可观测性工具的盲区与故障排查困局
云原生常见可观测性工具的用法
Tracing
Tracing 可以追踪一次用户的请求,从而大致定位问题节点。如果运气好,是可以直接呈现某段代码的问题,比如问题就是SQL语句慢,或者执行了非常多次的redis操作导致整个请求慢,但是仍然有很多的时候只呈现了 Controller 方法执行时间长。
Logging
如果请求出现错误,在整个 Logging 体系中搜索错误日志是很快能够定位出错误的原因的,但是如果是请求发生了慢的现象,就得结合 Tracing。Tracing 基本定位到某个Controller 的问题,日志提供进一步的问题,排查到底是为什么慢,能否排查出问题取决于日志记录完备情况,所以经常出现的情况是补充日志进一步排查问题。
Metrics
通过 Metrics 中的SRE黄金指标能够很快确定业务是否正常,是否需要人为干预。但是一旦到某个业务慢,通过tracing和日志也没有发现直接线索,这个时候就只能通过 Metrics 找到有问题节点资源饱和度指标,看各种指标异常,不断地猜测试错验证了。
这里面存在两个大的问题:工具集成性差和盲区导致排障困难
集成性差是工程性问题,是次要问题
根据前文提到 Tracing、Logging、Metrics 工具在不同场景下使用,在不同工具之间跳转很麻烦会导致排查故障效率不高,但这是个工程问题,很多开源项目都在致力于解决这个问题。比如 OpenTelemetry 社区就致力于解决这个问题,会将三者从不同的线头糅合成一个线头,包括很多商业工具也都在界面跳转等易用性上发力,这个问题终将能够解决。

盲区是理论问题,是主要问题
盲区从理论上分析就存在的,不管是何种可观测性工具都没有办法完全还原程序的执行过程。Tracing 理论上就不可能针对每行代码执行都做插桩,因为会导致程序的执行性能下降很快。 Skywalking 有 trace-profiling 技术,目标就是动态探测某个程序在干什么,这个有一定的价值,能够发现用户代码层面的盲区。
国内使用很广泛的 Arthas 也是起着类似的作用,就是发现用户代码层面的盲区。国外一些在线debug工具,lightingRun 等工具也是往这个目标努力。
用户代码盲区并不意味着真实的程序执行盲区
程序执行过程是用户代码调用公共库、公共库调用JVM虚拟机代码、然后触发glibc库,最终触发syscall。
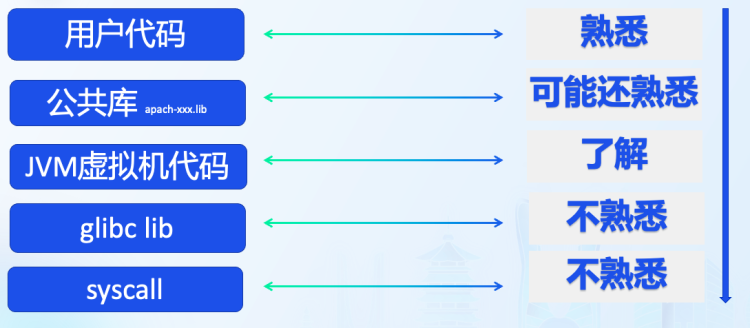
现有工具理论上也只是工作在用户代码和公开库之上来帮助用户理解程序执行过程。
打开用户代码盲区之后仍然存在哪些可能的盲区
-
用户在代码层执行一次带域名的http请求,实际在glibc中会分成两次网络请求,一次是获得dns解析,一次是真实的网络请求。用户代码层面无法理解到底是如何执行的。
-
程序执行过程中,由于CPU时间片使用完,无法获得CPU执行,用户代码层面会将等待CPU时间片执行时间算成代码执行时间
-
隐藏锁的使用,前文介绍了用户代码不可能对每行代码都做插桩,这样就会导致某些代码执行过程中可能在调用过程中使用了锁,但是对于用户而言是完全无意识的。典型就是Java常用的池化技术,连接池、线程池都是用锁来确保逻辑的正确执行。
-
背锅的网络质量,用户代码调用网络发送代码,网络数据真的发送出去了吗?程序这个时候如果执行了GC操作或者CPU时间片用完了呢?从用户代码和日志层面看出应该是发出网络数据了,但是中间可能存在各种原因导致网络数据发送是滞后的,开发人员会倾向于认为网络质量有问题,但是网络运维人员发现不了网络质量问题。
如何才能在理论上真实还原程序执行过程,打开所有盲区
学习过操作系统的同学稍微回忆下基础知识,从操作系统层面看程序的执行过程,才是程序的真实执行过程,这里面是没有任何遗漏的。重点回忆下图。
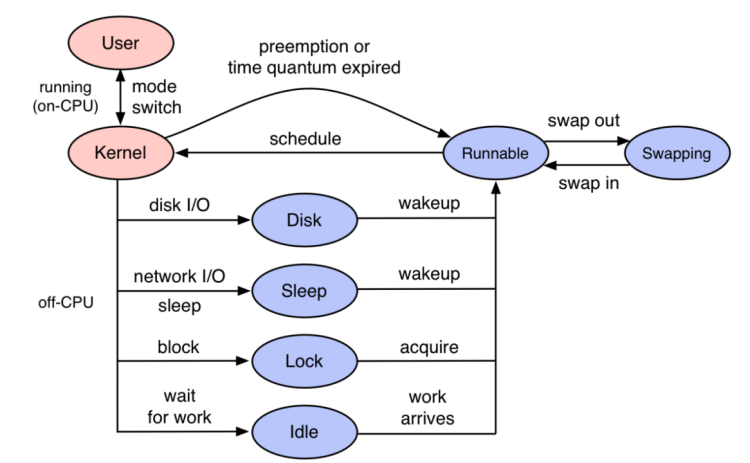 程序代码是以线程为载体进行执行,线程执行过程中可能会因为disk、sleep、lock、idle等各种原因放弃CPU上执行转入等待状态。
等待事件完成之后,线程状态变成Runnale等待cpu调度,如果此时CPU资源紧张,就会出现很长的等待时间。
开源项目 Kindling 的 trace-profiling 就是利用eBPF获取各个点位信息,同时结合Trace,真实地还原出程序的执行过程。从 Kindling 的 trace-profiling 去看trace的完整执行过程,每一个毫秒都知道程序在干什么。
程序代码是以线程为载体进行执行,线程执行过程中可能会因为disk、sleep、lock、idle等各种原因放弃CPU上执行转入等待状态。
等待事件完成之后,线程状态变成Runnale等待cpu调度,如果此时CPU资源紧张,就会出现很长的等待时间。
开源项目 Kindling 的 trace-profiling 就是利用eBPF获取各个点位信息,同时结合Trace,真实地还原出程序的执行过程。从 Kindling 的 trace-profiling 去看trace的完整执行过程,每一个毫秒都知道程序在干什么。
Kindling-OriginX 利用trace-profiling理念构建故障推理引擎
Kindling-OriginX 相比于 Kindling 开源探针而言,使用Rust语言完全重构了eBPF探针。主要目的是获得更好的性能和稳定性。Kindling 开源探针使用go语言,由于go gc的存在,导致内存资源消耗相对而言比较大,而且go gc的时间不可控。 Kindling-OriginX 商业产品定位为故障推理引擎,通过分析各种开源工具的数据,补充 trace-profiling 的指标,比如通过 trace-profiling 已经能够看出网络执行慢了,这个时候通过补充网络质量指标如RTT、重传等进一步确认网络到底为什么慢。
Kindling-OriginX 完美解决集成性问题,同时彻底消除所有盲区
Kindling-OriginX 的故障报告中,完成了相关指标,日志和tracing的完美集成,只呈现用户需要看的故障传播链路分支和指标,旁路无关分支和故障不相干指标也不会呈现,日志也是故障时刻前后的相关节点日志。同时利用 eBPF 结合 trace-profiling 技术打开程序执行和系统调用盲区,从根本上彻底还原程序执行过程。 故障推理引擎利用智能算法结合 trace-profiling 自动化推导出故障根因,想更多了解 Kindling-OriginX,请点击阅读原文访问 Kindling-OriginX 官方网站。