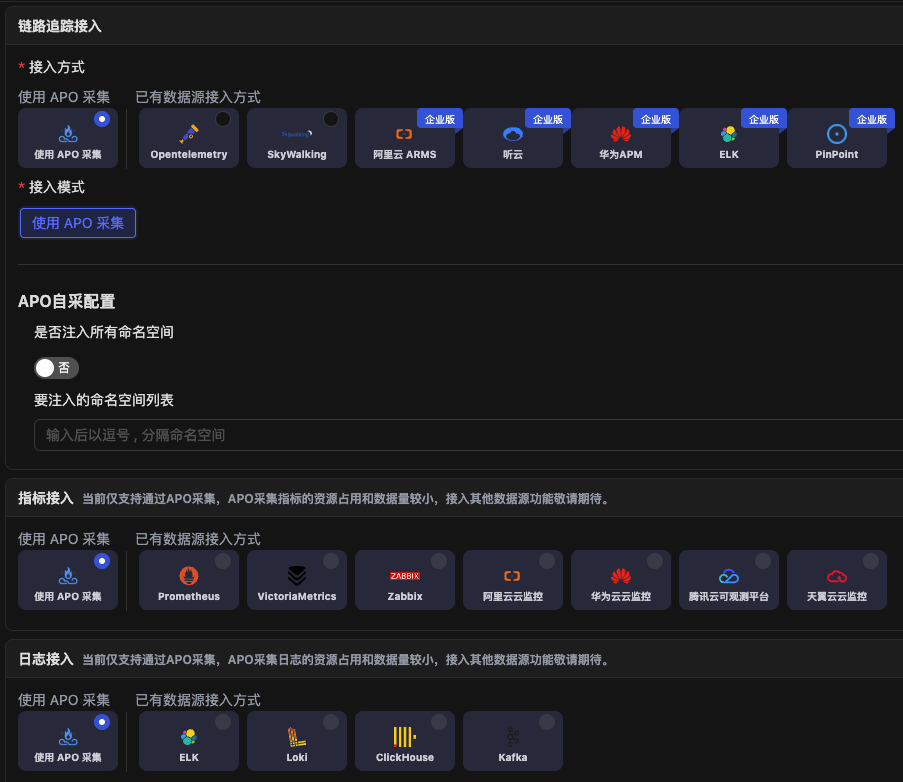
棘手的级联故障
已经使用很多可观测性工具,排障为什么仍然难?
在 Google 提出的SRE理念中,依据运维黄金指标是容易判断业务正常与否的,但是业务异常了,如何找到根因却是当前比较艰难的任务。
对于为什么排障难,不同角度能够得到不同的结论。本文主要从技术角度来谈谈为什么排障这么难?
各种可观测性工具 Traces、Metrics、Logging 的使用对于排查简单的问题确实比较有用,依据专家经验是能够做到快速排除故障的。
现在比较棘手的难题是出现一些级联的故障,也就是当业务出现异常的时候,各种异于平常的指标告警很多,即便在专家在场的情况下,依次排查每个告警仍然需要消耗非常多的时间。特别是在现代服务系统架构中,拓扑结构复杂,各服务间互相依赖,同时系统中存在着各类中间件,这些都使得大型业务系统中的故障往往都表现为级联故障,而且更加难以快速定位排障,在这种情况下,想要落地 1-5-10 是非常难的。
传统运维观念中为什么要设置不同种类的告警?
很多告警都是在踩坑中得到的经验教训,当业务异常之时,如果没有告警也就没有线索,不知道该往哪个方向排查。所以在传统排障理念中,告警提供了排障线索。
随着业务复杂化,踩得坑越来越多,告警规则以及各种类型的告警也变得越来越多。 在这种前提发展之下,实际生产中就会陷入左右为难的困境,不设置告警就没有了线索,或者缺失线索。但是告警过多又会带来很多干扰,产生告警风暴、埋没根因等问题,同时在一定程度上也会导致 OnCall 人员麻痹大意。那么这种困境该如何解决呢,是不是存在更加科学有效的方法?
Kindling-OriginX 创新提出仅仅依赖API SLO违约告警
SLO 违约告警其本质是依赖于 Google 提出的运维黄金指标来判断业务是否正常,如果业务不正常了,SLO 也就产生违约了。 Kindling-OriginX 能够不依赖于其它的告警,是因为 Kindling-OriginX 认为不管何种故障,最终都会影响到业务体验上,例如用户的访问请求等。如果任何业务都没有受有影响,即任意访问请求都没有变慢也没有出现任何错误和异常,那这个故障为什么能称之为故障呢?Kindling-OriginX 的核心能力是针对每次请求的故障trace,能够直接给出故障根因报告,在这种能力加持下,也就可以不用配置种类繁多的告警了。
面对棘手的级联故障,Kindling-OriginX 如何处理
面对棘手的级联故障,从本质来讲其实有两种优化手段
- 通过算法判断出故障线索之间的潜在依赖关系,从而找到故障的根因,这也是传统 AIOps 的思路。
- 重新组织故障线索,加快每个故障线索的分析,一分钟将所有故障线索都分析出结论。
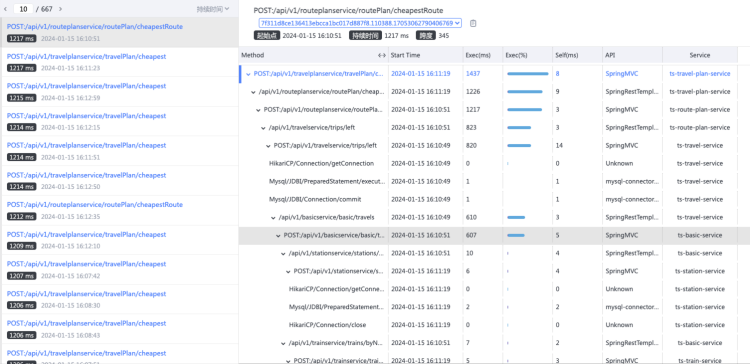
Kindling-OriginX 选择了第二种方式来解决棘手的级联故障,通过trace来组织故障线索,每个故障trace都直接给出当前故障trace根因报告。
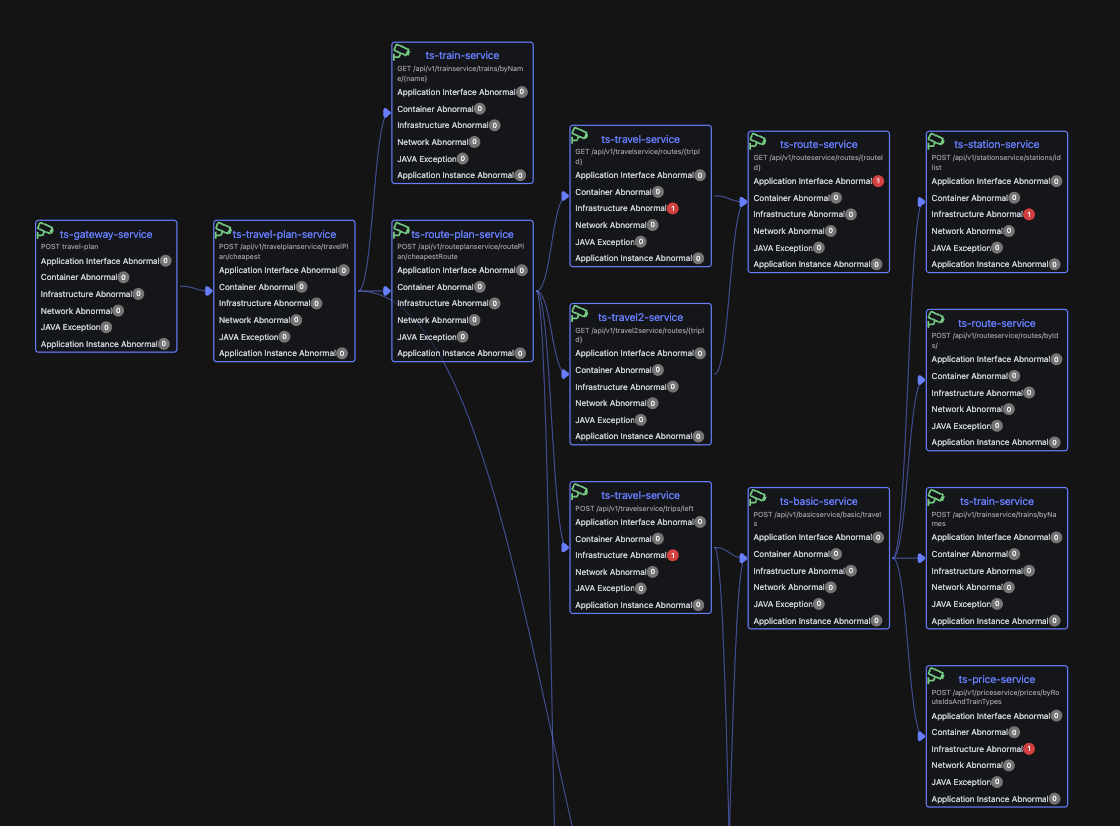
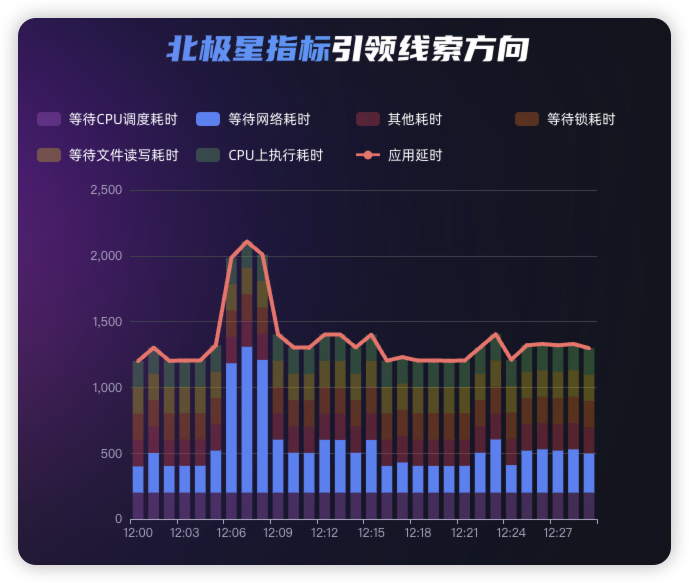
为了能够说明问题,这里以 soma-chaos 案例为例,通过注入一个网络故障后整个业务系统的变化分步作一具体说明。
- 对 routes service 注入网络故障。
- routes service 响应变慢。
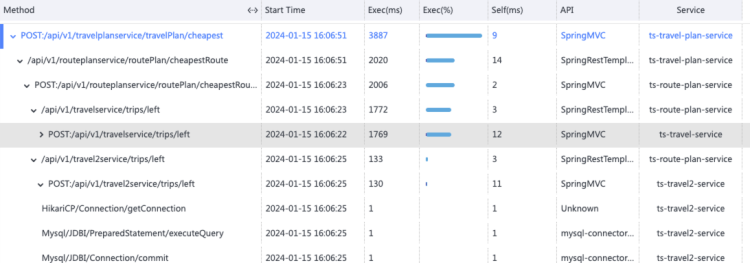
- travel service 响应变慢,且比 routes service 更慢
- 初步走查发现大量请求在 travel service 处等待。
通过对故障现场的初步分析,我们可以得到两个线索
- travel service 响应变慢,同时大部分请求在等待
- routes service 响应变慢
通过对故障现场的数据观察和简单分析,得到了两个线索,但仍旧处于无从下手的阶段,往往需要更多的数据进行分析,或者需要有更丰富排障经验的专家来提供思路和排查方向。下面再看看 Kindling-OriginX 的解决方法。
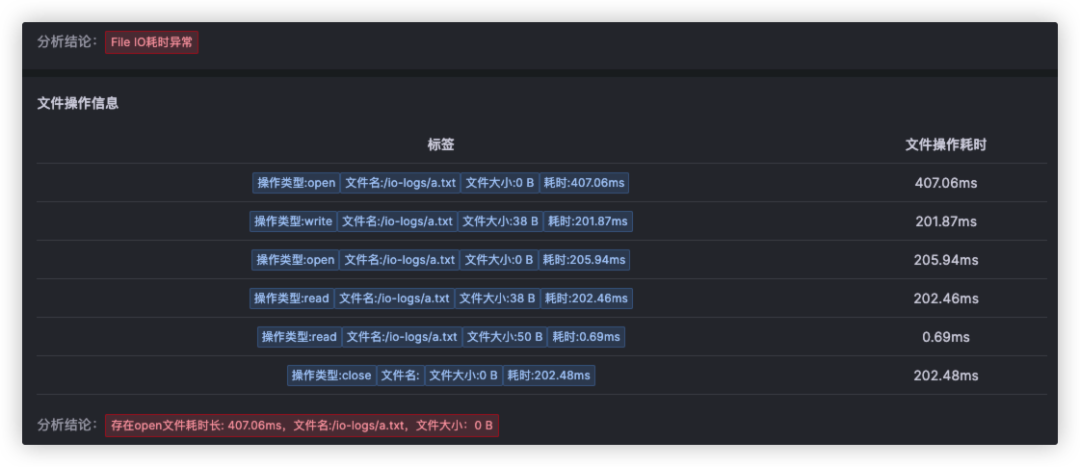
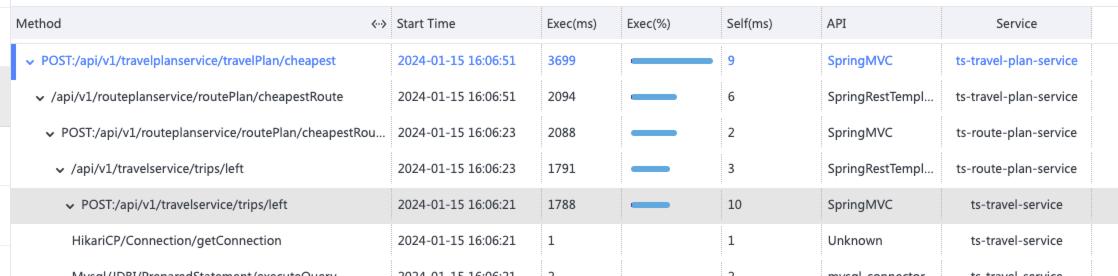
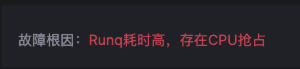
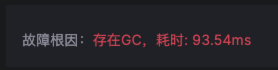
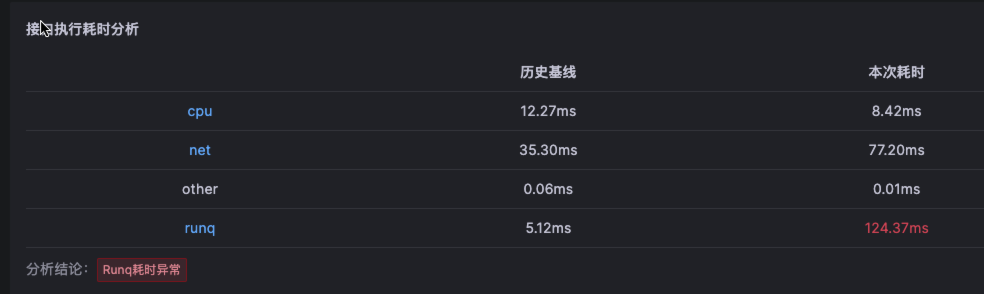
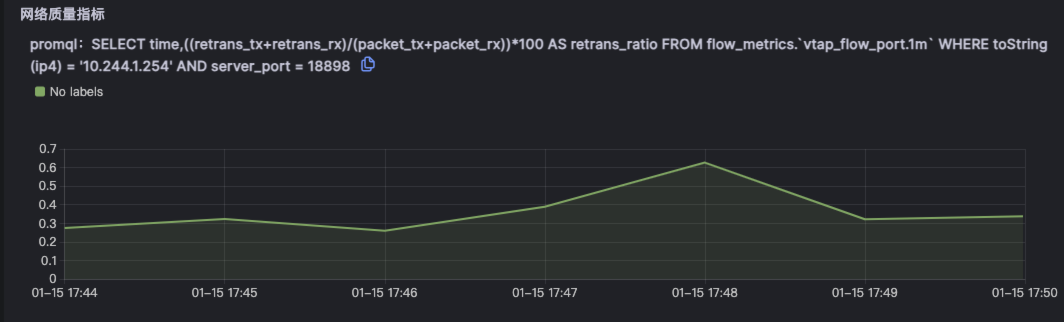
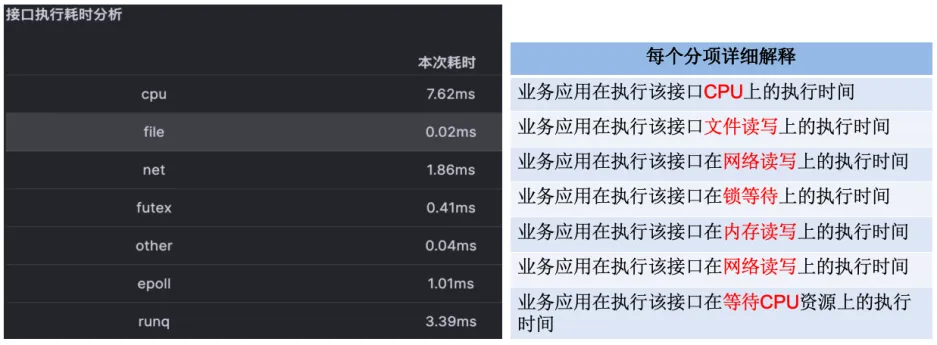
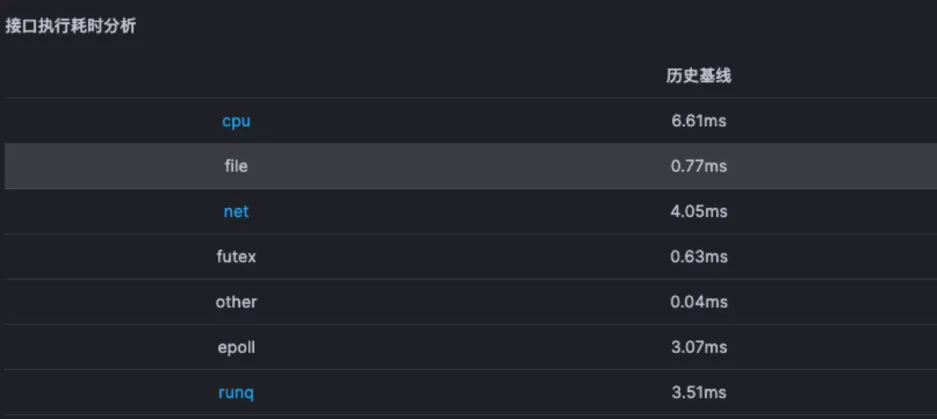
对于这个故障,Kindling-OriginX 对于 travel service 的慢请求和 routes service 的慢请求都会分别直接给出根因报告,travel service 慢的��根因是锁的时间很长,routes service 慢的根因是网络故障。
接下来不用再花费精力分析为什么 travel service 慢以及 routes service 慢,因为每个线索都已经快速的拿到了结论。接下来只需要根据结论来进行方案的研判或启动对应的应急预案即可以最快的速度进行业务的恢复。
在传统的排障方法中,很可能处置人员的注意力会被 travel service 的锁故障分散,甚至认为可能是根因,从而花费大量的时间和精力来分析和处理 travel service 的故障,但是却又不能精准快速定位,只能通过重启扩容等方案来进行穷举,浪费大量人力物力却也没能使业务快速回复。
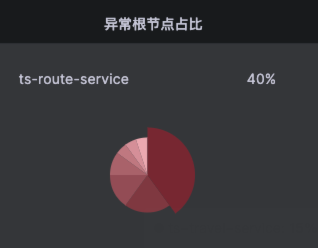
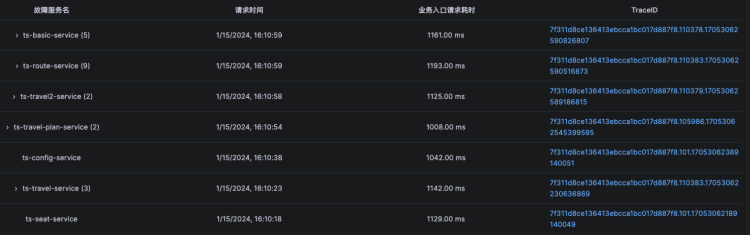
Kindling-OriginX 通过对每个故障节点都直接快速给出结论,在排查级联故障之时,只需要遵循以下原则即可:
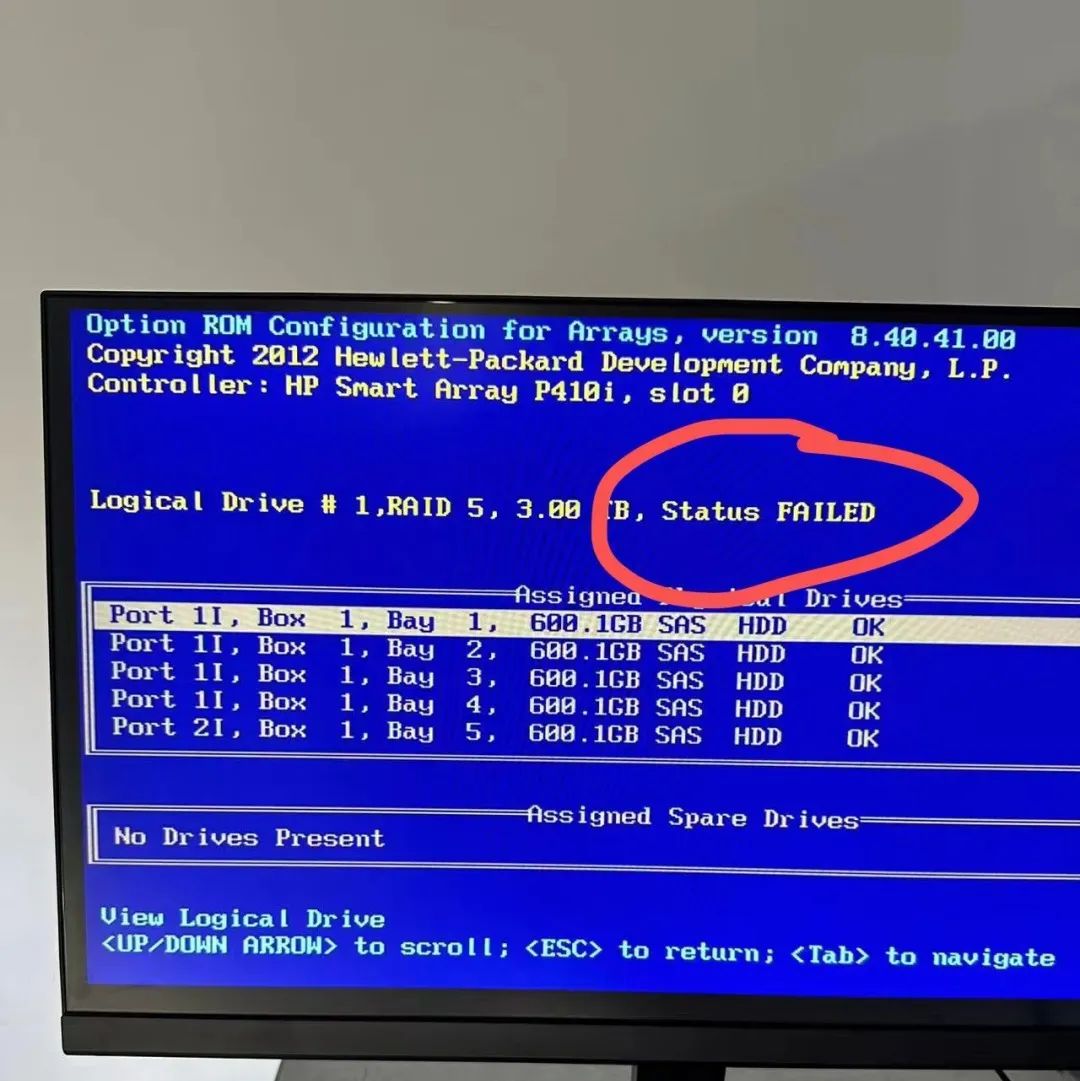
- 被依赖的故障根因节点和基础设施故障(CPU、网络、存储)优先解决
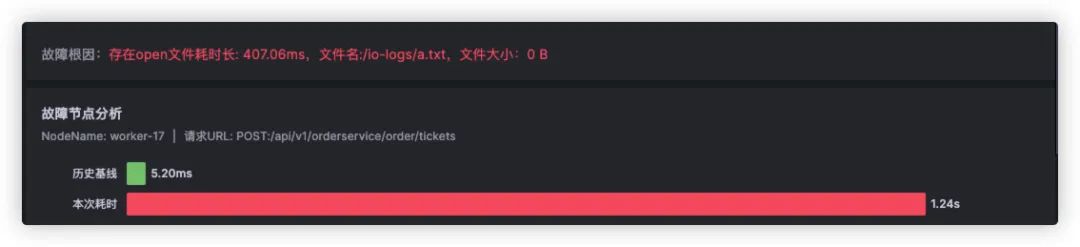
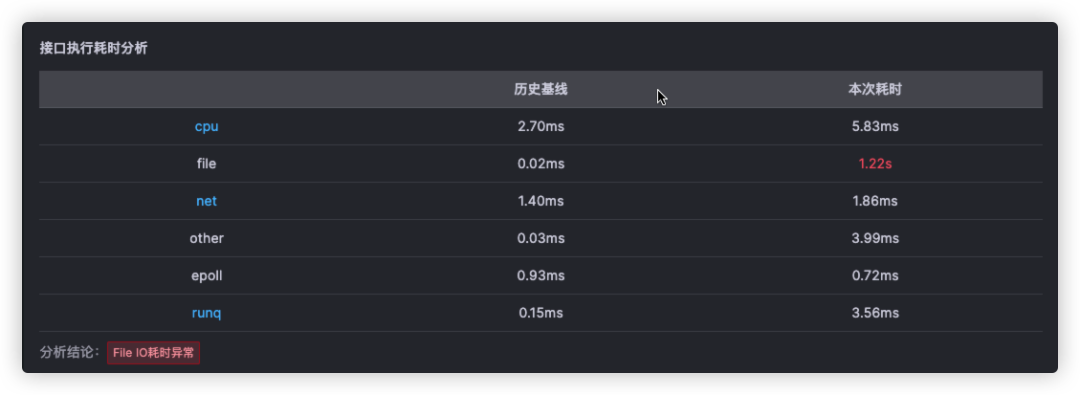









 Kindling-OriginX 提供了一种新的处理级联故障的思路和方法,快速组织和分析故障线索,给出根因报告,并根据优先级原则进行故障处理。这种方法可以加速故障定位,避免级联故障中排查方向错误,同时能够以标准化的流程进行级联故障的排查,真正的有机会去在实践中落地 1-5-10 故障响应机制。
Kindling-OriginX 提供了一种新的处理级联故障的思路和方法,快速组织和分析故障线索,给出根因报告,并根据优先级原则进行故障处理。这种方法可以加速故障定位,避免级联故障中排查方向错误,同时能够以标准化的流程进行级联故障的排查,真正的有机会去在实践中落地 1-5-10 故障响应机制。




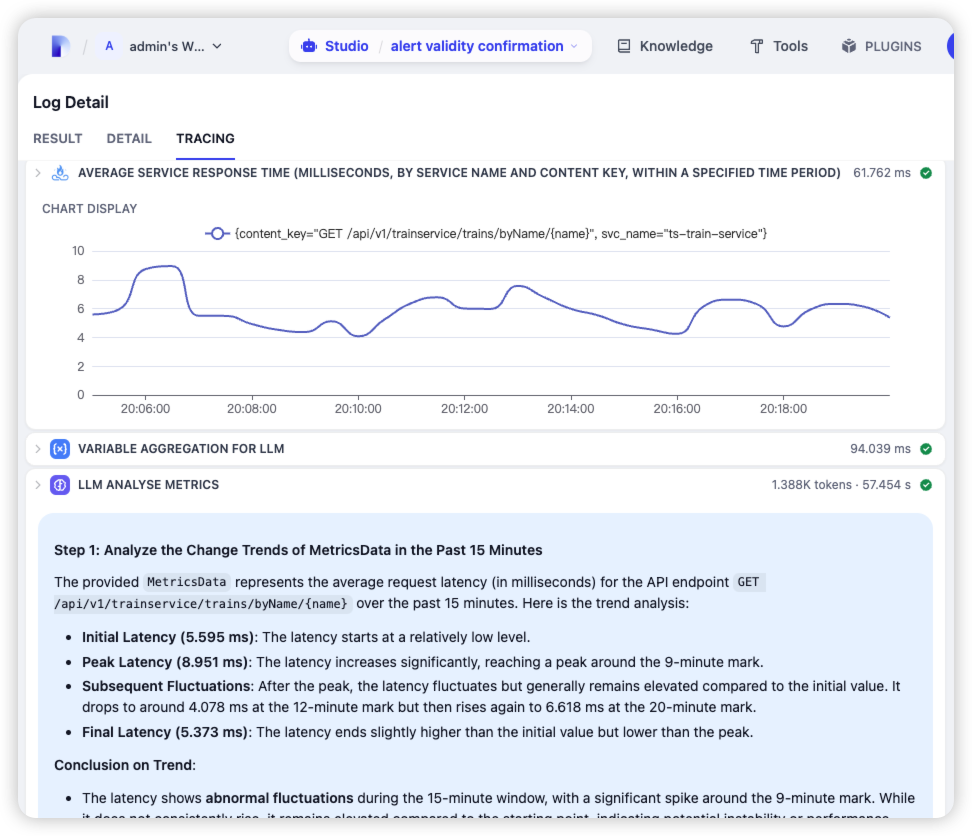






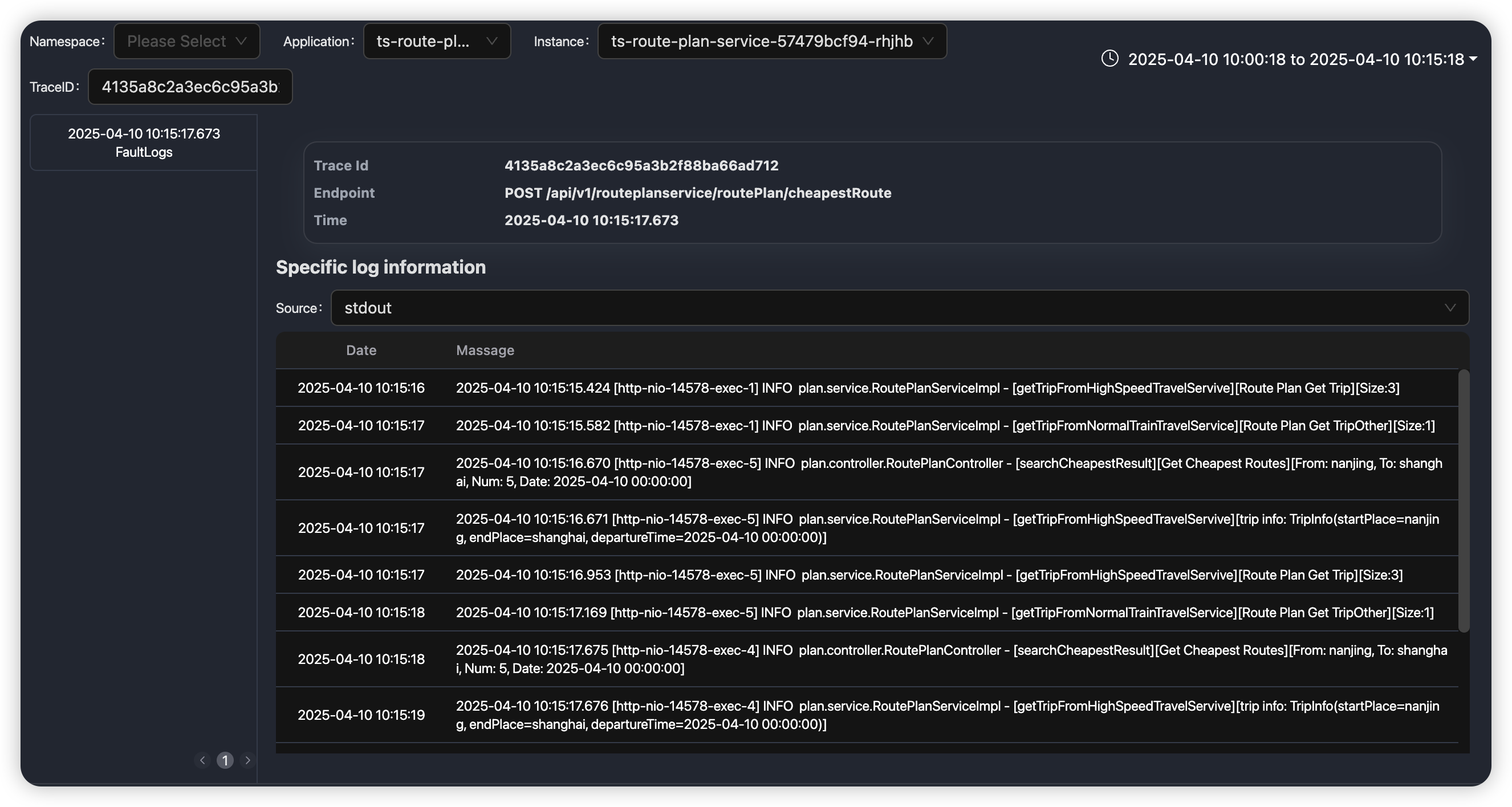
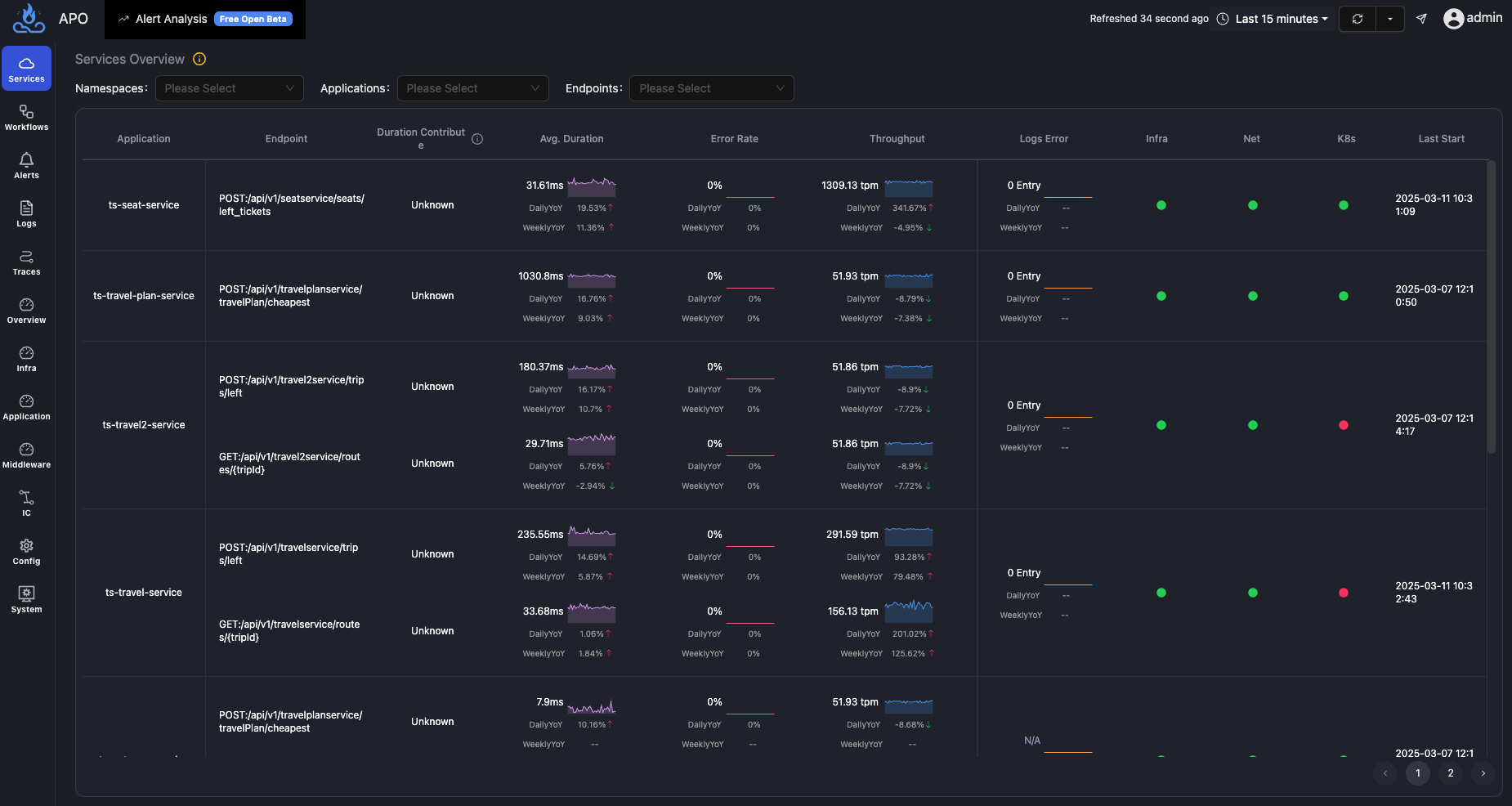


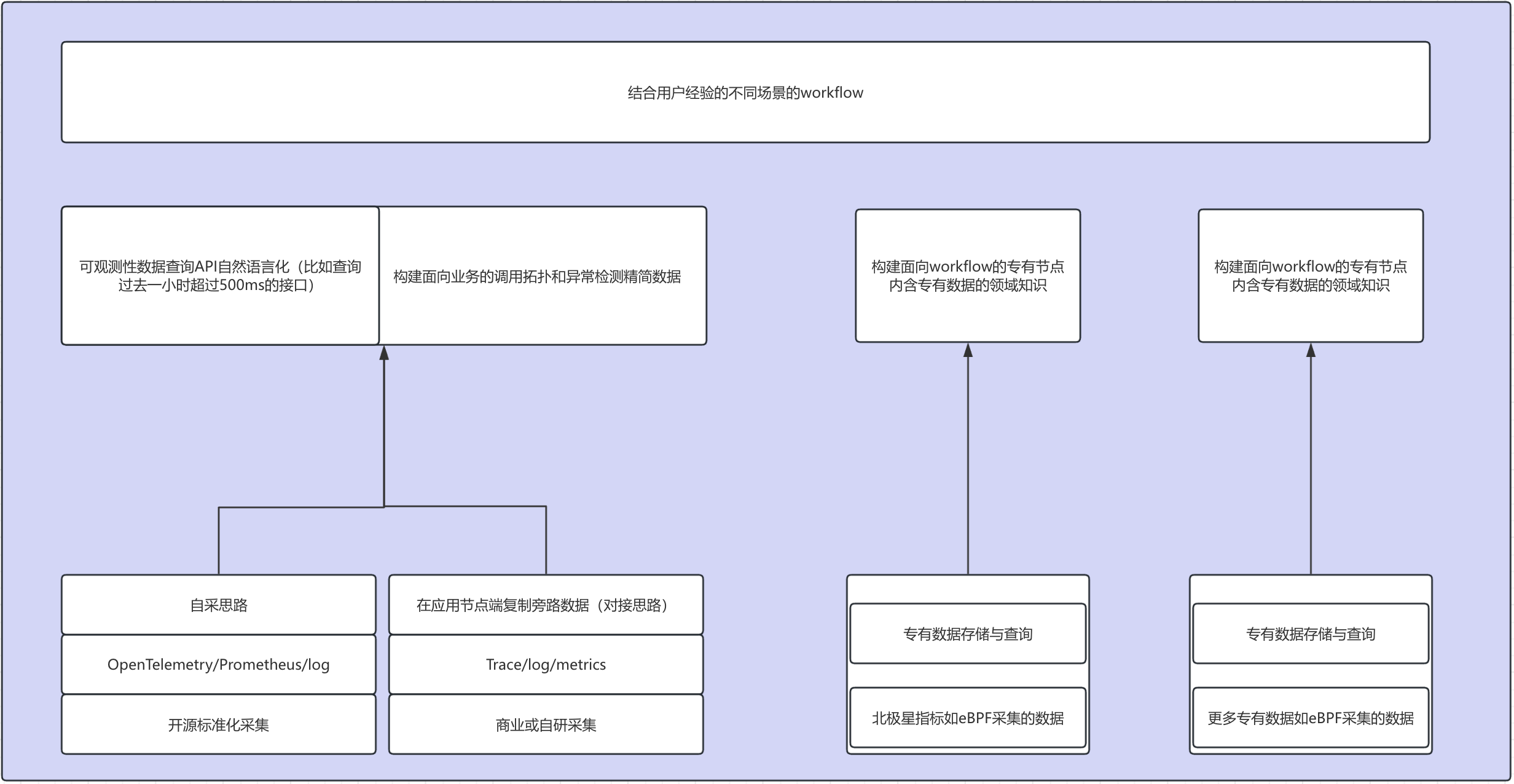
 未来完全自治的智能体
未来完全自治的智能体 开箱即用的面向问题解决的Agentic workflow
开箱即用的面向问题解决的Agentic workflow 基于Dify专为可观测性领域打造的平台
基于Dify专为可观测性领域打造的平台