APO v0.5.0 发布:可视化配置告警规则;优化时间筛选器;支持自建的ClickHouse和VictoriaMetrics

APO 新版本 v0.5.0 正式发布!本次更新主要包含以下内容:
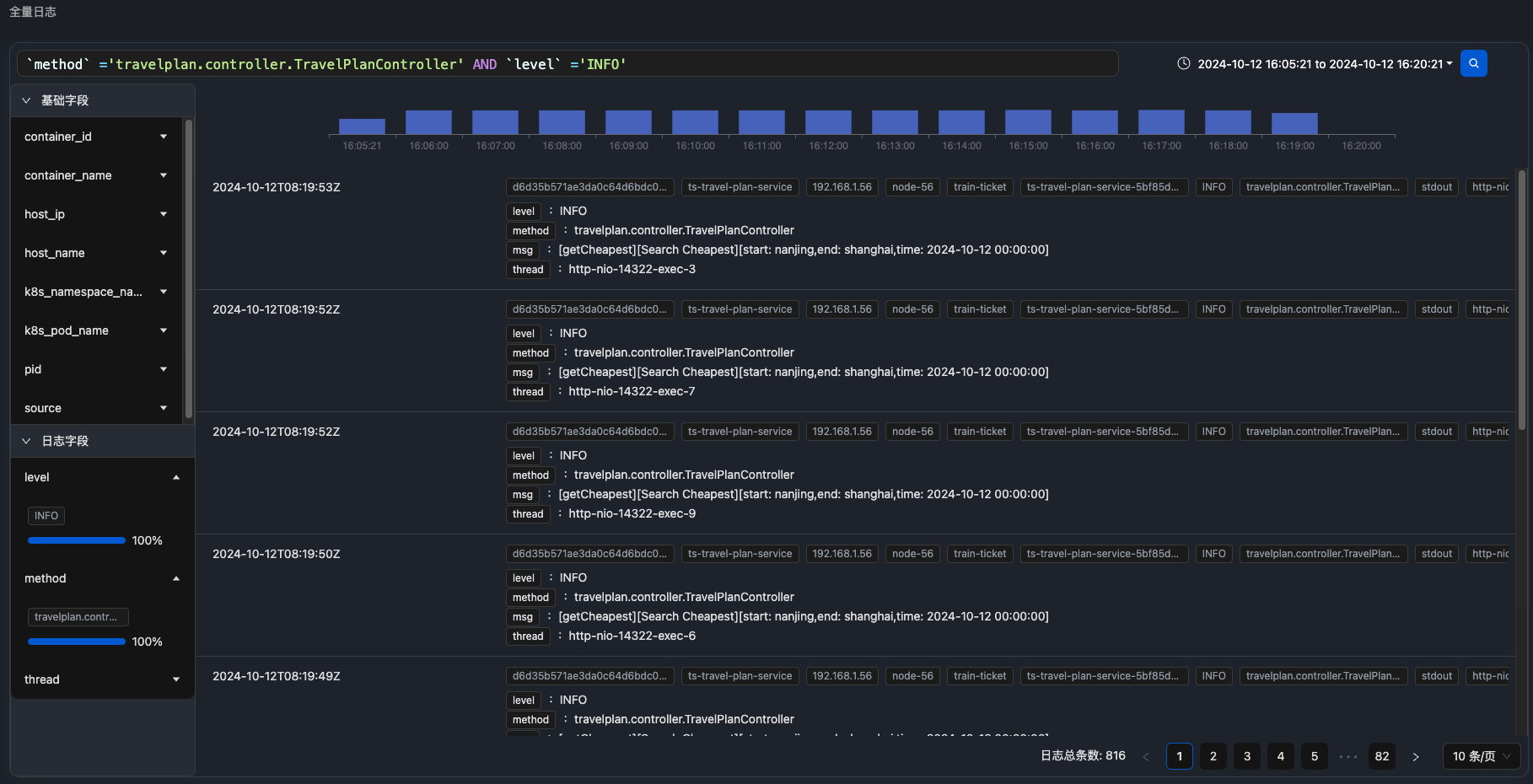
新增页面配置告警规则和通知
在之前的版本中,APO 平台仅支持展示配置文件中的告警规则,若用户需要添加或调整这些规则,必须手动编辑配置文件。而在新版本中,我们新增了一套可视化的告警规则配置界面,使用户能够直接通过 APO 控制台来进行告警设置。此外,配置界面内置了常用的指标查询模板,用户只需根据实际需求选取相应的指标并设定阈值,即可轻松完成规则配置。
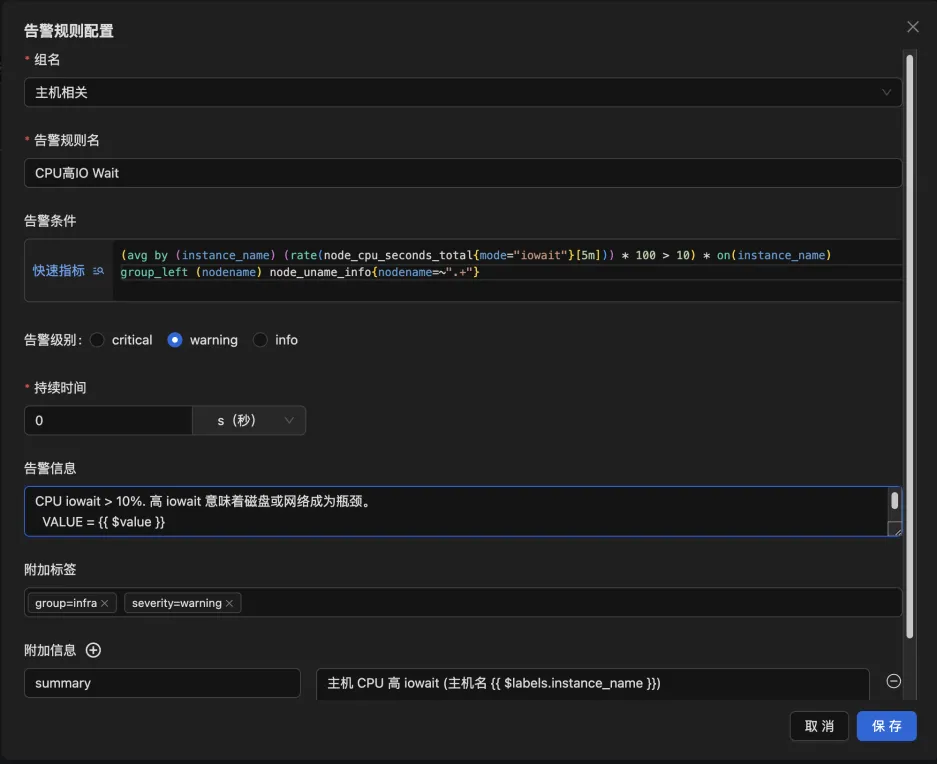
同时新版本还支持配置告警通知,目前支持邮件通知和 Webhook 通知。
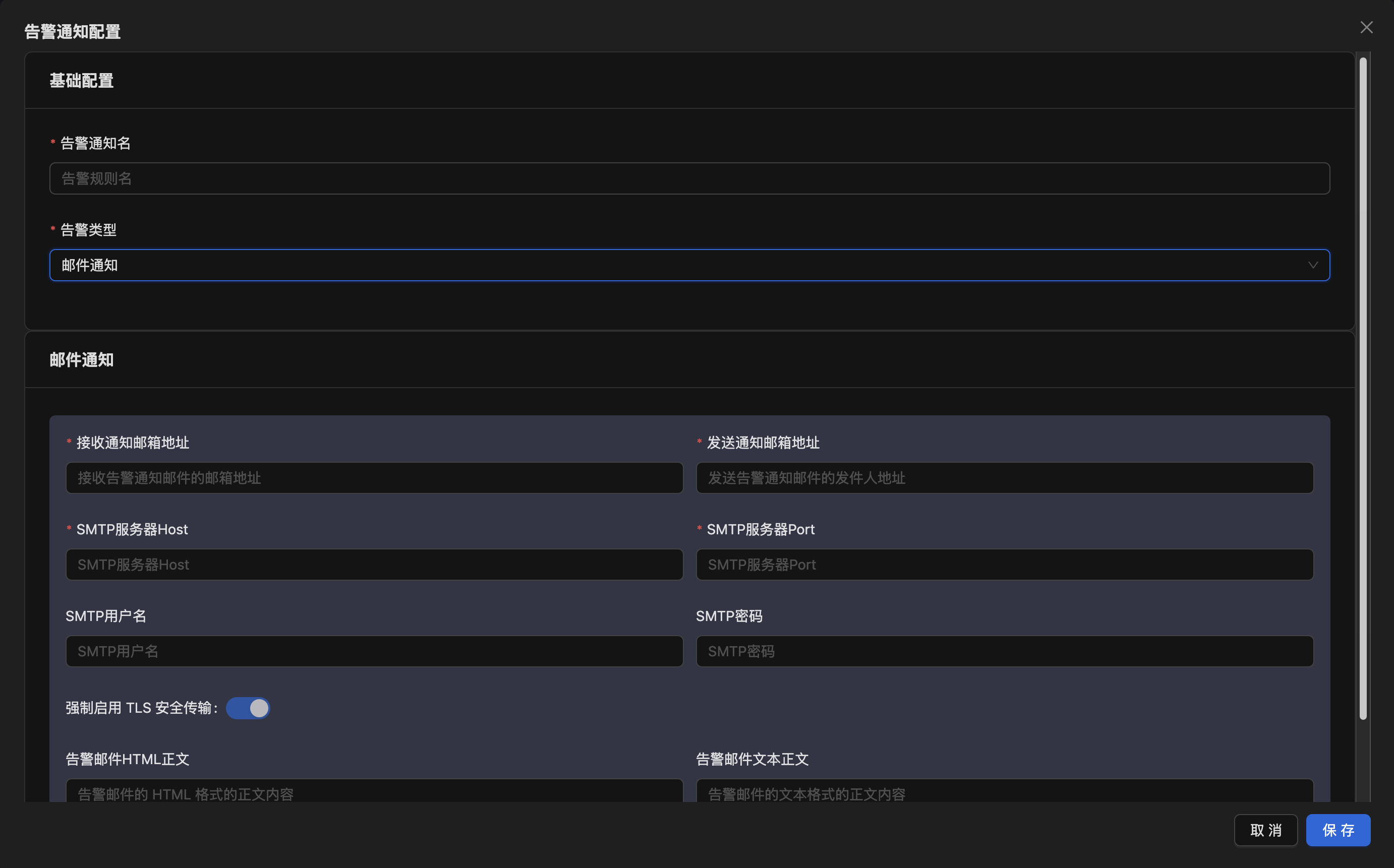
0.5.0 作为告警配置的第一个版本,仅包含了基础功能,未来我们还将继续优化用户体验,并带来更丰富的配置选项以满足更复杂的场景需求。欢迎大家积极向我们提出建议。
更好用的时间筛选器
在之前的版本中,APO 的时间筛选器仅支持查询绝对时间,并且需要用户手动触发更新操作。而在新版本中,我们重新设计了时间筛选器,增加了相对时间的支持,并实现了页面的自动刷新功能。以后再也不会出现“新监控了一个应用,但怎么刷新页面也没数据”的问题啦!

支持使用自建的 ClickHouse 和 VictoriaMetrics
从 0.5.0 版本开始,APO 支持将数据存储到用户自建的 ClickHouse 和 VictoriaMetrics 中,无论您是使用单节点还是分布式集群方案,APO 都能够无缝接入。在生产环境中,我们建议使用托管的 ClickHouse 和 VictoriaMetrics 集群来保证可用性。
近期,APO 社区正在积极设计开发“全量日志”的功能,我们调研分析了业内优秀的日志方案,结合在可观测性领域积累多年的经验,完整设计了从日志的采集、处理、存储到展示的方案,将 APO 对日志的思考融入其中。我们的目标始终是为社区提供一款开箱即用、高效率、低成本、强扩展性且拥有良好用户体验的可观测性产品,全量日志方案自然也不例外。全量日志功能预计将于10月开源,敬请期待!
我们衷心感谢所有参与测试和支持 APO 社区的用户们。正是因为有了你们的反馈和支持,APO 才能不断进步。我们期待着您的宝贵意见,也欢迎您继续参与到 APO 的成长旅程中来!
更多变化请查看下述更新列表。
新增功能
- 新增页面配置告警规则和通知功能
- 服务实例中关联实例所在节点信息,辅助排查节点
功能优化
- 优化时间选择器,支持查看相对时间,支持自动更新
- 优化故障现场链路页面描述,使信息显示更清晰
缺陷修复
- 修复单进程镜像覆盖JAVA_OPTIONS环环境变量失败导致无法加载探针的问题
- 修复部分情况下无法获取 Go 语言程序的链路追踪数据的问题
其他
- 支持对接自建的低版本 VictoriaMetrics,建议版本 v1.78 以上
- 支持对接自建的 ClickHouse 集群(安装时配置)
- 服务概览无数据时提示安装和排查手册
- 提供一键安装脚本部署测试应用,验证 APO 安装结果和产品功能
- 提供仅使用链路追踪或采集指标的安装方案