。
- 高效性:
○通过提供因果关系视图,北极星指标可以快速定位故障根源,减少排障时间和降低排障复杂性。工程师无需逐一排查每一个可能的原因,而是能够通过整体视图快速确定问题所在。
- 一体化视图:
○北极星指标将多个独立的性能指标整合为一体化视图,便于综合分析和决策。这样,工程师在查看指标时,不再需要切换不同的监控工具,而是可以在一个视图中看到所有关键性能指标及其关联关系。
总结
北极星因果指标的引入,彻底改变了故障排查的方式。通过提供因果关系和全面视图,它不仅提升了排障效率,还显著减少了排障过程中的盲目性和试错成本,真正实现了高效、精准的故障排查。
●永久免费
●多语言支持:Java、Python、Nodejs、一键安装
●标准PQL语句查询数据
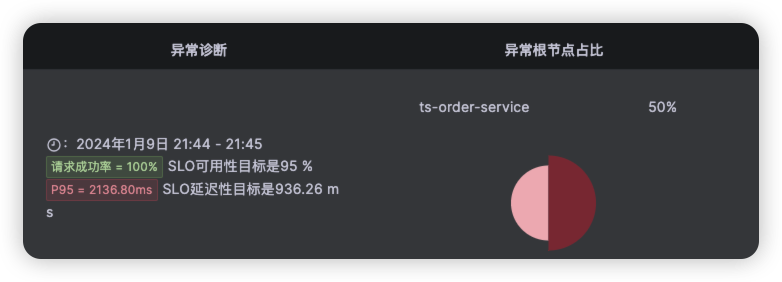
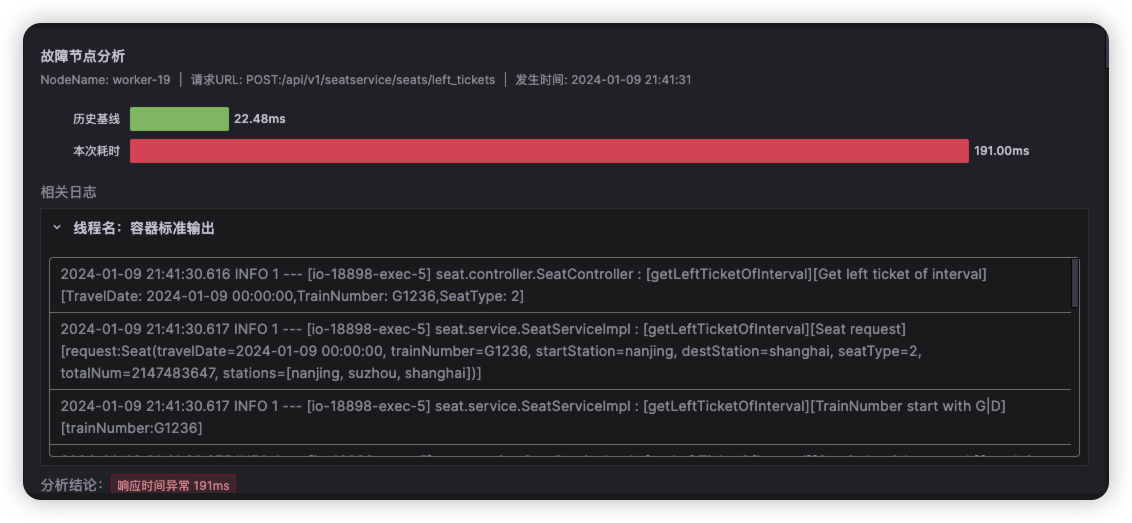
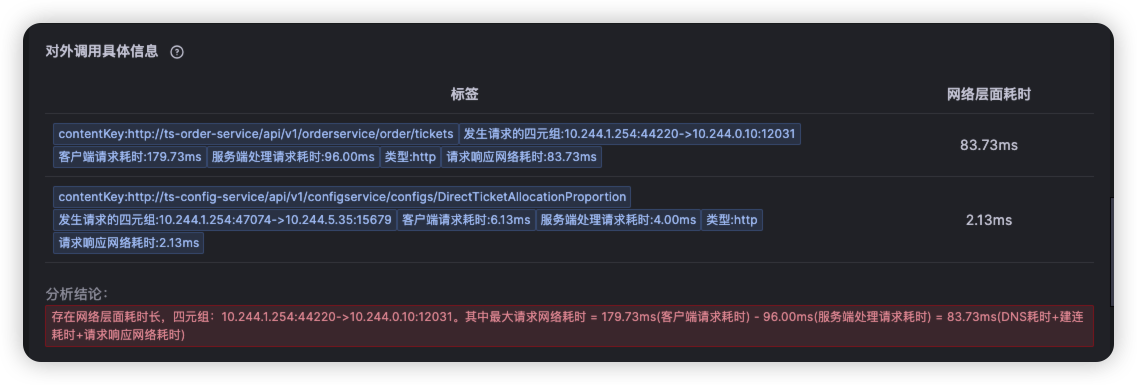
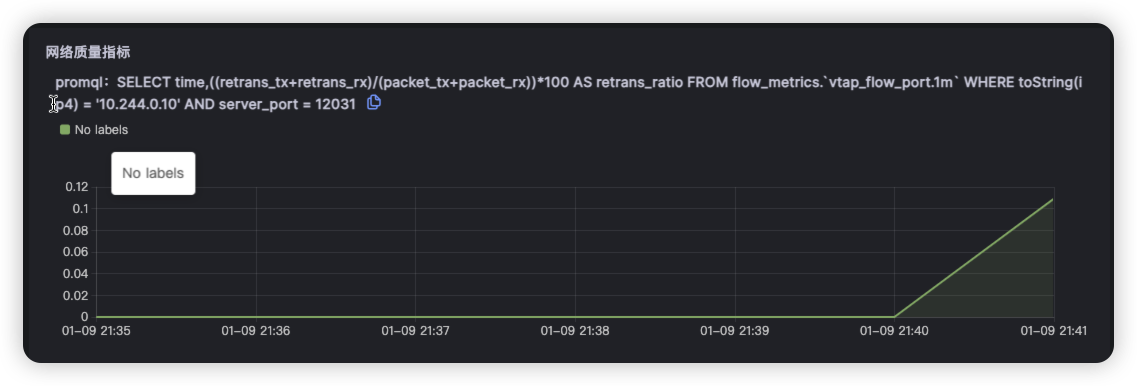
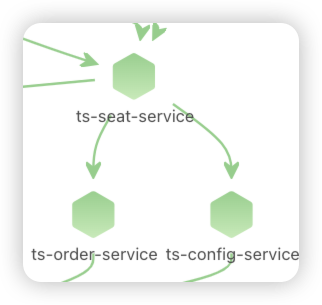
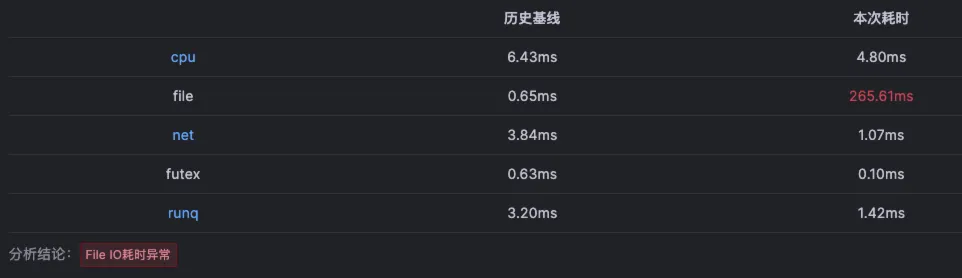
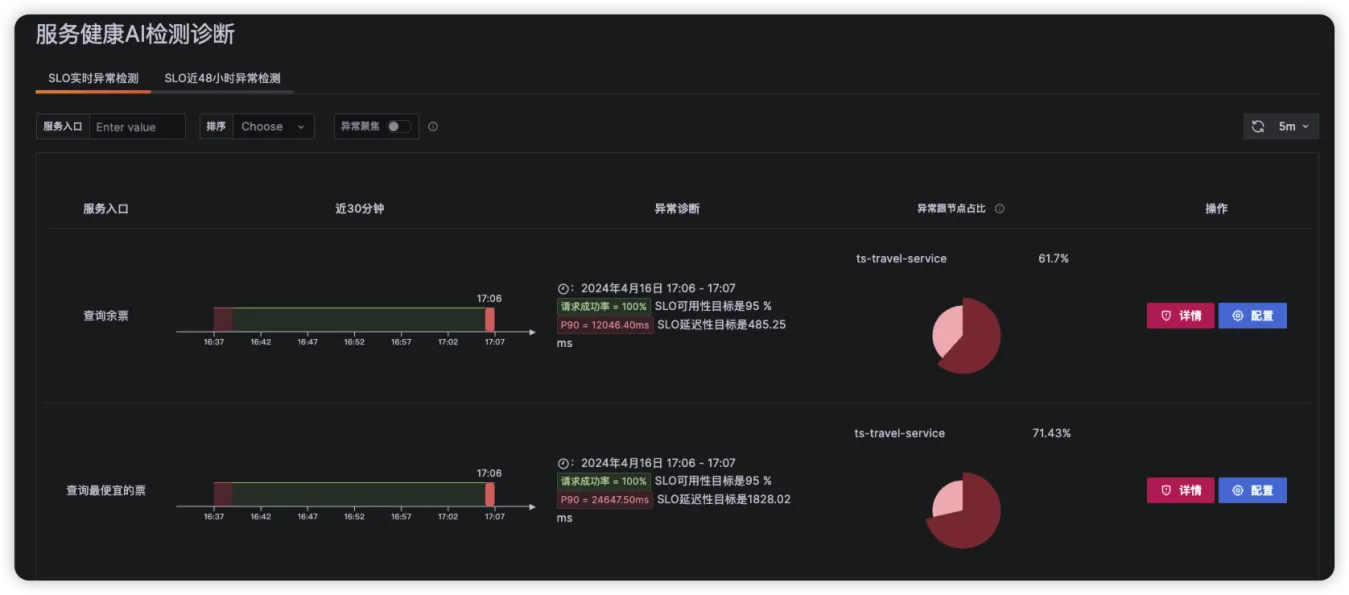
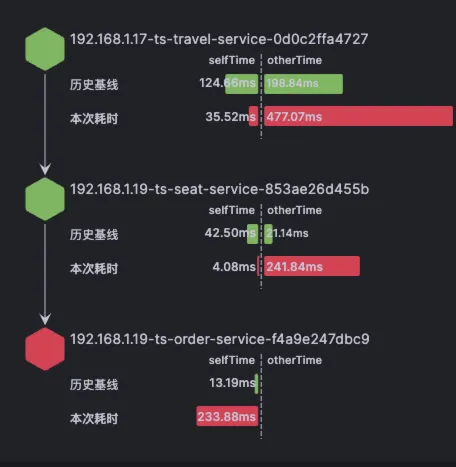
 点击ts-seat-service的TraceID后进入该节点最新的故障报告。一份故障根因诊断报告有部分内容及多种相关Log、Trace、Metrics数据聚合分析而成,这里分别简单介绍。
点击ts-seat-service的TraceID后进入该节点最新的故障报告。一份故障根因诊断报告有部分内容及多种相关Log、Trace、Metrics数据聚合分析而成,这里分别简单介绍。