业界目前使用LLM做根因定位的思路
基于LLM构建智能体,比如日志智能体、网络数据智能体、Trace智能体。每种智能体负责两个事情:异常检测和自身范围内异常根因数据的推荐。目前很多公司的实际效果还处于实验阶段,还未达到实际生产效果。
目前做法太复杂,复杂体现在以下几个方面:
第一:可观测性的数据属于海量低价值的数据,要针对这些数据依赖AI寻找人能理解的异常太复杂。多数情况是噪音大于实际收益。
第二:多智能体的交互太复杂,而且是建立在第一步异常检测的基础上分析出根因。
我们的思路:
- 依赖人为经验的基于规则告警和异常检测体系。告警和异常检测是可以对接已有告警体系,实现快速接入落地。
- 依赖思维链在完成疑似根因节点的识别,这里面专家经验可以调整进化。
- 依赖北极星指标,利用报告快速确认疑似节点的根因。
用户需求
从用户需求侧而言,故障根因辅助定位才是需要的。
异常检测的价值太缥缈:
绝大多数公司内部告警体系已经完善,虽然可能并没有办法覆盖所有的情况,但是基本上都认为已经做到相当充分。
那异常检测的价值就是发现未知的未知问题,就未知的未知问题而言,用户是没有认知的。用户要从未知的未知真实问题中和噪音问题中,区分哪个问题有价值,还是噪音,这个对用户要求太高。
基于规则的异常或者告警已经能实现绝大多数异常检测的目标,而且具有充分的可解释性。所有的规则都可以梳理,并确认,所以这一步我们认为还是基于规则的效果较好。
根因辅助定位是绝大多数用户的需求:
这块我们交流下来是用户最有需求的,因为排障的标准化流程缺失,导致严重依赖专家,排障的时间周期并不能如预期完成,也就很难完成业界的1-5-10目标。
如何才能实现基于LLM和思维链实现根因辅助定位
大模型的限制
可观测性数据是属于海量低价值的数据,而大模型而言是有上下文限制的,目前主流的大模型也只能支持128K的数据。
一条Trace的数据大概2K,也就是几十条的Trace的数据量就将大模型的上下文撑满了,大模型也就没有办法更好的解释数据了。
业界领先者做法
受限于大模型的限制,所以目前很常见的大模型用法是将某个具体的数据提交给大模型,并请大模型帮忙分析出相应的结论。
- 比如将火焰图数据提交给大模型,请大模型帮忙分析出最长的代码段
- 比如将单次Trace数据提交给大模型,请大模型帮忙分析哪个Span最有问题
- 比如将指标曲线给大模型,请大模型帮忙分析异常时间点
用户期望的需求
从告警初始就开始使用大模型,而不是人为先筛选出具体的Trace或者具体火焰图数据,然后交给大模型。诚然,基于大模型帮忙解释部分数据是有价值,但是还有很多用户问题是:
“告警啦,我该如何从告警分析着手,在海量数据中找到最能反映故障的Trace然后深入分析这条Trace或者日志、指标,最终确定故障根因”
标准化数据
标准化,有价值的数据。我们认为将海量低价值的可观测性数据全都丢给LLM,让LLM去算出结论是不现实的。所以我们需要提前从海量低价值的可观测性数据中,先抽象出一套数据,这套数据能够被用来高效故障定位:
第一、能够反应程序调用关系的精准拓扑关系(没有此类数据,故障传播过程无法确定)
第二、成体系的告警,能将所有的告警和异常都关联至程序调用关系中(相互割裂的异常告警��,很难综合起来分析)
第三、北极星指标体系
利用前两个数据,确认疑似的根因服务、利用第三个数据实现最终指标级根因的确定
精准拓扑关系 VS 传统拓扑结构
故障传播在传统拓扑结构存在不确定性,导致思维链规则很难编写。
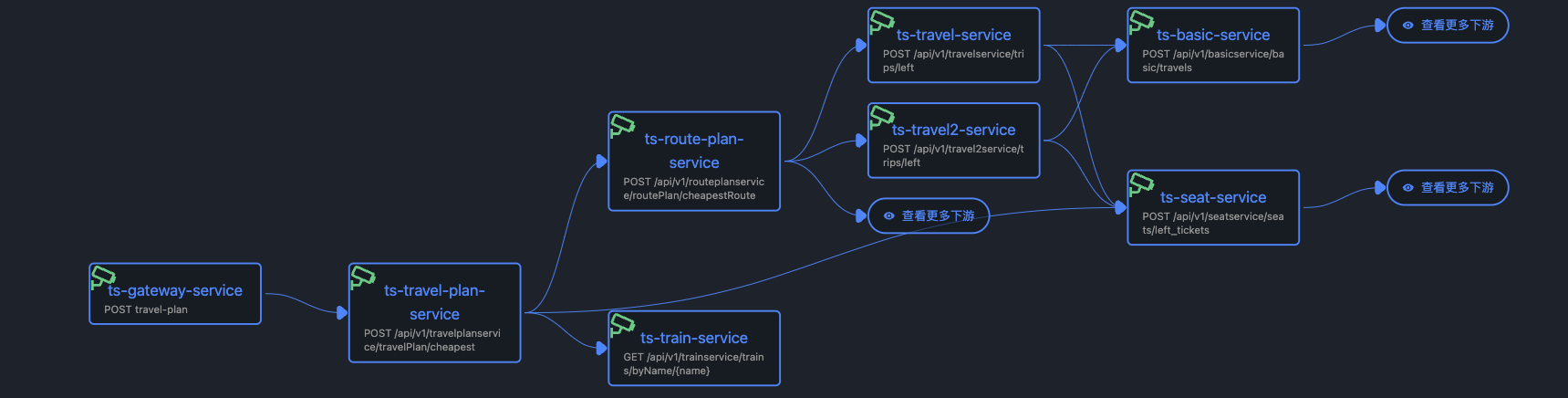
程序精准的调用关系如下:
程序的每一种URL调用,都能在拓扑中反映出来,这也是Dynatrace 的service-flow功能,目前可观测性相关产品中,也只有Dynatrace与APO实现了这种精准调用关系的拓扑。
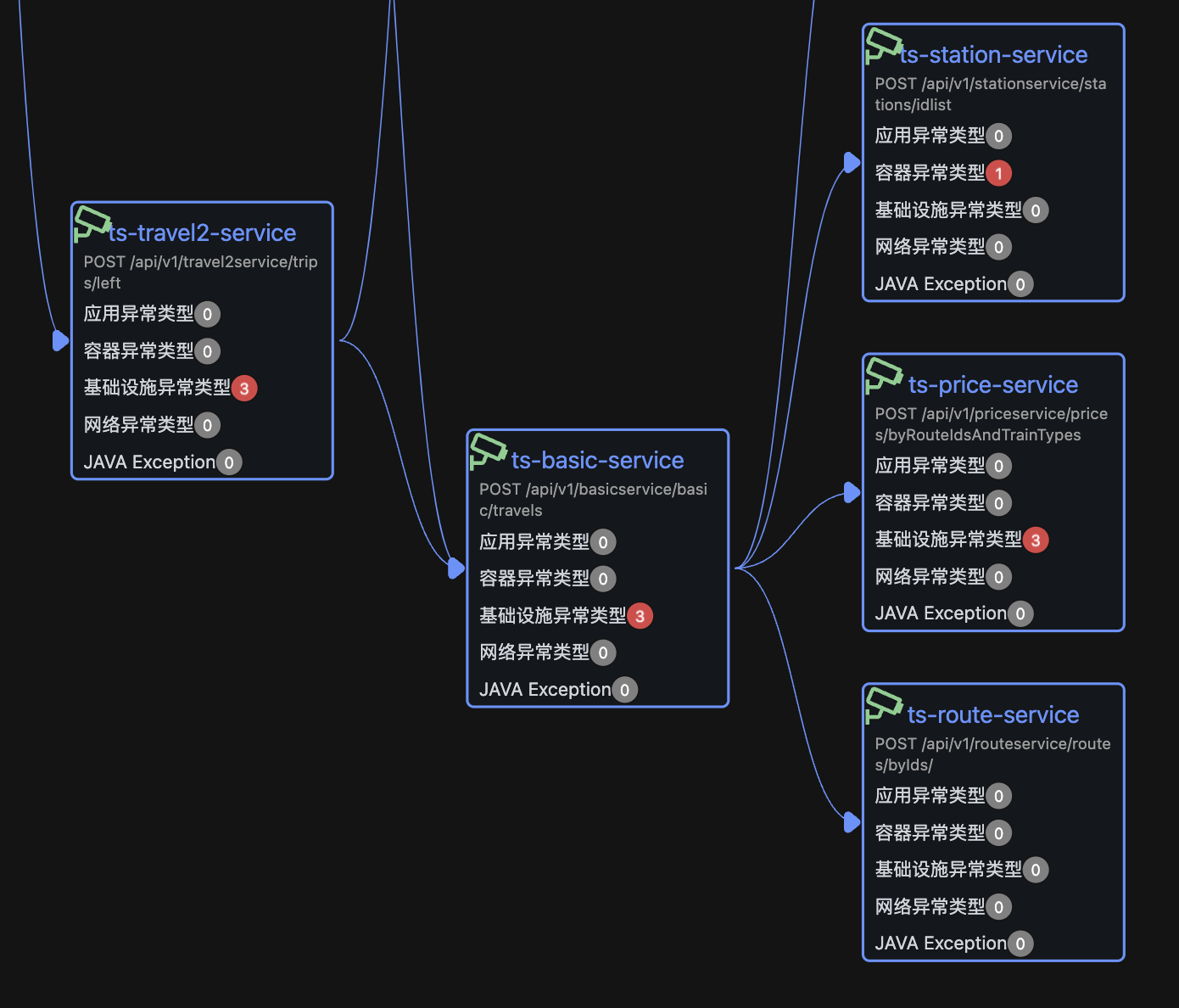
传统的拓扑的调用关系如下:
ts-travel2-service->ts-basic-service->ts-route-service
ts-travel2-service->ts-route-service
故障的传播链路只要有ts-route-service有告警,就需要往上排查ts-travel2-service的告警情况。而真实的情况故障传播链路在basic-service这里就可能不再往上传递,ts-travel2-service的告警和ts-route-service是没有关系的,但是传统基于应用服务的拓扑结构是无法区分此种情况。
拓扑成环的问题
如果一旦拓扑出现成环的问题,就会导�致告警的根源很难查找,因为整个环上的所有节点都互相依赖,都可能成为根因节点,就得将所有节点都列为潜在根因节点排查。
传统拓扑结构更大概率成环,因为是按照节点维度,但是实际调用过程业务是不可能成环,因为一旦成环之后,业务就无法正常执行了,只是拓扑结构再生产的时候舍去了某些关键信息才导致拓扑成环。
精准拓扑反应调用关系,虽然理论上无法100%避免成环,但是相比传统拓扑结构而言,绝大部分在传统拓扑结构成环的现象,在精准拓扑结构都不会成环。
拓扑数据太大的处理
大家都知道大模型对上下文的长度是有限制的,拓扑数据太大了会占据大量上下文,最终导致大模型在推理过程中不能很好的记住拓扑结构,推理工作也就进展不下去。我们采用相似性,对一个大的拓扑进行收缩,确保只有关键的拓扑结构与大模型交互,并不是所有结构都与大模型交互。
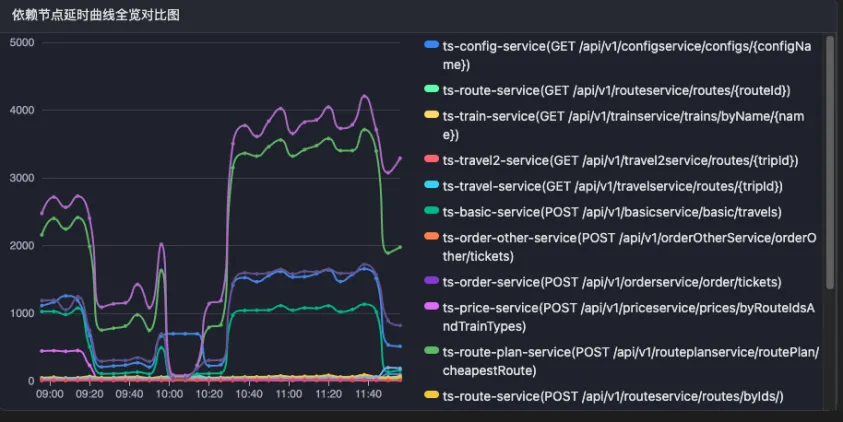
利用延时曲线或者错误曲线相似性,将大拓扑结构收缩。
原始拓扑结构

利用相似性收缩之后的拓扑结构:
相似性原理:
只有曲线相似的节点才被考虑进拓扑结构,曲线不相似的节点会被收缩。举例如下图:比如黄线所代表的节点�一直很平稳,所以不应该作为疑似节点考虑,可以收缩起来。
告警的数据模型:
告警的关联方式:
- 应用层告警(URL接口延时异常和错误异常)
- 网络层告警(节点之间连接的网络周期性Ping值异常)
- 基础设施主机层告警(主机的CPU、 内存、磁盘、网卡吞吐量异常)
- 容器告警(k8s事件比如容器killed, 容器重启等异常)
- 错误告警(Java程序使用java Exception,非Java程序,使用日志错误数异常。解决微服务场景中会识别不了错误的场景、将错误封装到error code中,导致http status code永远是200)
- 应用层的告警是直接关联至拓扑结构
- 基础设施层告警,间接关联至拓扑结构,比如主机的CPU高,可能潜在的影响主机上的所有业务,但是并不是主机上所有的业务就会一定受到影响,所以说基础设施告警是间接影响应用层的告警
- 网络层告警,间接关联至拓扑结构,只要TCP四元组出现ping延时异常,即认为应用延时和错误可能受到网络的潜在影响,同理也是间接影响,并不能认为网络一旦出现抖动,应用延时就一定有问题
- 容器告警,k8s相关事件也间接影响应用的执行
- 错误告警,为了能更好识别应用错误,因为微服务框架导致错误识别不了,http statuscode永远为200,所以需要额外错误告警的弥补错误场景识别不精准的问题
基于LangChain的思维链,利用大模型完成根因推理。
我们的目标是提供一个可以不断完善的根因推理思维链条,所以每个规则其实都可以修改,规则一定要符合当下人员排障的惯性思路。
可进化的规则
目前我们提取了符合用户习惯的常规规则,这些规则可以根据不同的专家经验不断完善。
规则:
从应用接口层告警(如 URL 接口延时异常、错误异常)出发。沿着业务入口的拓扑结构,从上游向下游每个节点依次追踪(使用拓扑图数据,不要搞错上下游)。 请输出推理过程
在追踪过程中分析每个节点: 如果存在接口层告警,继续向其依赖的下游节点追踪,该节点在两种情况下作为疑似根因节点,第一该节点存在其它类型的告警,第二其下游所有节点没有1类型接口告警,其它情况该节点都不是疑似根因节点。
如果没有接口层告警,停止追踪,返回上一级节点,当前节点排除。
在追踪过程中,对于每个有1类型接口告警的节点:
检查是否存在其他类型的告警(如应用层、容器层、基础设施层告警),如果存在,则该节点是疑似根因,记录并继续分析下游节点追踪。
如果不存在其他告警,同时该节点所有下游节点都不存在1类型接口的告警,则该节点是疑似根因节点。
如果节点就是是最下游的节点,同时节点也存在1类型接口告警,该节点也是疑似根因节点。
最下游节点定义:依赖链路上没有进一步下游依赖的节点。 最下游节点如果有告警,是疑似根因的优先候选。
回答格式要求给当前规则推理过程,不用附带完整数据,需要给出精简数据。
解释:
上游节点的应用告警是由下游传递导致的,所以上游节点不是疑似根因节点
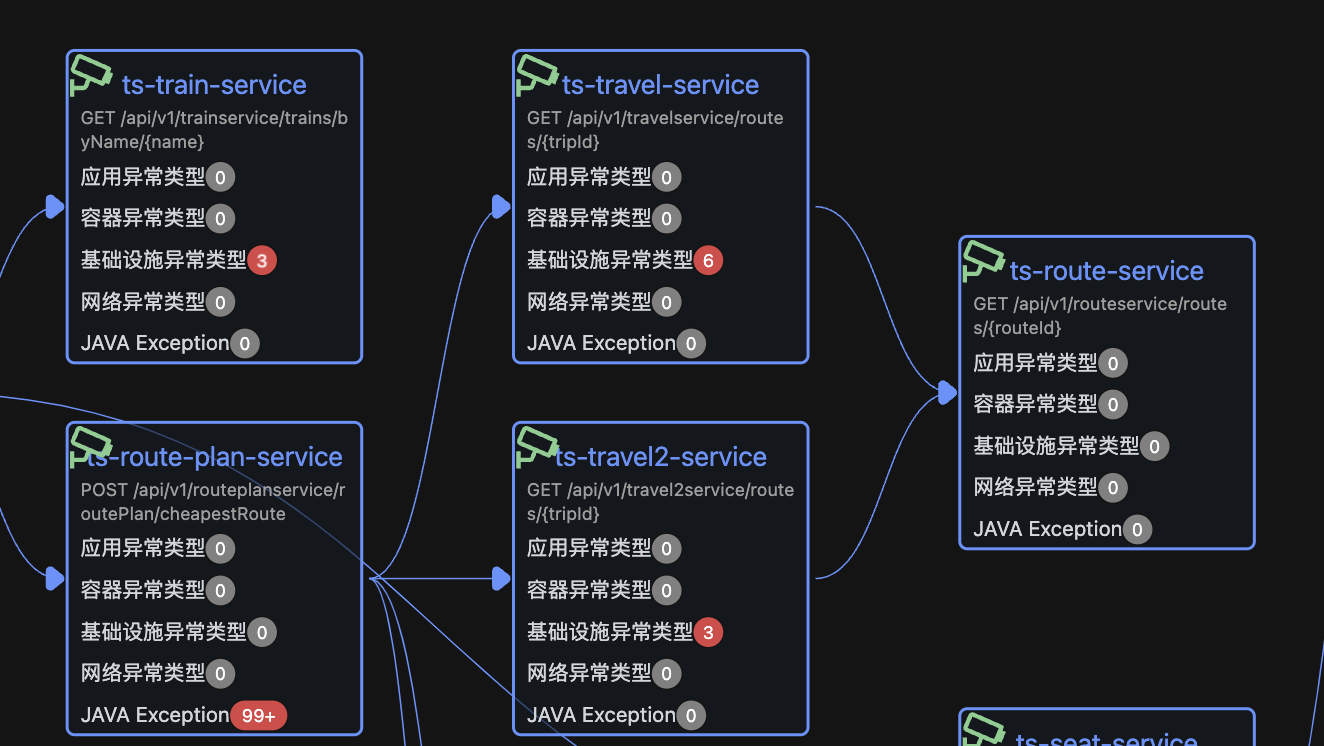
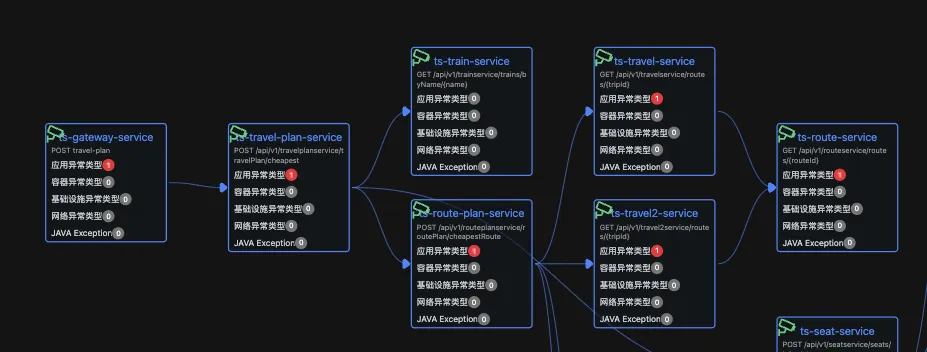
示例中应用告警传递过程 ts-route-service -> ts-travel-service -> ts-route-plan-service -> ts-gateway-servcie
规则:
上游节点的应用告警是由下游传递导致的,所以上游节点不是疑似根因节点
示例中应用告警传递过程 ts-route-service -> ts-travel-service -> ts-route-plan-service -> ts-gateway-servcie。
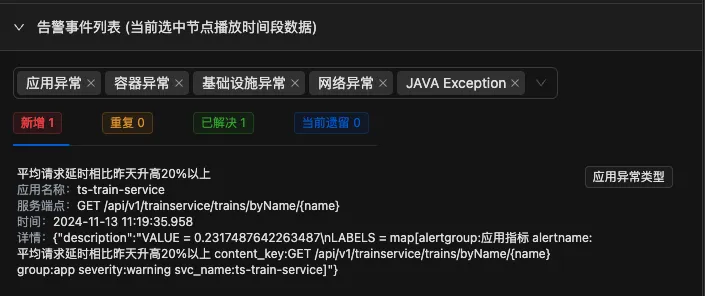
新增发生在:11:19:35秒
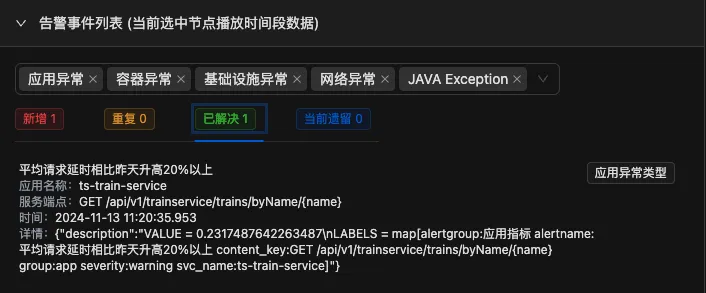
已解决发生在:11:20:35秒
规则:
如果某个节点发生异常,但是上游节点未发生应用异常告警事件,可以将这个节点及其分支全部排除
解释:说明这些告警都是干扰项,可以排查
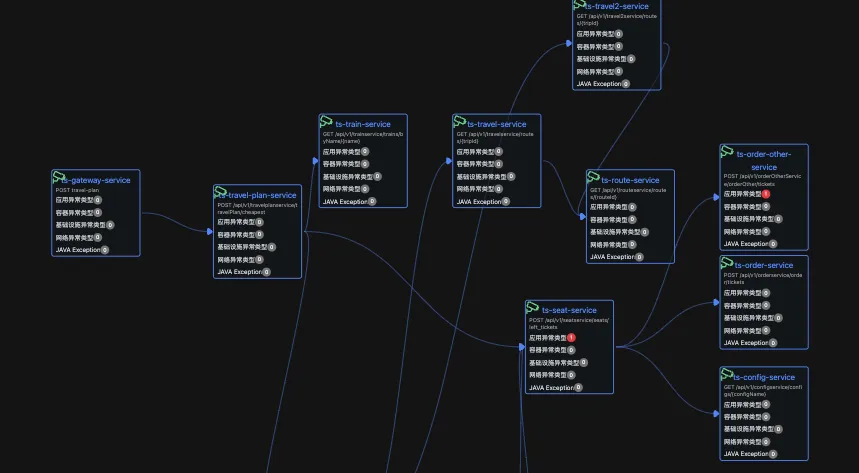
基于北极星的闭环确认根因
当我们基于规则疑似故障根因节点之后,根据北极星指标可以确认疑似根因节点到底发生了什么情况,导致的问题。
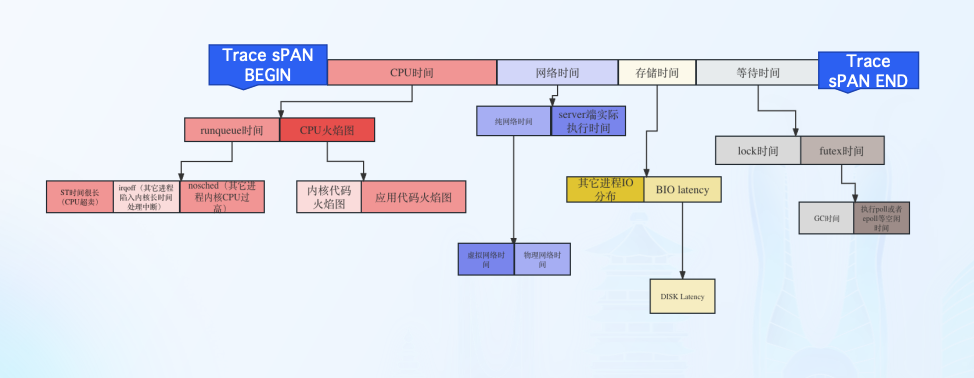
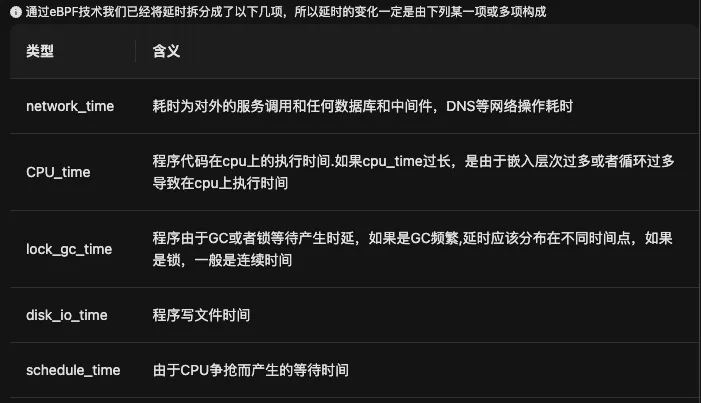
北极星指标曲线是利用eBPF技术,将请求延时完整的拆解成了主要的几个故障方向,当延时变化之时,可以根据哪个分项的变化曲线最相似,从而判断疑似故障节点的故障方向。
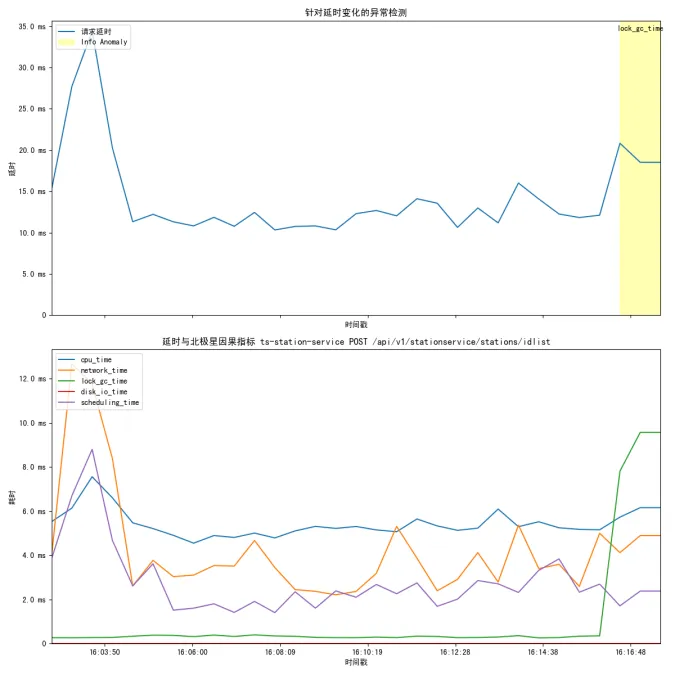
从这张图中,可以很快确认程序后期的延时上升主要的原因就是lock_gc_time的上升导致的,但是在最开始程序波动的原因是由于net-workTime导致的。
如果这个时候有CPU-IO wait高,说明这些IO异常对程序的执行过程其实没有任何影响。
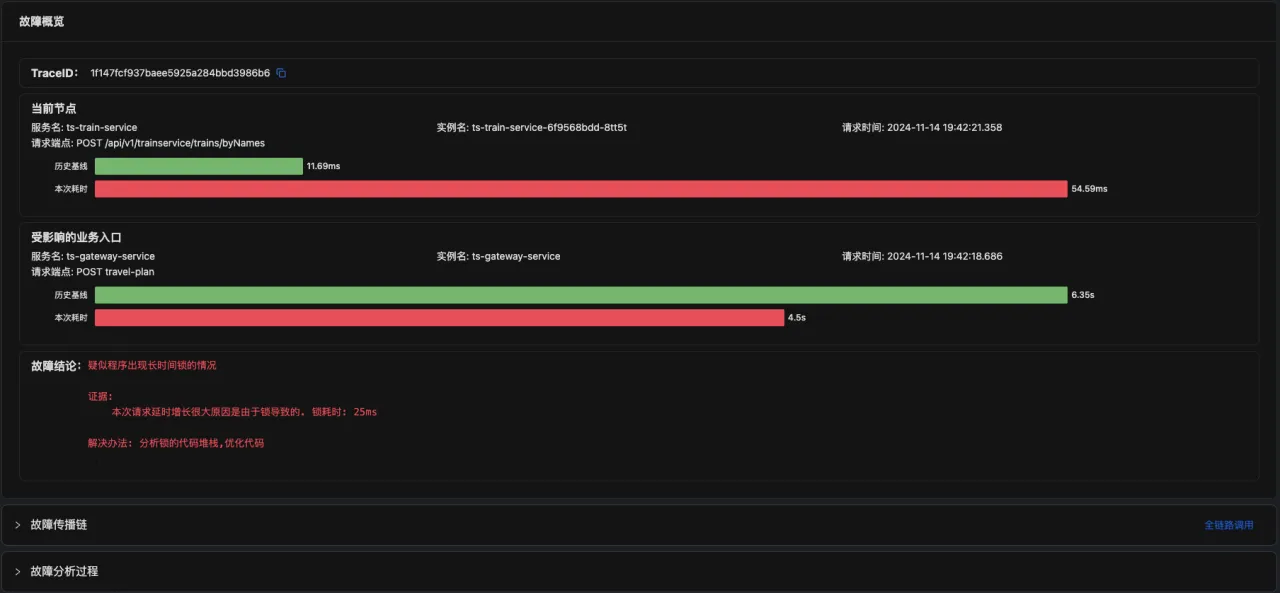
最终的证据报告
最终通过关联可观测性数据,形成最终的证据报告,说明该问题。
点击下方链接观看演示视频:通过大模型对话来分析告警事件
(https://www.ixigua.com/7441033779788907046?utm_source=xiguastudio)
APO介绍:
国内开源首个 OpenTelemetry 结合 eBPF 的向导式可观测性产品
apo.kindlingx.com
https://github.com/CloudDetail/apo

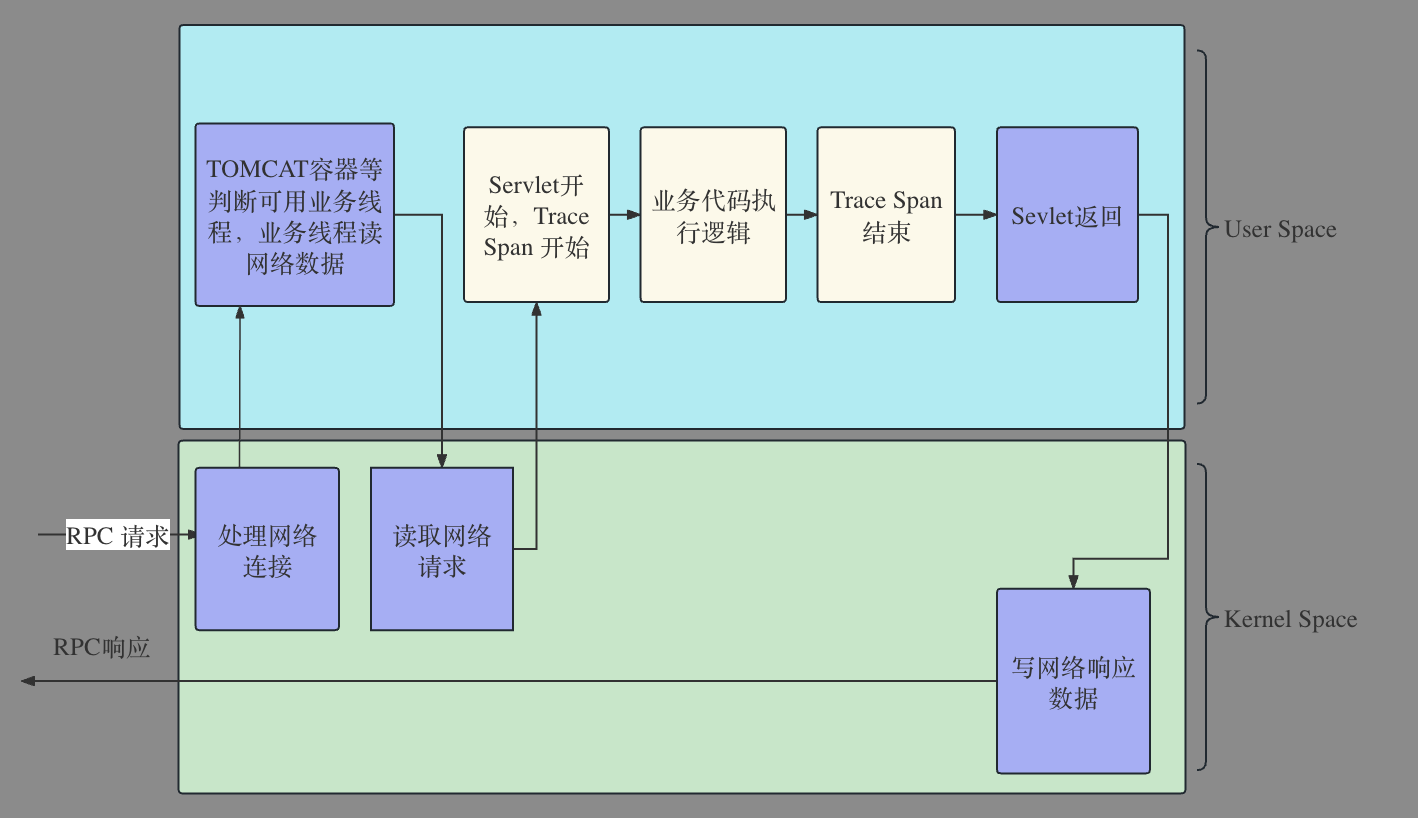






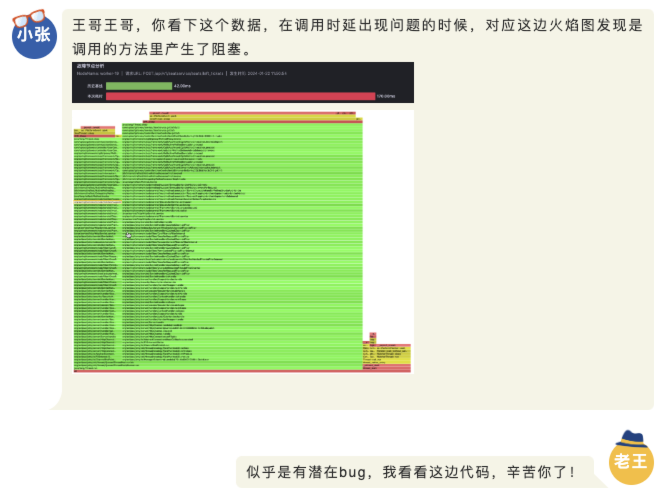
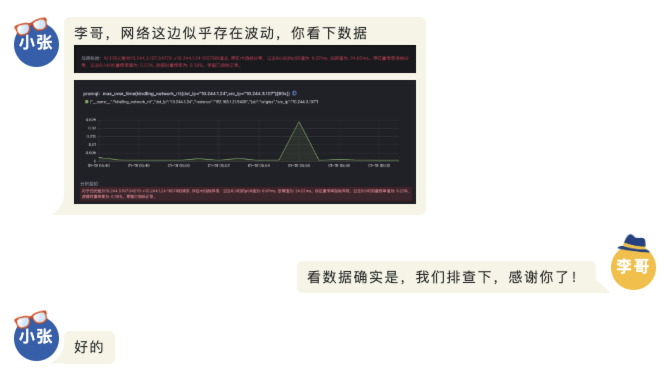
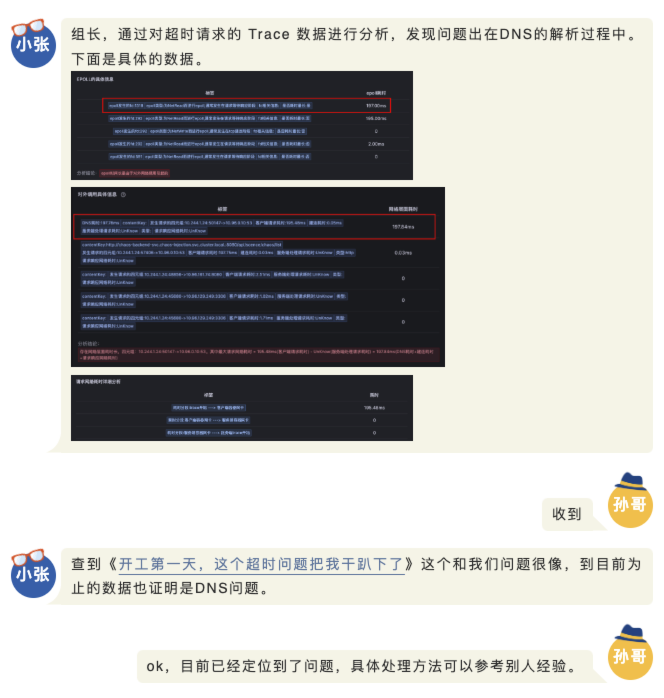 对于难以明确排查方向,无法定界的故障,Kindling-OriginX 快速组织和分析故障线索,通过自动化 Tracing 关联分析,以给出可解释的根因报告的方式,为这类故障提供可操作的排查方法。
对于难以明确排查方向,无法定界的故障,Kindling-OriginX 快速组织和分析故障线索,通过自动化 Tracing 关联分析,以给出可解释的根因报告的方式,为这类故障提供可操作的排查方法。
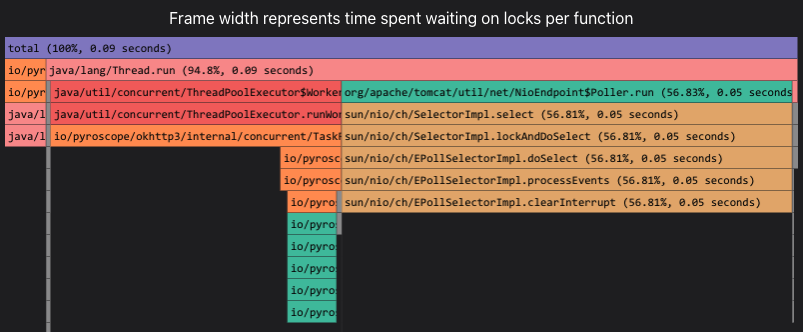

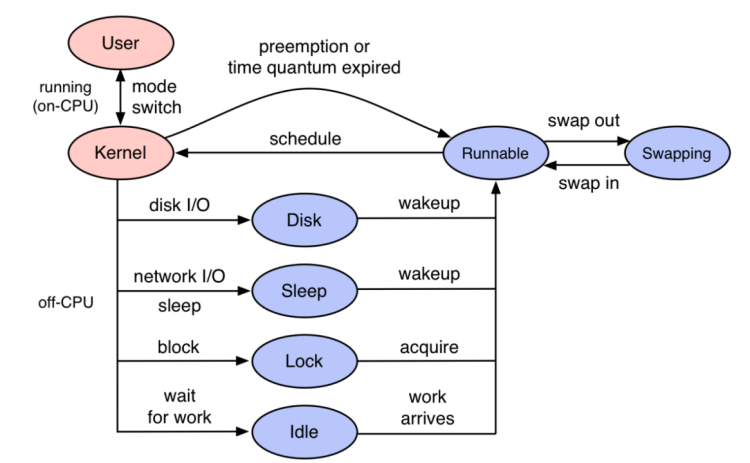
 如果使用Trace-Profiling,应该能够明确给出当时业务是卡住下列事件之一
如果使用Trace-Profiling,应该能够明确给出当时业务是卡住下列事件之一