可观测性体系建设后,该如何挖掘数据及工具价值?

在现代企业的运维管理中,构建高效且可靠的可观测性体系是保障系统稳定性和业务连续性的关键。然而,运维团队成员的技术能力参差不齐往往成为实现这一目标的障碍。尤其在处理复杂系统故障时,高度依赖专业知识和经验的可观测性工具很难被全员有效利用,进而影响到其建设价值的体现。

可观测体系建设的意义

可观测性是近几年来最热门的话题之一,许多企业和团队都投入了很多人力、物力来进行可观测体系的建设,以期能获得可观测性的核心价值:快速排障(troubleshooting)。可观测性体系是指通过一系列技术手段和方法,对系统的运行状�态、性能指标、业务流程等进行实时监控、分析、预警和优化的一种体系。它可以帮助企业及时发现和解决问题,提高运维效率,降低故障风险,为业务发展提供有力支持。
1. 提高运维效率
通过实时监控云原生应用的运行状态,运维人员可以快速发现并解决问题,减少故障排除时间,提高运维效率。
2. 保障系统稳定性
可观测性体系可以帮助开发者及时了解应用在云环境中的表现,发现并修复潜在的性能瓶颈和错误,从而保障系统的稳定性。
3. 优化资源利用率
通过收集应用的性能数据,可以对资源的使用情况进行分析,实现资源的合理分配和优化利用。
4. 持续迭代与优化
可观测性体系建设和数据挖掘是一个持续的过程。企业应不断收集反馈,优化体系架构和数据处理方法,实现体系的持续迭代和提升。同时,关注行业新技术、新理念的发展,将先进经验融入自身建设中,保持体系的竞争力。
可观测体系建设完成后存在的问题和挑战

很多团队在完成了一定规模的可观测性体系建设后,却在具体落地推广,乃至实际价值体现上都遇到了阻碍,这些问题和挑战主要体现在两方面,管理层面与技术层面:
管理层面的挑战
技术能力的不均衡
团队内技能水平的差异导致高级工具和数据的利用率低下。可观测性体系建设完成后,需要将其向各相关团队推广,期望能帮助各团队提效,协助开发团队排查定位问题。
但实际情况下,往往把可观测工具提供给开发团队后,一方面业务开发团队使用工具存在学习使用成本,另一方面不是所有开发都有能力看懂和定位问题。这需要有平台或工具提供整合能力,来解决人员能力差异性。
经验知识难以传递
缺乏有效的机制将高级用户的经验和知识快速传递给新手或非专家用户。导致仍旧是依靠团队专家和骨干才能完成诸如故障排查等工作,团队内部长期存在差异性。
故障响应的差异性
在发生故障时,需要快速有效的响应,但技术水平不一致可能导致延迟处置,甚至处置结果不一致,这种差异性也导致不利于故障响应流程的标准化和故障处理手段的规范�化。
技术培训和能力提升存在成本
提升团队整体技术水平需要大量的时间和资源投入,且往往是一项需要长期坚持的工作,只有这样才能逐步对齐各团队间对于可观测性工具和数据的理解和使用水平。但仍旧会存在长时间不使用导致的生疏问题。
技术层面的挑战
工具使用和指标含义都会生疏遗忘
对于一些团队来说,可观测性工具并不是需要经常使用,加之其存在一定的学习成本,所以会导致每次使用的时候都得学习或者咨询专家。同理对于一直较深入的指标数据,其具体含义也会遗忘,使用的时候也需要查阅相关文档,这都加大的使用门槛。
使用方式和术语不统一
对于工具的使用和可观测数据的理解,不同团队都有其各自的使用场景和理解,这也导致了需要团队协作时增大了沟通成本,例如用户中心的团队使用Skywalking,负责消息推送的团队使用了OpenTelemetry。
故障响应的差异性
在发生故障时,需要快速有效的响应,但技术水平不一致可能导致延迟处置,甚至处置结果不一致,这种差异性也导致不利于故障响应流程的标准化和故障处理手段的规范化。
工具和标准的不统一
作为当今热门话题之一,各类可观测性工具及产品百花齐放,导致很多团队为了建设可观测性而不停的追热点,忙于工具的更新换代,方法和思路越没有同步进行更迭,更没有能够真正挖掘出可观测数据的价值。
需要更先进的工具和方法挖掘可观测性体系价值

Kindling-OriginX 通过Trace-profiling关键数据,以专家经验串联起来所有的可观测性数据,并推理成故障结论,最大程度发挥可观测性数据的价值。通过推理分析能力来平衡团队内的技术能力差异,确保每位团队成员都能有效利用可观测性数据,从而提升其建设价值的认可。
很多企业可观测性数据上了很多,但是推广效果不是很好,价值体现不佳。其主要原因是故障并不是经常发生,所以导致用户对于可观性工具使用生疏,加上一些疑难杂症的故障需要看深入的指标,这些指标含义不用就会忘记。这都需要有更先进的工具对数据指标进行提炼分析,直接给出可解释的结论。
-
简化的操作界面
为所有技术水平的用户提供易于理解和操作的界面,降低使用门槛。直接根据故障结论进行预案执行。
-
自动化智能故障推理
利用 eBPF 技术与自动化 Tracing 分析将多而杂的链路数据、指标数据、日志数据转化为直观的故障分析报告,无需深入的专业知识即可理解。
-
最大化可观测性数据价值
自动关联各类可观测性数据,完成可观测性数据价值挖掘。
-
内化的排障知识库
既是推理引擎,也是一个排障专家经验知识库,借助专家经验知识库平台能力能够迅速提升团队能力。
结语
本文探讨了可观测性体系的建设的意义及其根本目的,同时随着可观测性体系的建设也遇到了很多问题和挑战,对于这些问题和挑战都需要更先进的工具和方法,这样才能够充分挖掘和发挥可观测性工具和数据的价值。
在实践中,应当持续优化可观测性体系,确保数据的全面性�和准确性,同时不断提升数据处理和分析能力。这不仅需要技术的进步,更需要方法的革新,一方面将可观测性融入到我们的开发和运维文化中,另一方面通过使用诸如 Kindling-OriginX 的创新型工具里帮助快速提升对于可观测性数据的使用水平,帮助提高团队综合能力。

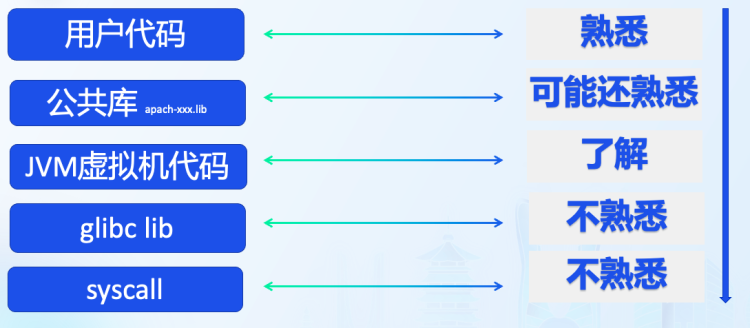
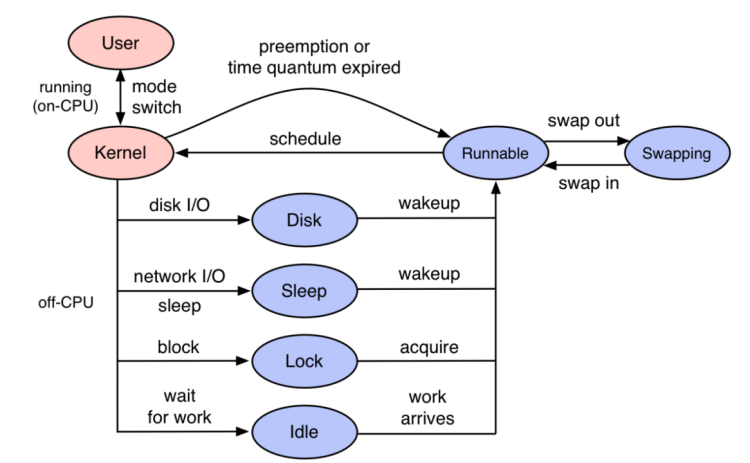 程序代码是以线程为载体进行执行,线程执行过程中可能会因为disk、sleep、lock、idle等各种原因放弃CPU上执行转入等待状态。
等待事件完成之后,线程状态变成Runnale等待cpu调度,如果此时CPU资源紧张,就会出现很长的等待时间。
开源项目 Kindling 的 trace-profiling 就是利用eBPF获取各个点位信息,同时结合Trace,真实地还原出程序的执行过程。从 Kindling 的 trace-profiling 去看trace的完整执行过程,每一个毫秒都知道程序在干什么。
程序代码是以线程为载体进行执行,线程执行过程中可能会因为disk、sleep、lock、idle等各种原因放弃CPU上执行转入等待状态。
等待事件完成之后,线程状态变成Runnale等待cpu调度,如果此时CPU资源紧张,就会出现很长的等待时间。
开源项目 Kindling 的 trace-profiling 就是利用eBPF获取各个点位信息,同时结合Trace,真实地还原出程序的执行过程。从 Kindling 的 trace-profiling 去看trace的完整执行过程,每一个毫秒都知道程序在干什么。
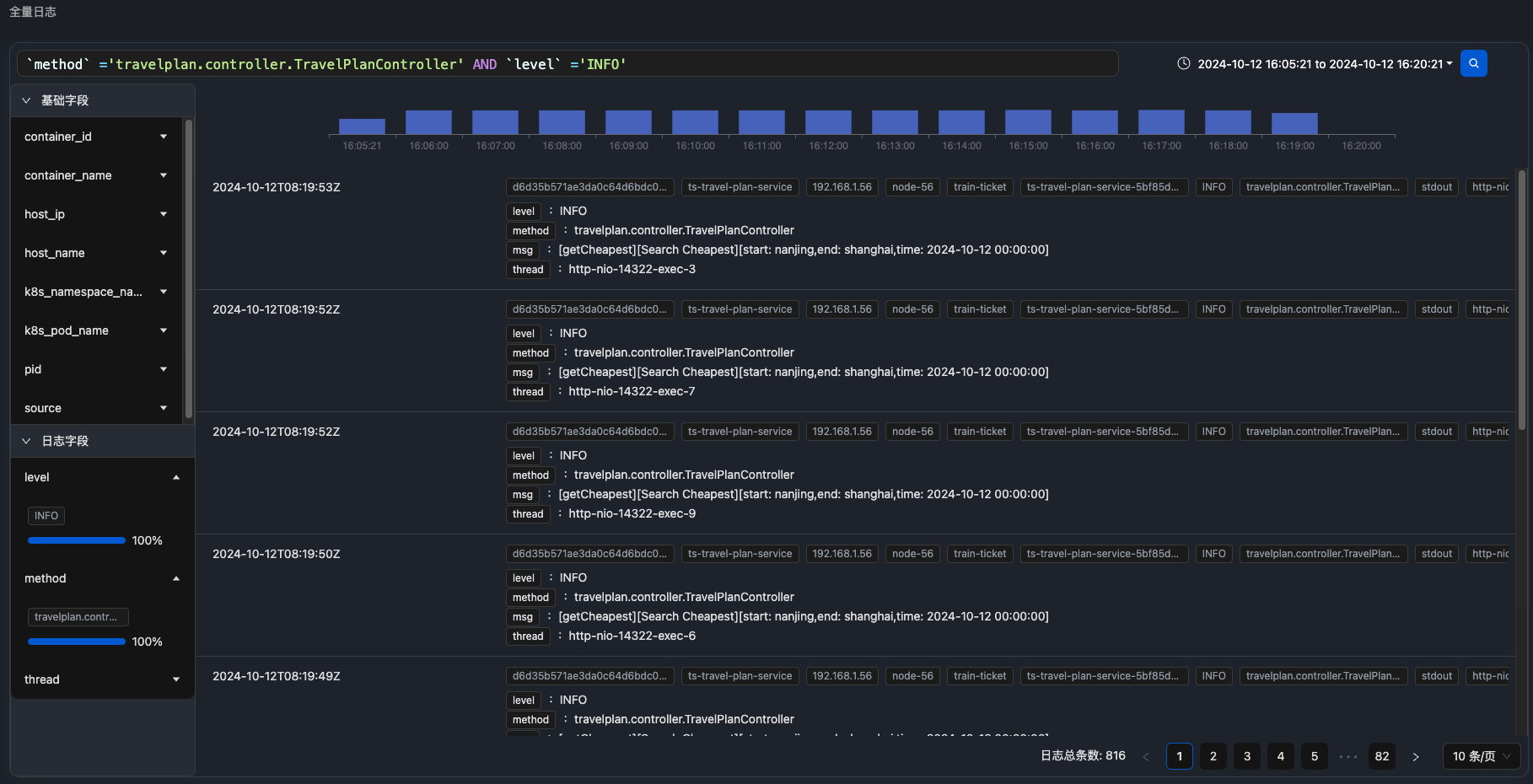



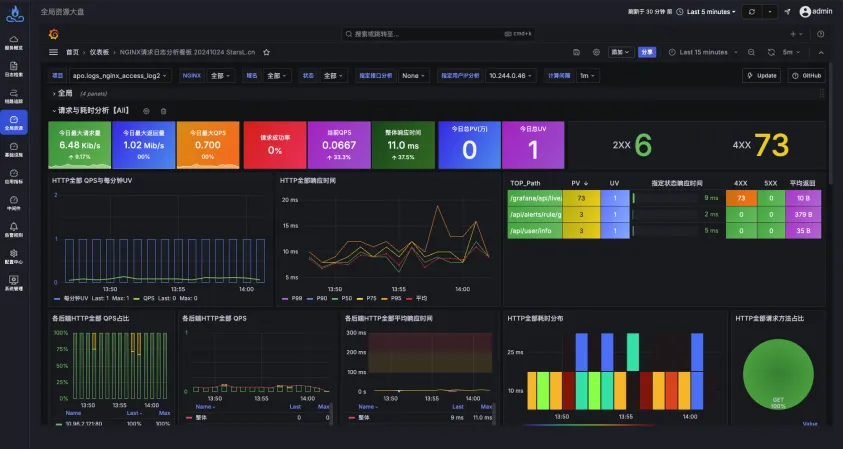
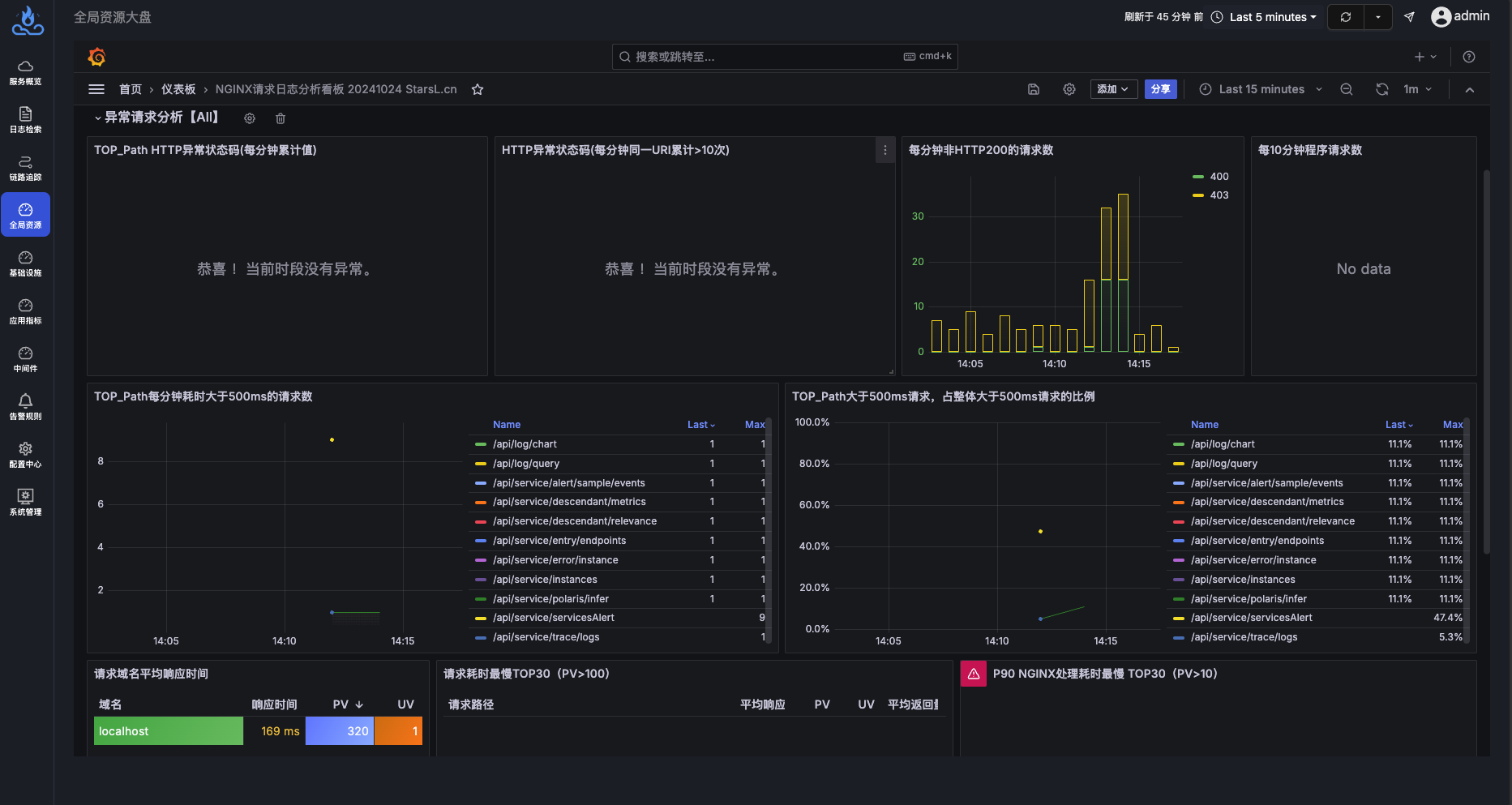
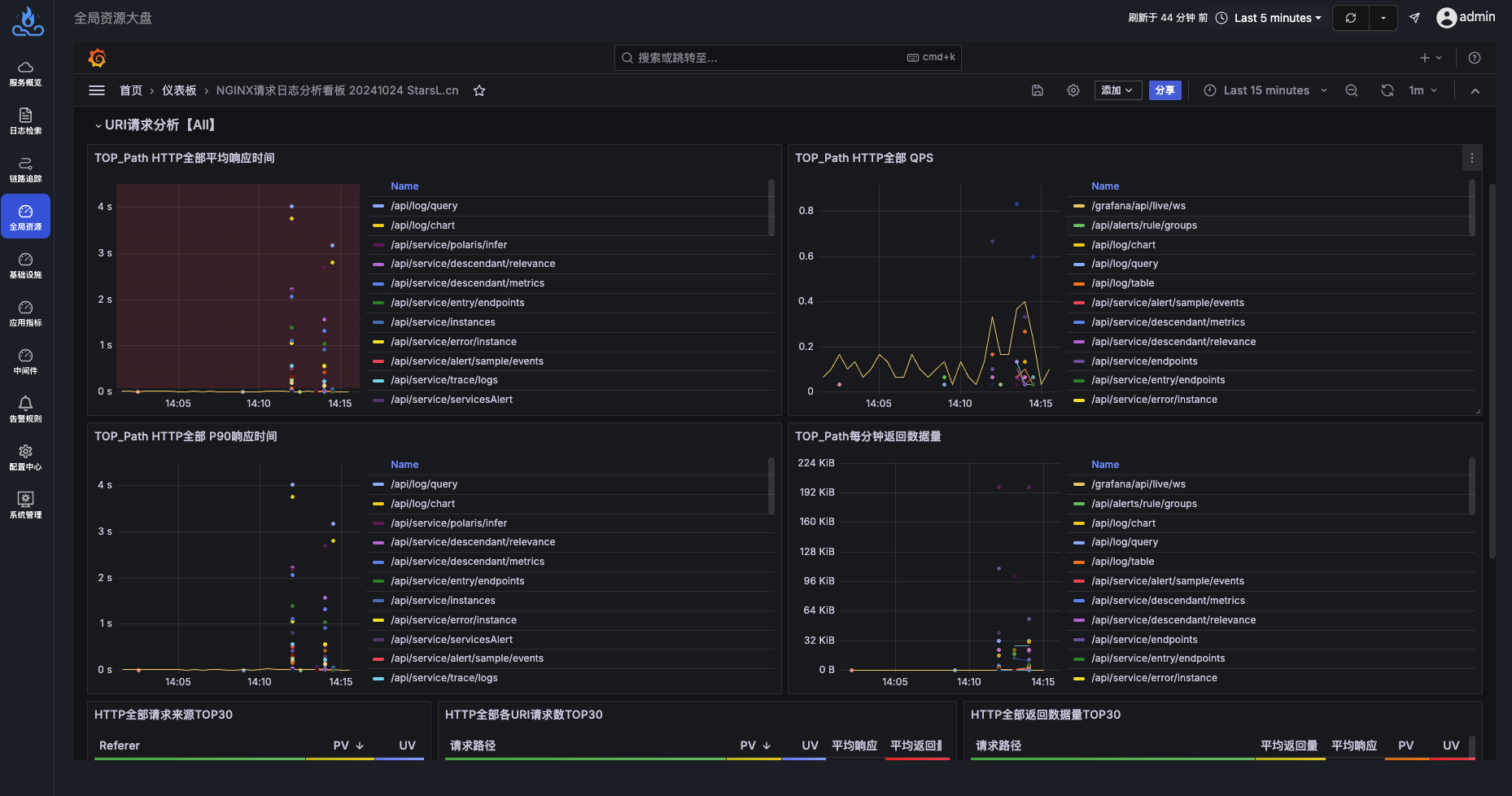
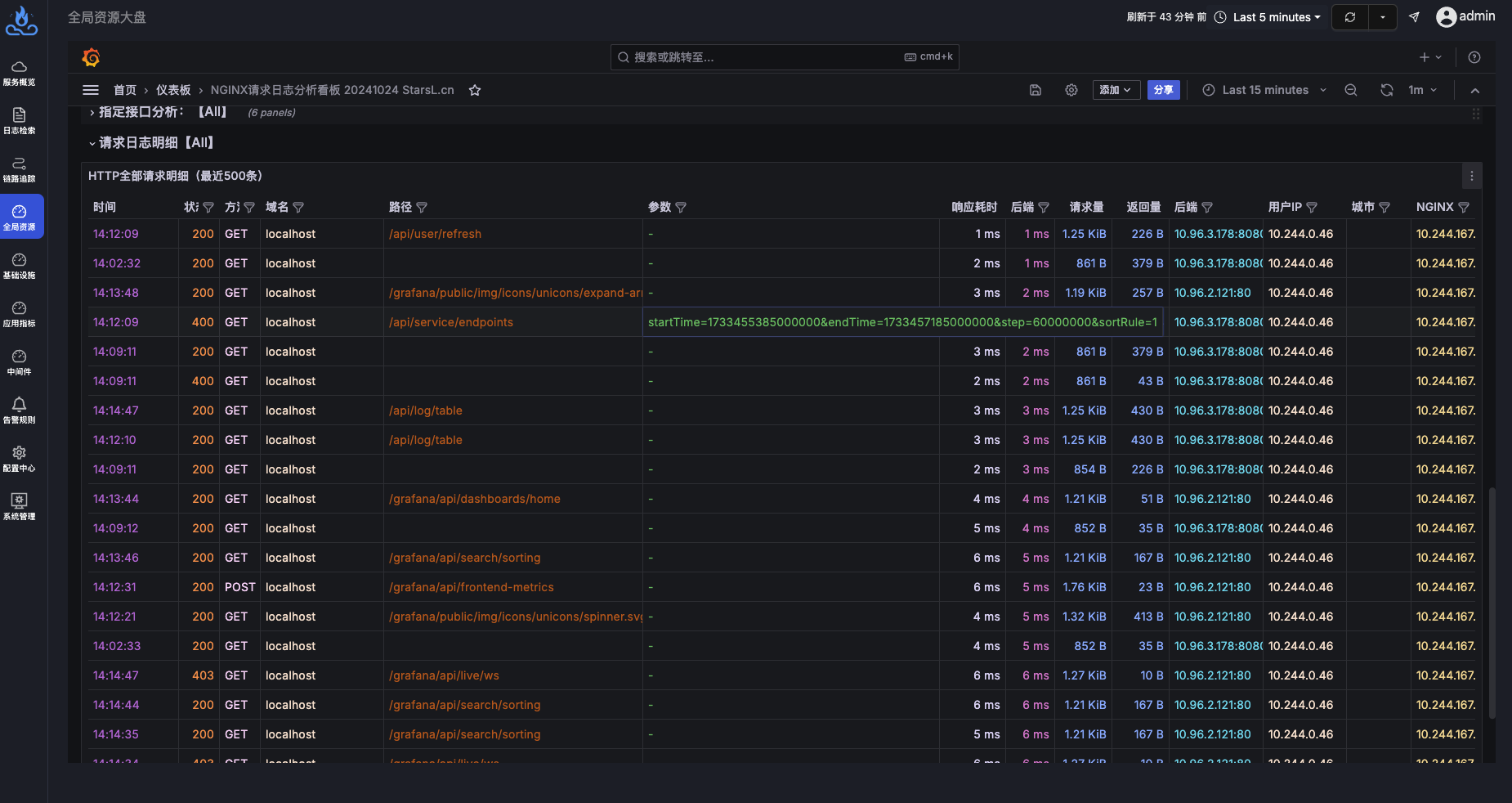

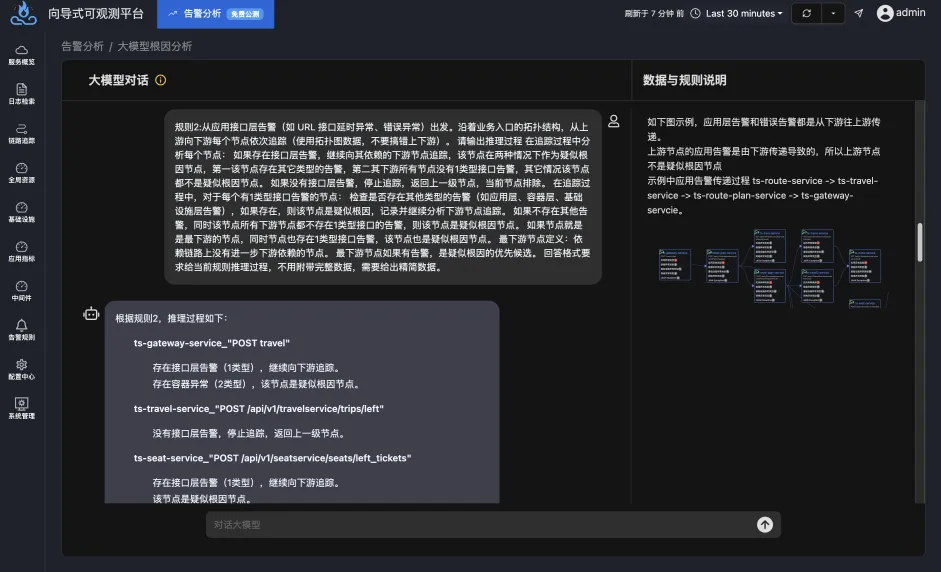



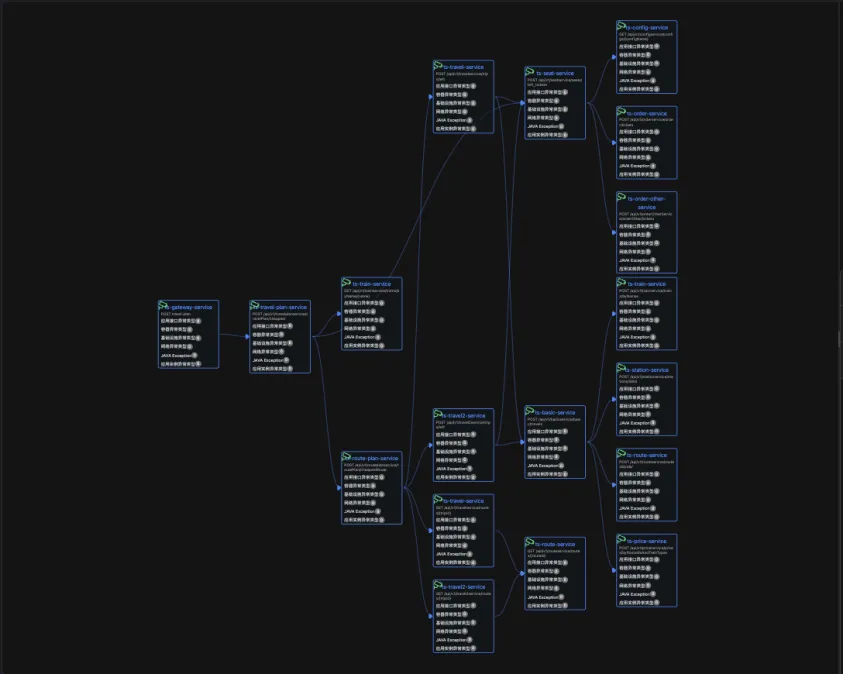
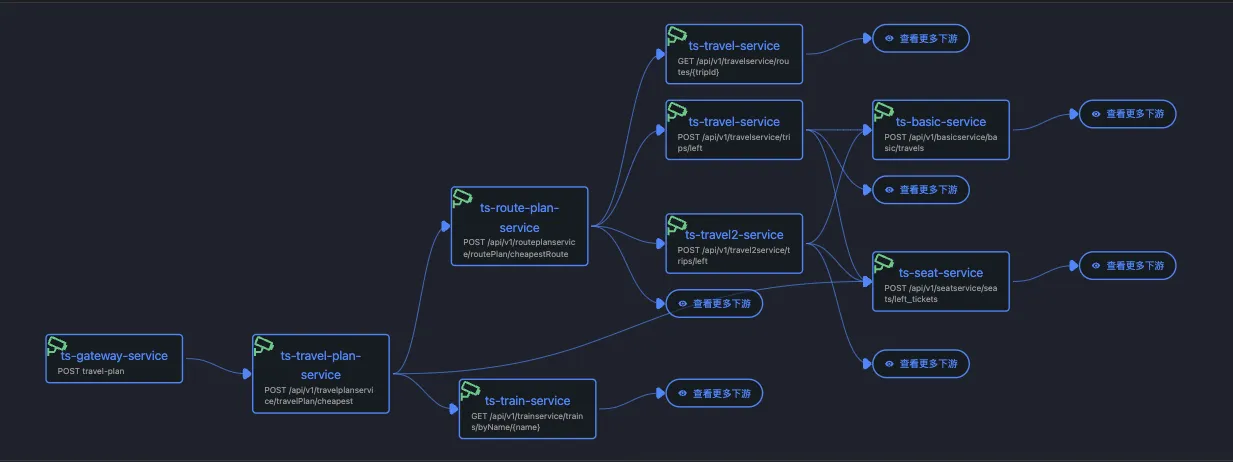


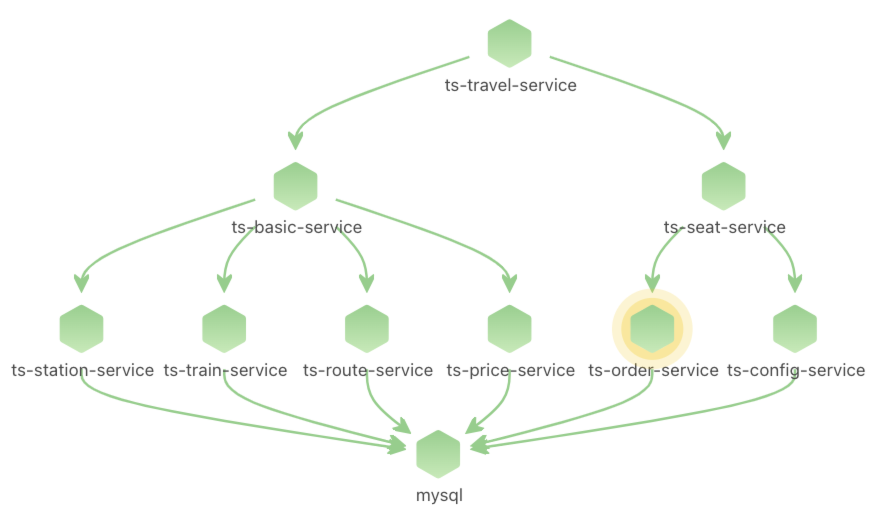
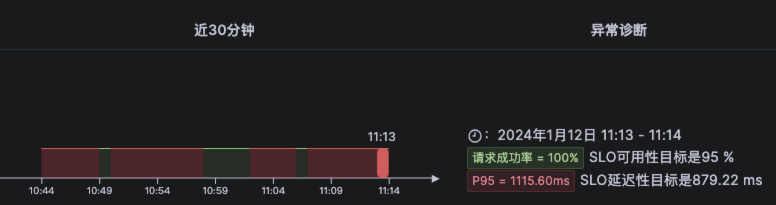
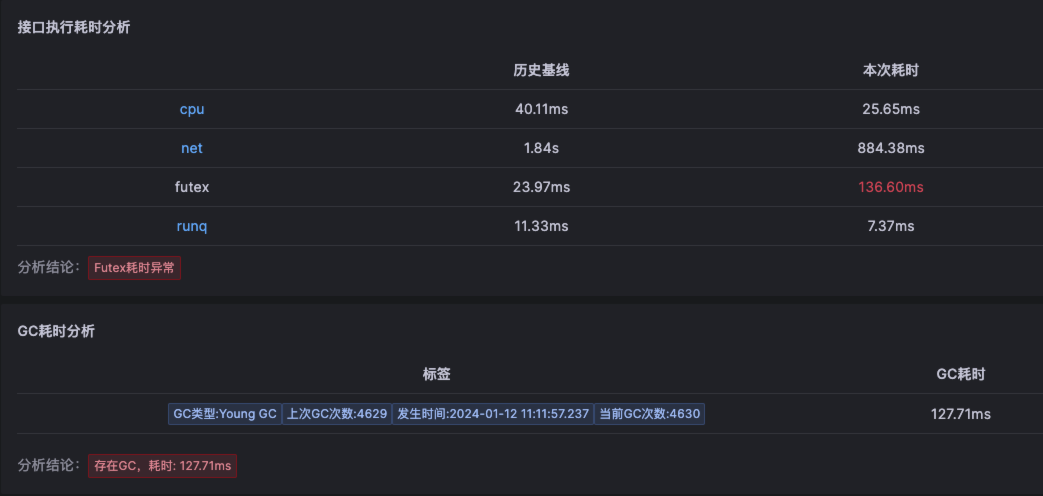
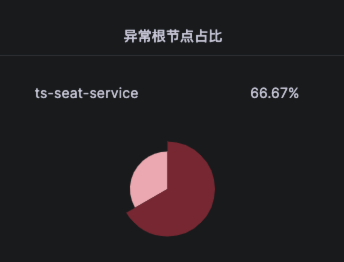

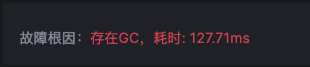








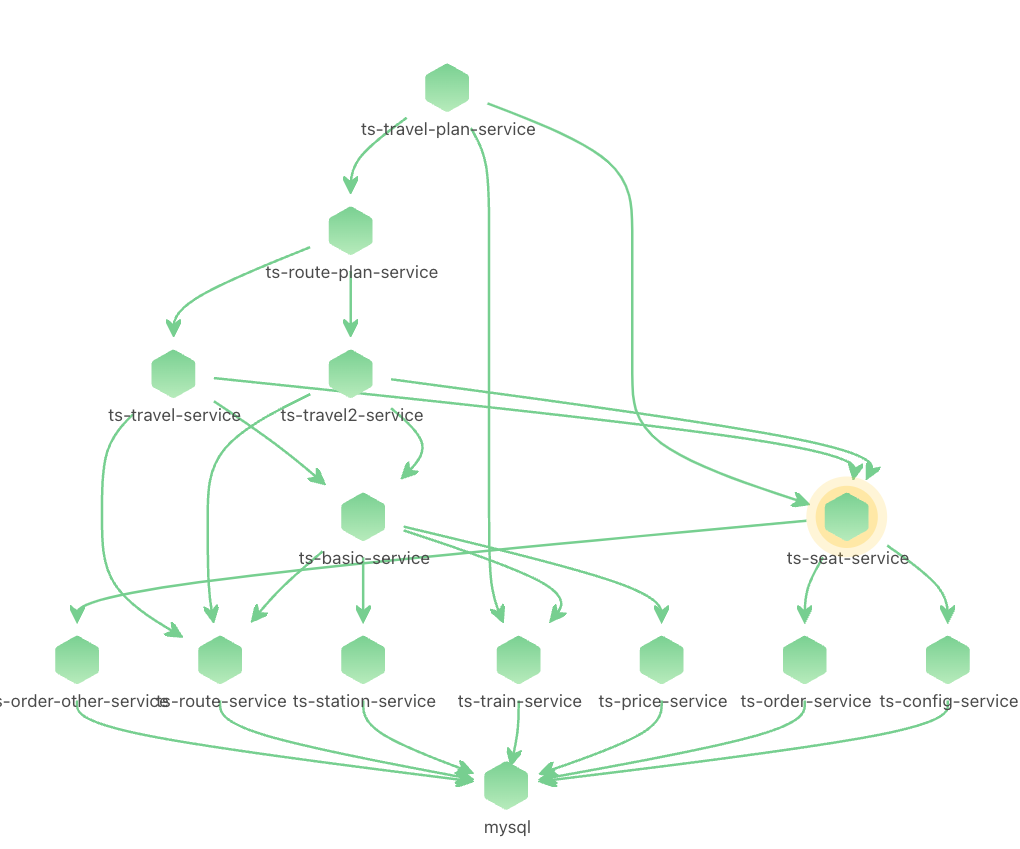
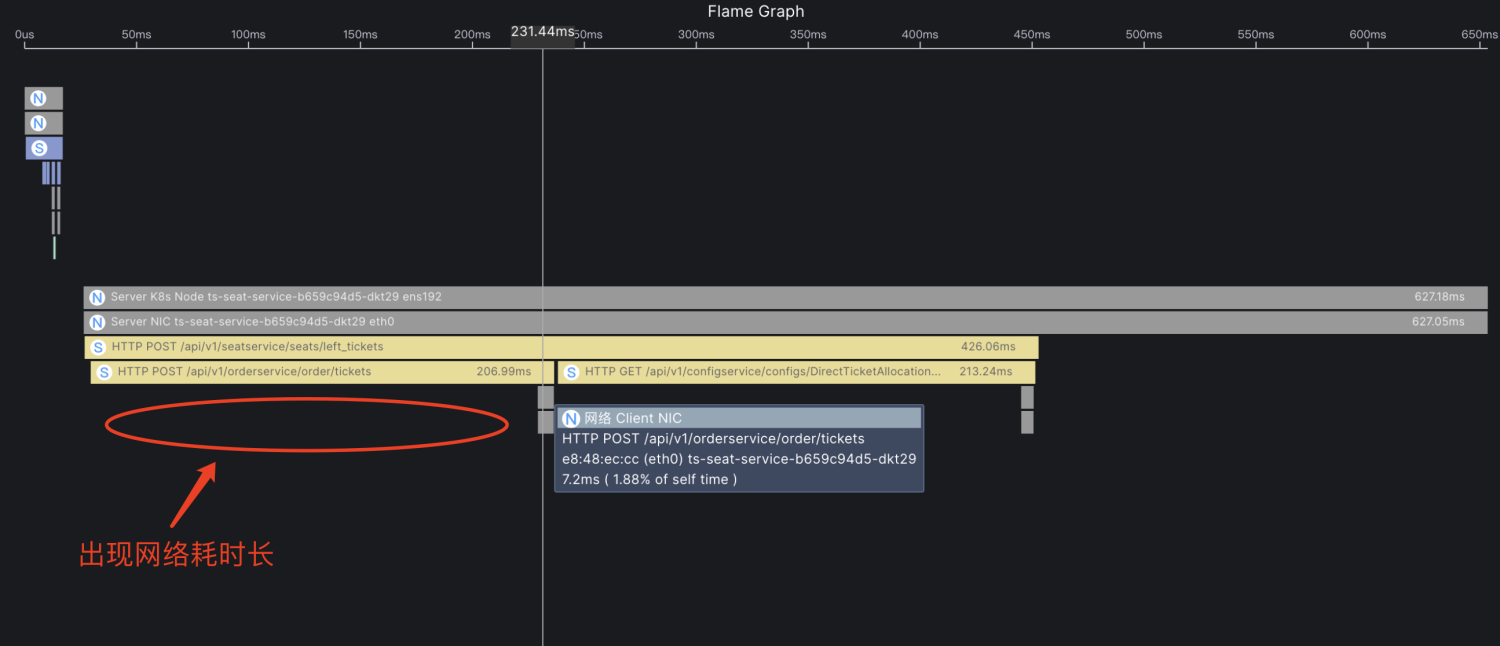
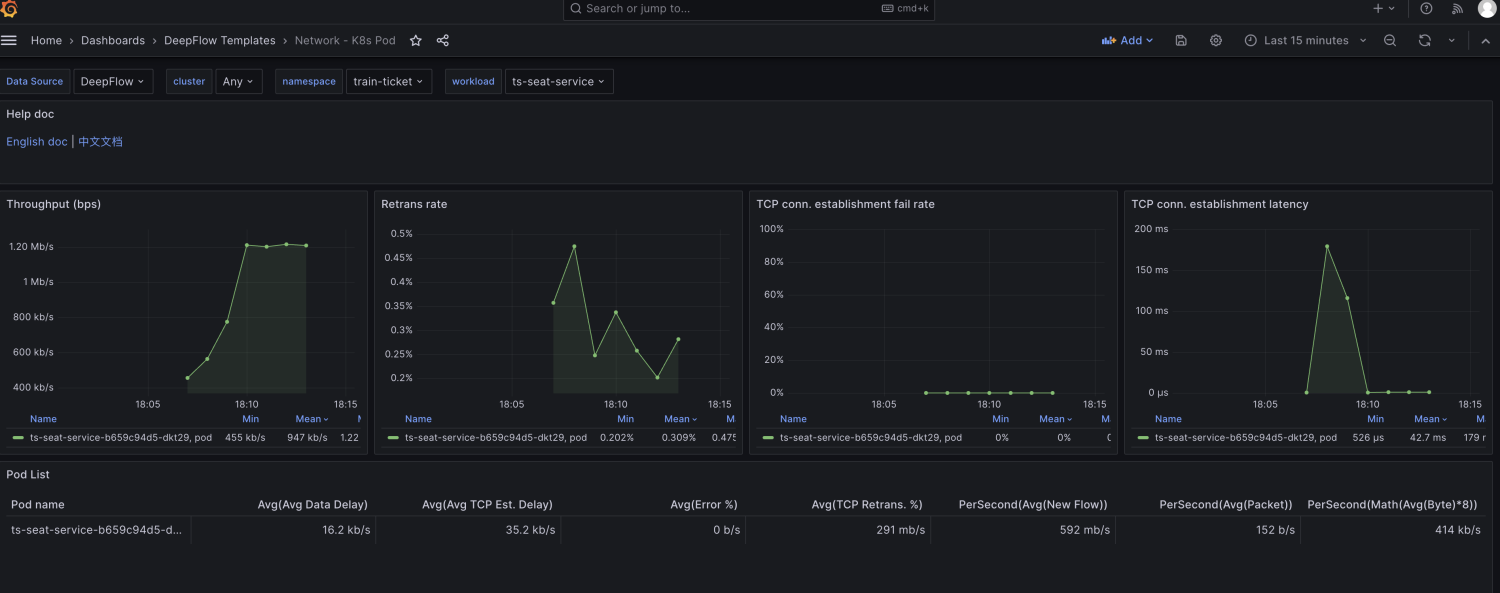
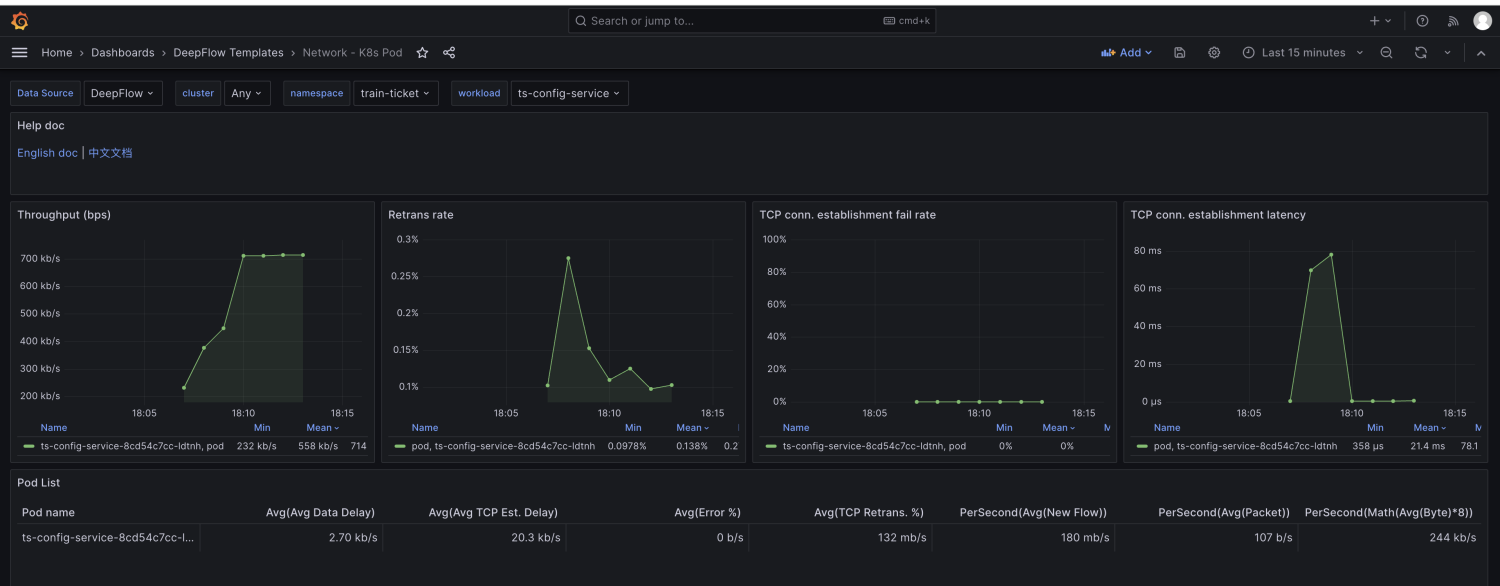

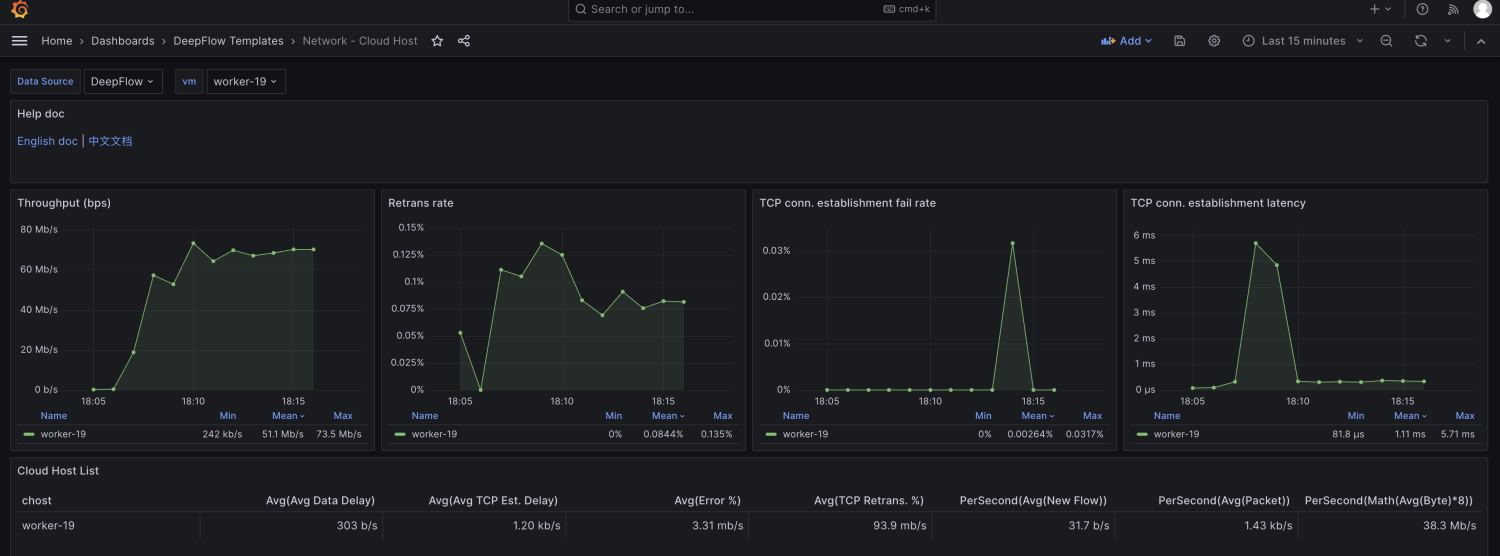
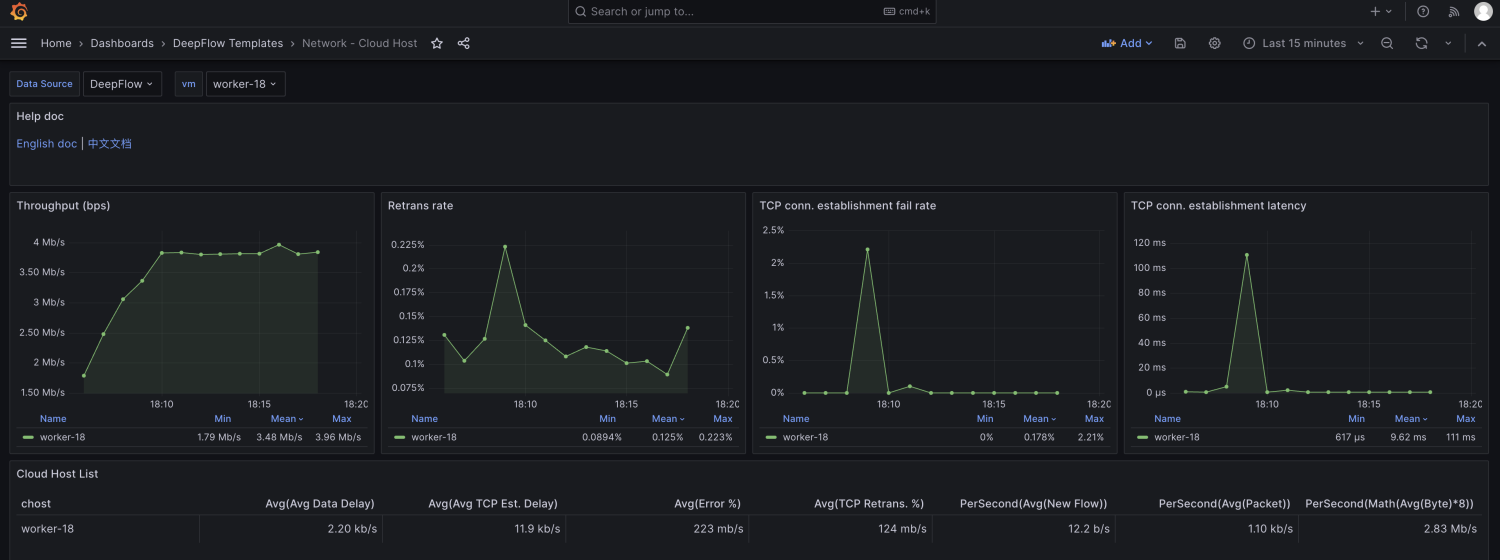 由于node级别的网络指标没有出现明显异常,最终确定是seat-service的pod级别rtt指标异常。
由于node级别的网络指标没有出现明显异常,最终确定是seat-service的pod级别rtt指标异常。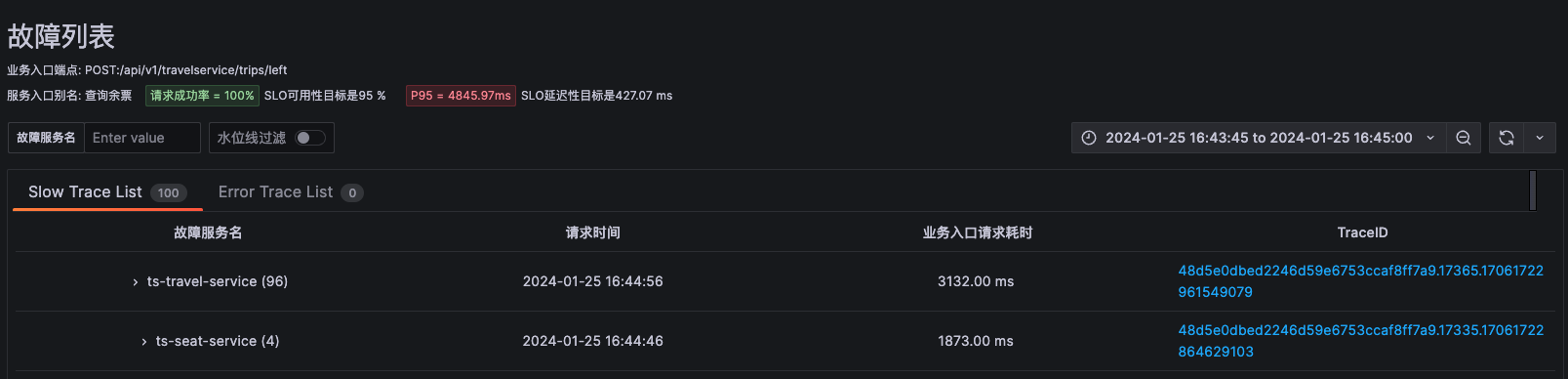


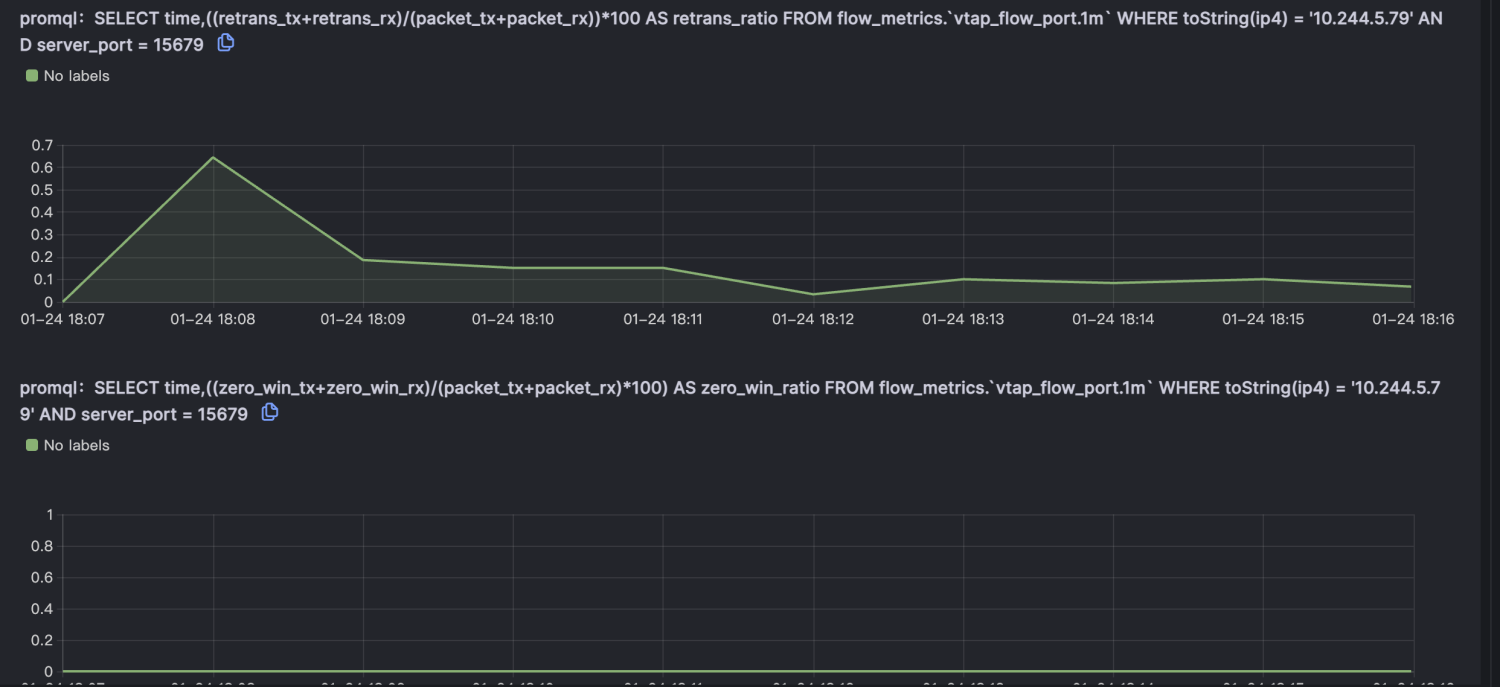
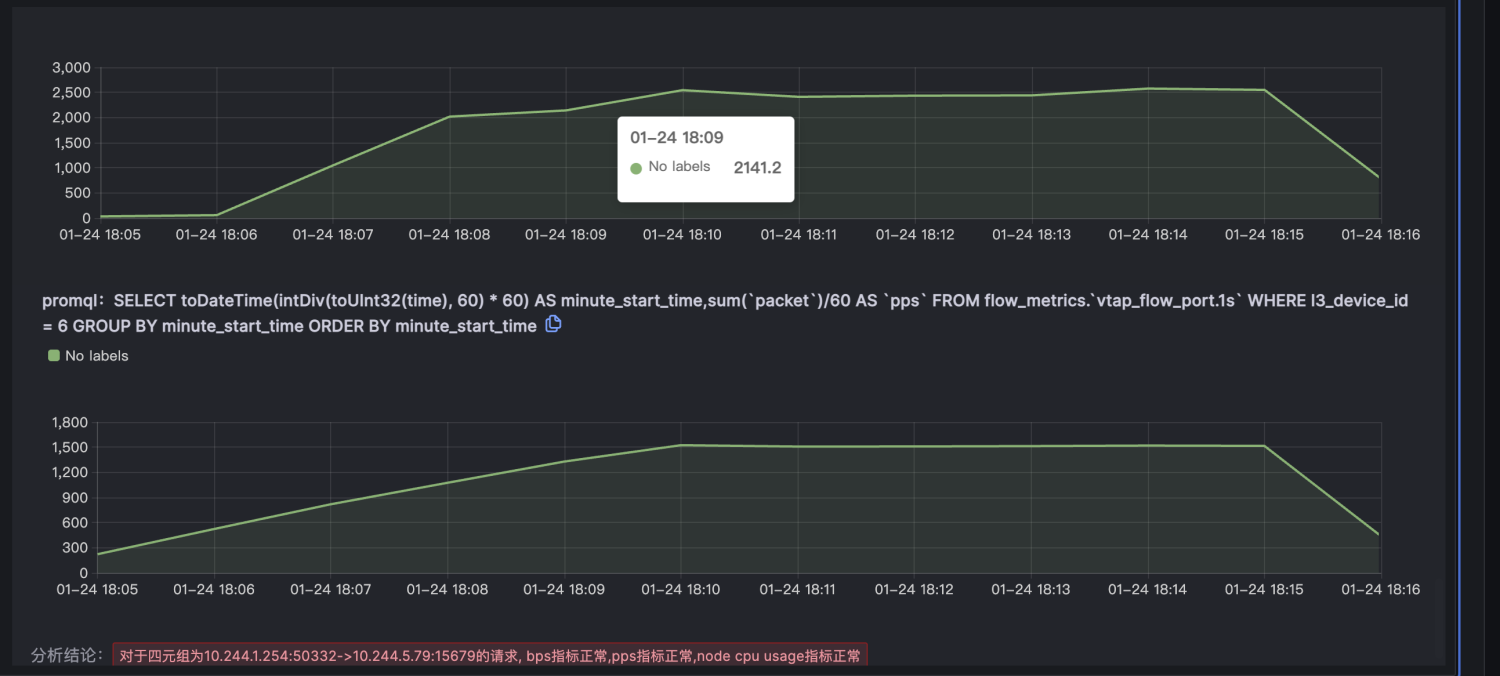 Kindling-OriginX 将整个故障推理都在一页报告中完成,并且每个数据来源都是可信可查的。
Kindling-OriginX 将整个故障推理都在一页报告中完成,并且每个数据来源都是可信可查的。