APO在一个页面整合关联可观测性数据的设计思路

可观测性能力是系统在运行过程中,通过收集、关联和分析不同类型的数据,来理解和解释系统行为的能力。其目标不仅是发现问题,还要提供足够的信息来分析和解决这些问题,甚至在问题发生之前预见潜在的风险。
划重点:关联分析不同类型的数据,帮助用户理解和解释系统行为的能力是可观测性系统建设的关键目标。
可观测性数据不是简单将Trace、Metric、log,三者数据做在一个产品里面,三者仍然是割裂的数据。OpenTelemetry的出现给三者内在有机关联带来了更多可能性,如何关联这些数据并且呈现仍然有许多挑战。本文探讨APO团队对如何关联可观测性的设计思路,目标是能够在一个页面关联微服务接口所有故障排查需要的相关数据,完成故障的定界定位。
思路一:简单关联独立展示(帮助用户减少了登录次数)
最容��易想到的关联方式,就是将三者数据分为三个Tab显示,每个tab只负责展示自身的数据,数据之间仍然缺少关联和提示。
如果用户要做关联查询经常要完成这样的操作:
- 在Trace 页中筛选出Trace信息,确认该Trace可能有问题,然后拷贝该TraceID,相关的IP信息,servicename,podname等相关信息也拷贝出来用来查询指标(有时还需要打命令才能查询出pod所对应的node在哪,在虚拟机里面可能还需要在cmdb根据IP查出node的唯一标识)
- 在Log页中,如果log已经输出了TraceID,可以通过TraceID搜索到相关的日志,如果日志未输出TraceID,就比较难以查询到日志
- 在Metric页面,根据servciename、podname、ip信息、node唯一标识完成指标的查询
思路二:简单关联但是数据串联(帮助用户减少了拷贝TraceID的时间)
在简单关联中,很容易进一步想到,能不能在展示Trace的时候,通过TraceID直接查看日志,而不用去拷贝TraceID至log页中查询。目前很多工具已经做到了这一步的关联,但是很多工具也就停留在这一步,在这个思路上其实还可以进一步关联,也就是将"思路一"所有可能要人为操作的功能,提前帮助用户查询好,用户可以沿着各种链接跳转至不同的数据当中。
很多可观测性平台按照"思路二"完成数据的串联之后就结束了,但是用户在使用过程中会容易出现以下的问题:
缺少全局统计信息,从单个Trace出发,虽然能在不同ROOT SPAN中查看指标、日志等相关信息,但是由于没有统计信息,很容易一叶障目。为了让大家理解更深刻,举例说明即便没有任何故障,延时落在P50的Trace表现和延时落在P99的Trace表现相差很大。
由于没有统计信息导致、确定故障根因节点困难。假设业务操作入口--"下单接口"出现了20%的错误率同比升高,下单接口正常时大概有1%的错误率,现在错误率升高了,仅仅分析出错的Trace可能并不能很好的分析出问题,因为很难确定者错误的Trace是新增错误,还是以往就有的错误。
怎么办?不能从局部去排查问题,而是应该以微服务接口(Service+URL)的方式去查看数据, 因为微服务接口有其黄金指标,可以很快判断微服务接口是否异常,如果异常,接下来需要做的是在关联各种可能需要查看的数据至该微服务接口详情页中,这样就可以有全局信息,快速判断该微服务接口是不是故障根因。
思路三:以微服务接口(Service+URL)为入口,更好统计信息更多的关联数据、减少以偏概全的风险
根据黄金指标的统计信息,可以很快判断哪些微服务接口是有问题的,比如同比延时高,同比错误率高。那接下来的问题就是点击微服务接口(Service+URL)详情之后,如何关联数据。
初步想法:可以将Trace页、Metric页、Log页作为独立tab集成至微服务接口的详情页中,接口层和应用层告警信息也能关联至详情页
这样在详情页中
Log页,可以提前过滤出该微服务接口的日志
Trace页,可以提前过滤出调用过该微服务接口的Trace
Metric页,由于微服务接口缺少实例等相关资源tag元数据,用户需要提前根据service,查出实例信息,然后查出Node信息,将实例和Node信息进行完整的展示
告警信息也可以关联进来,但是只能关联接口层和应用层面告警信息:比如Service实例应用级别的告警,比如延时、错误率、吞吐量、JVM告警等信息
进一步想法:提前将微服务接口的微服务实例和实例所属Node信息查询并关联,实例和Node之间的网络质量也可以关联进来
这样在详情页中,可以进一步显示:
Log页,可以提前过滤出该service+URL的日志
Trace页,可以提前过滤出service+URL的Trace
Metric页,微服务所有实例和所在Node的资源指标信息,所有建连的网络质量指标也可以关联进来
告警信息:除了应用层的告警信息,还可以关联资源层面的告警信息容器实例、node资源级别告警能被关联进来,用户对全局更有掌握
还有没有能够进一步的关联信息呢?能够缩小日志和Trace的排查范围,过滤出更容易让用户一击即中的日志和Trace呢?避免在海量的日志和Trace中不断试错
再进一步想法:分析相关的Trace,并提取Exception,关联时间段内所有Exception的日志信息,并展示Exception的传播链路
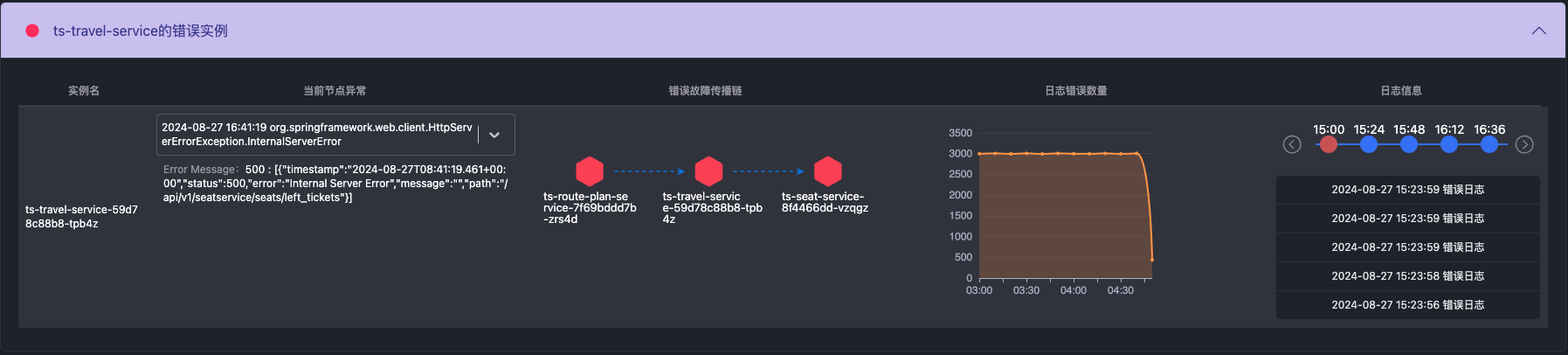
通过提前分析经过该微服务接口的trace,提取出所有的Exception信息,然后展示故障传播链路,并可以根据Exception信息关联含有该Exception的日志。同时提供日志出错的数量变化曲线,帮助用户更好的定位到底要查看哪些Trace和日志。在该tab中,通过时间轴选取的日志信息,全都含有Exception或者错误信息。
 带有Exception的日志
带有Exception的日志
这样用户排查日志和Trace的时候,是可以根据日志错误曲线、Exception种类信息导航至出错的日志和Trace,而不是查看所有的日志,或者搜索有Exception的日志,然后再去关联Trace一个一个查,从而帮助用户对错误有更深入的理解。传播链可以快速导航定位至下游依赖的服务接口。
微服务的接口详情页,还需要什么信息来辅助定界故障呢?
还进一步想法:根据URL级别拓扑,关联业务操作入口-快速实现故障影响面分析
很多可观测性工具只有应用级别的拓扑图,缺少URL级别的拓扑视图。应用级别的拓扑图其实是整个集群的业务执行拓扑,要从完整的拓扑中,区分出不同业务操作接口的执行路径有一定难度。
URL级别的拓扑能够反映某具体业务操作的执行路径。
业界王者Dynatrace的Service Flow本质上实现的就是URL级别的拓扑。
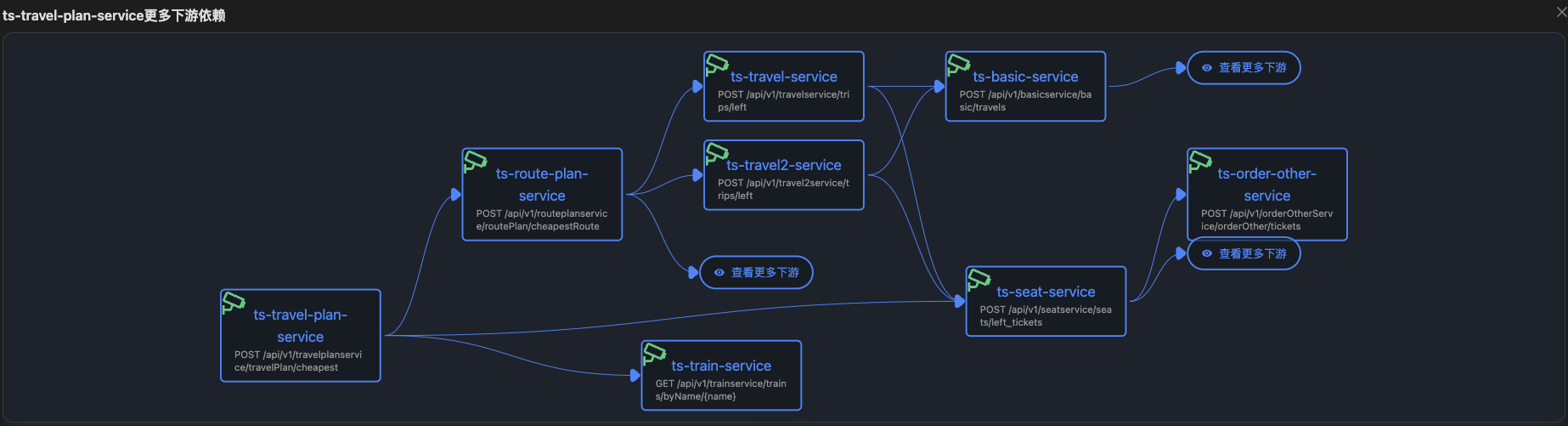 URL级别拓扑每个节点代表service+URL
URL级别拓扑每个节点代表service+URL
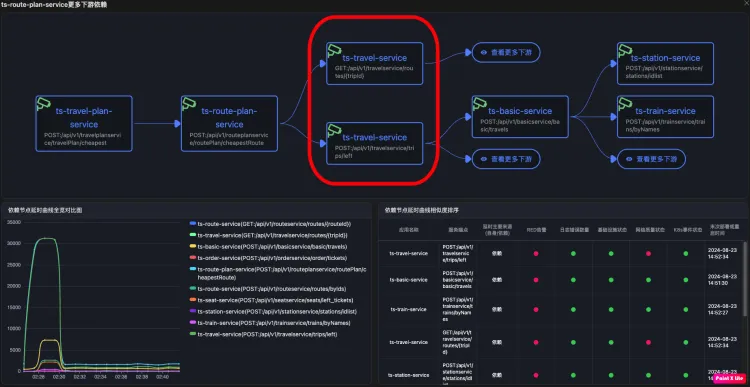 同一个服务不同的URL会作为不同节点出现
同一个服务不同的URL会作为不同节点出现
URL级别拓扑结构的优势
1.精确的故障定位:
- URL级别的拓扑结构允许你精确识别某个特定URL或API调用的故障及其在整个系统中的传播路径。这对于识别单个请求路径的性能问题、错误率或流量瓶颈尤其有用。
2.详细的依赖关系分析:
- 通过URL级别的拓扑图,你可以看到每个请求如何穿过不同的服务和依赖组件。这有助于理解某个URL请求的依赖链条,从而识别哪个具体环节出现了问题。
3.更细粒度的影响分析:
- URL级别的拓扑结构可以让你评估特定API调用或功能的影响范围,特别是在微服务架构中,不同的URL可能对应不同的服务或操作。这对于分析特定功能或业务逻辑的故障影响尤为关键。
基于URL级别拓扑结构的故障影响面分析
任意微服务接口,都存在于某业务操作的URL级别拓扑结构中,通过微服务接口逆查,就可以快速找到业务操作入口,然后可以根据业务操作入口的延时、错误率、吞吐量等同比指标快速判断业务操作入口有没有受到故障影响。
根据故障影响的严重程度,从而快速判断是否需要紧急介入,以及多少团队介入。(该功能将在APO9月版本迭代中发布)
基于URL级别拓扑结构关联中间件告警
根据URL级别拓扑接口,可以很清楚的判定某些中间件的告警是否和业务操作入口有关联,未来版本APO规划完成中间件指标监控之后,将中间件告警也关联进微服务接口详情页中,这样可以更好的判断微服务接口异常是否由于中间件告警而产生。
基于URL级别拓扑结构关联下游微服务接口告警
根据URL级别拓扑接口,可以很清楚的判定某些中间件的告警是否和业务操作入口有关联,未来版本APO规划关联下游微服务接口告警,这样提供多维信息判断是否需要排查下游接口,同时可以根据具体Trace信息来相互佐证,快速实现故障定界定位。
最后关联北极星指标完成延时问题的兜底
对于错误率上升的问题,通过关联exception和错误日志一般情况下能够实现对错误率上升故障的兜底解决。对于延时同比增加的�问题,使用北极星指标一定能回答延时增加是由于什么原因导致的。关于北极星指标是什么,请参考链接 one.kindlingx.com
关联Trace和日志tab,帮助用户通过Trace和日志来佐证故障
当用户排查过以上的数据,基本上能回答告警影响面有多大,错误率上升和延时上升是什么原因了。通过快速查询Trace和日志可以用来佐证故障原因。
总结
APO是向导式可观测性产品,在一个页面关联了接口级的所有故障相关信息。
| 接口关联数据 | 故障场景 |
|---|---|
| 接口自身的告警信息,应用层、资源层告警 | 告警分析 |
| 接口的影响业务入口黄金指标 | 影响面分析 |
| 接口的下游依赖告警关联 | 级联告警影响分析 |
| ��接口的实例和节点的资源指标 | 饱和度分析 |
| 接口的网络指标 | 网络质量分析 |
| 接口的代码Exception,以及含有Exception的日志 | 错误闭环 |
| 接口执行的北极星指标 | 延时闭环 |
| 接口执行的日志 | 故障佐证 |
| 接口执行的trace | 故障佐证 |
| 接口所依赖的容器环境关键事件 | 环境影响 |
APO介绍:
国内开源首个 OpenTelemetry 结合 eBPF 的向导式可观测性产品
apo.kindlingx.com