LLM + 可观测性根因分析:方法、真实效果与数据鸿沟

近两年,大模型(LLM)逐步进入可观测性领域。无论是ITBench SRE Agent还是OpenDerisk,都在尝试用大模型自动化根因分析(RCA):通过向模型输入来自分布式系统的指标(metrics)、调用链(traces)和日志(logs),由模型推断“哪个主机、哪个服务、哪条调用链”最可能是故障根源。
常见的分析流程模式
尽管技术路径存在差异,多数方案遵循类似的三阶段流程:
01指标异常检测
从Prometheus提取RED指标或业务KPI,通过阈值或基线模型识别持续异常的 “组件–指标” 组合,从而缩小可疑范围
02调用链踪拓扑分析
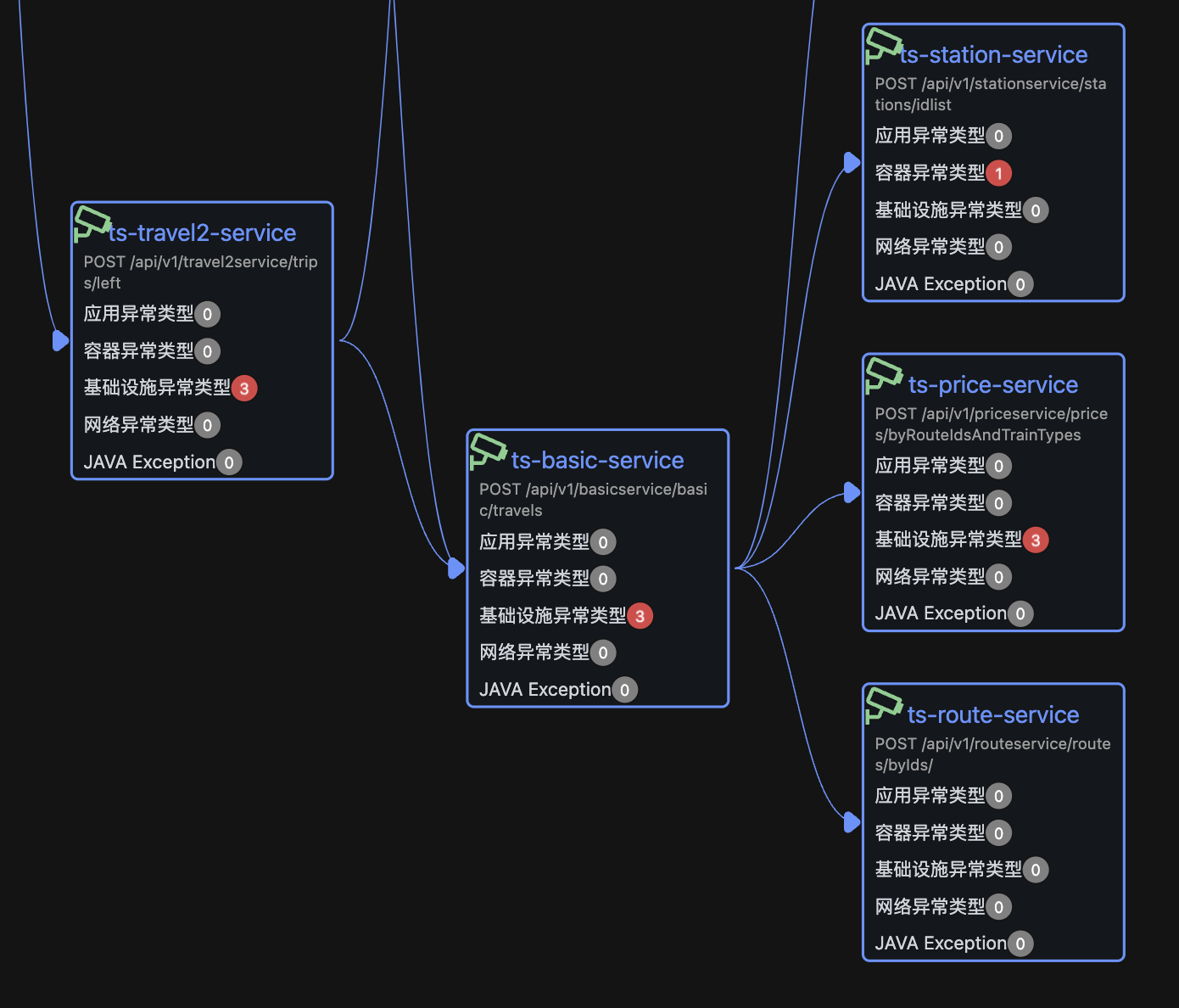
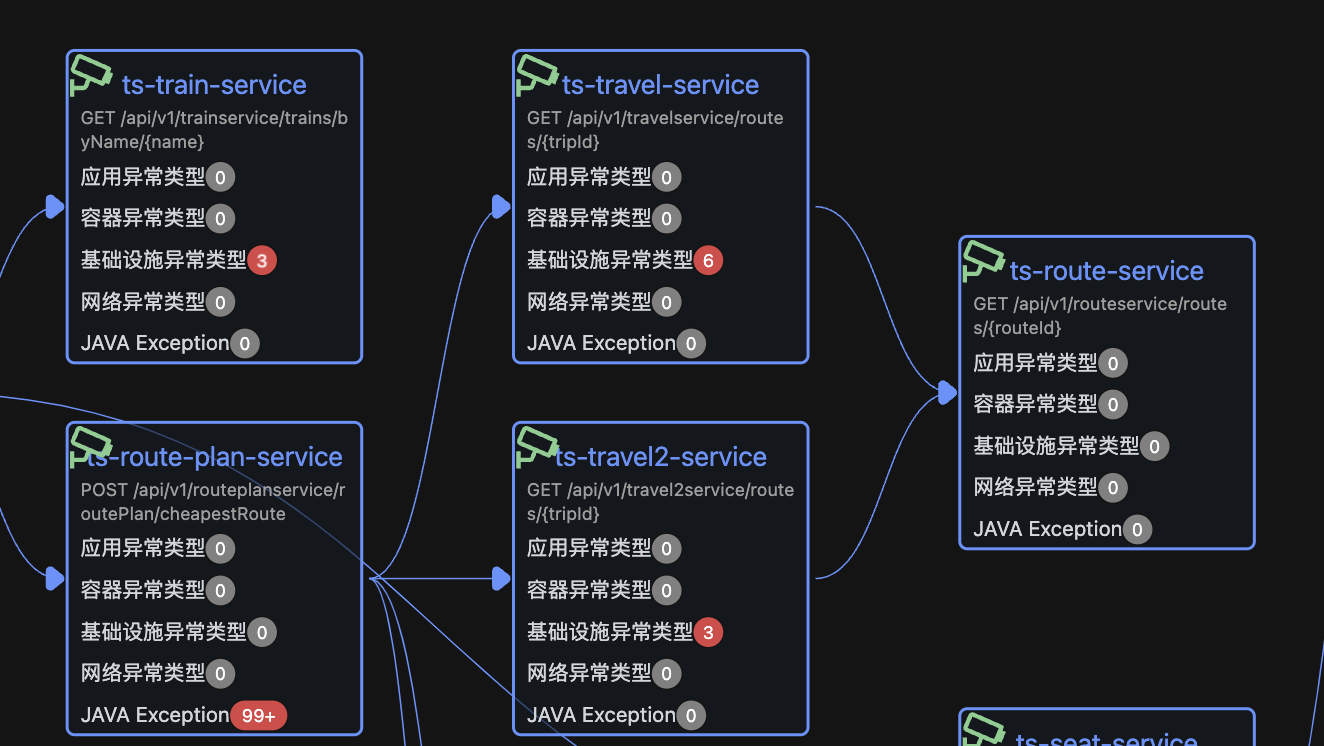
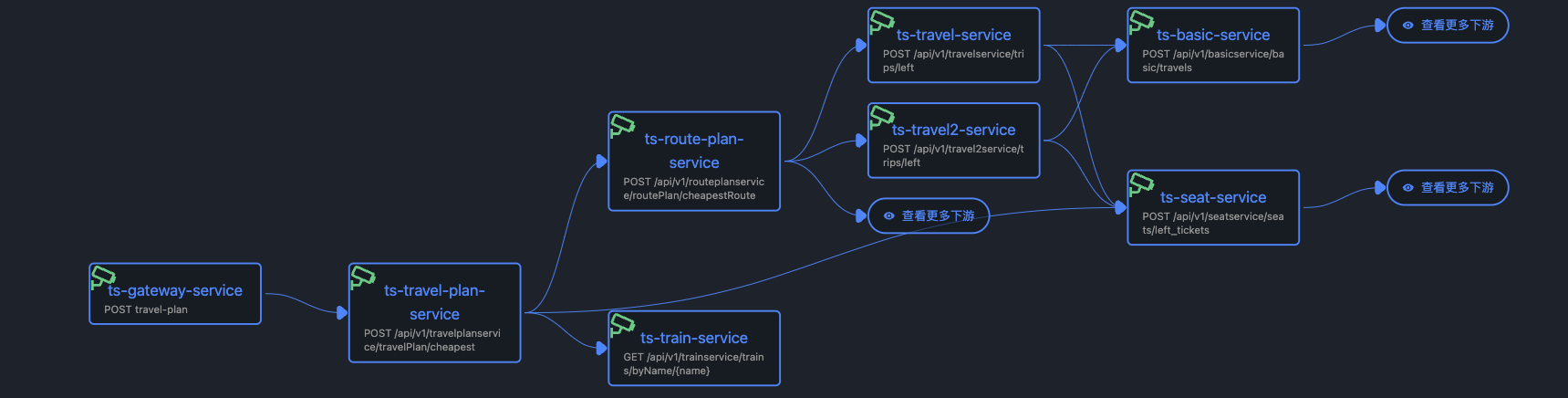
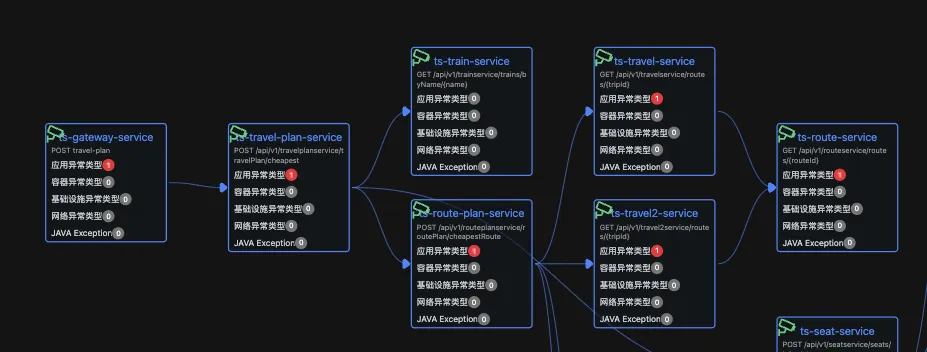
基于Jaeger获取调用关系,沿调用链查找“异常最靠下游的节点”,避免将下游的连带效应误判为上游根因。
03日志语义验证
从Loki/Elasticsearch提取相关时间窗口的日��志记录,利用 LLM 解析错误码、堆栈信息和上下文,生成自然语言报告并提出修复建议
ITBench将该工作流应用于实时告警,告警触发后自动拉取多维数据,生成根因链路并可直接触发修复命令。
OpenDerisk则采用多智能体协作:在一次 RCA 任务中,由不同 Agent 分别处理指标、调用链、日志,再汇总证据生成最终报告。
对用户而言,这两种方案体验相似:提供三类遥测数据,由AI综合分析,最终输出易于理解的结论。
现实检验:准确率远未达标
这两个开源项目目前没有对外公布准确率,但论文 OpenRCA 的实验数据表明,这种方法的实际准确率并不理想:
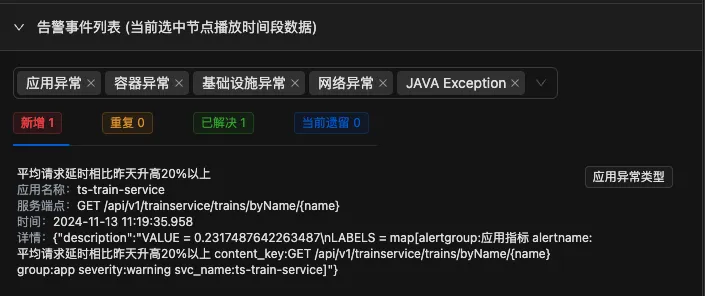
- OpenRCA论文中报告其根因准确率低不足15%
- ITBench虽优化了数据采集与算法,但提升幅度有限
- OpenDerisk虽引入多源交叉验证,仍难以达到生产环境可用标准
即使针对历史故障进行定向训练,性能提升依然有限。
问题题不在模型和算法,而在可观测性数据本身的鸿沟。
可观测性中的“两层数据缺口”
01生产环境采样限制
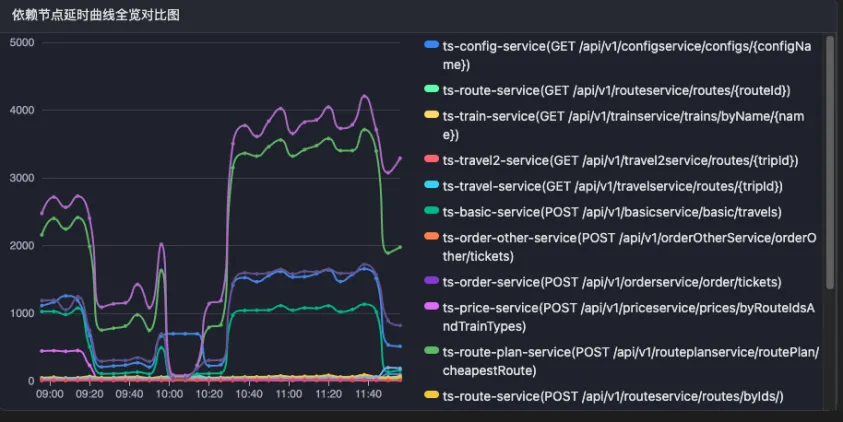
- Prometheus指标常通常以分钟级采样,短时抖动被平滑掉
- Trace受采样率限制,关键调用链可能根本未被记录
- Log依赖开发人员埋点,关键路径常存在覆盖盲区
02分析过程的二次采样
- 即使原始数据完整,将所有metrics、trace、log输入LLM亦不现实——延迟与成本将急剧上升
- OpenRCA 的论文方案就是典型例子:每分钟仅取第一条 trace 和 log 进行分析,这种策略必然会漏掉关键证据,例如某个瞬间的峰值 trace 或罕见错误日志
这两层采样叠加,使得大模型得到的输入天然是不完整的“拼图”,最终输出的结论更多是相关性推理而非可验证的因果。
可观测性数据的固有盲区
即使能实现数据完美采集,metrics、traces、logs 也各有盲区:
- Metrics仅显示现象而非根源——Prometheus 只可揭示服务"缓慢"或"错误",但无法解释原因
- Traces存在盲区——调用链只能反映应用层方法埋点路径,任何未埋点的系统调用、GC 停顿、三方库锁竞争都不会出现在 span 中
- Logs 日志依赖开发者意识——关键路径没打日志,或多个组件同时报错,时间戳精度不足都会让因果关系模糊
这些限制意味着:LLM或许能"理解"所有可用数据,最终仍可能给出的仅是合理的症状解释,而非真正的根因。
实际场景验证
案例1:数据盲区击败 LLM
Kubernetes 容器 CPU 限速事故:
- 现象:QPS下降40%,平均延迟上升
- Metrics:Pod CPU 使用率偏低,看起来“系统很闲”,但未采集 throttle 指标
- Traces:数据库、缓存及外部API均正常,应用 span 只是整体变长
- Logs:无错误堆栈
案例2:三方类库内部锁竞争
- SDK封装了连接池与重试机制
- Trace仅覆盖外层业务调用
- Log 未记录内部锁相关细节
传统Metrics+Trace+Log三件套无法暴露此类隐藏问题。
提高准确度的做法:叠加eBPF数据
我们的实践表明:模型规模≠ 根因准确率
真正突破来自更深层次的数据采集。
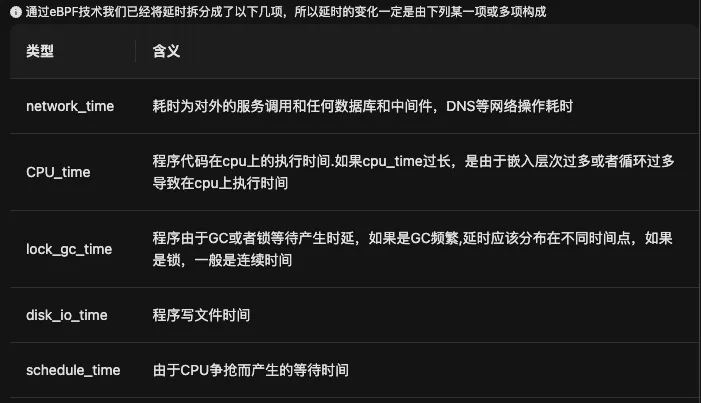
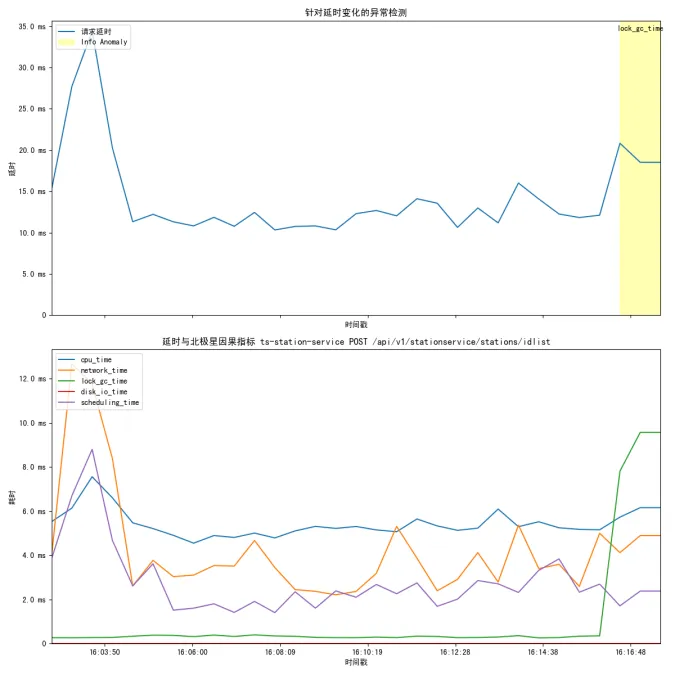
我们利用eBPF技术捕获内核级信号——调度器事件、系统调用、锁竞争与网络重传——针对当前故障现象给出直接的根因,例如“慢了”进一步细化为:
- CPU资源被 throttle
- 网络重传率激增
- 存储I/O等待
- 内核锁竞争
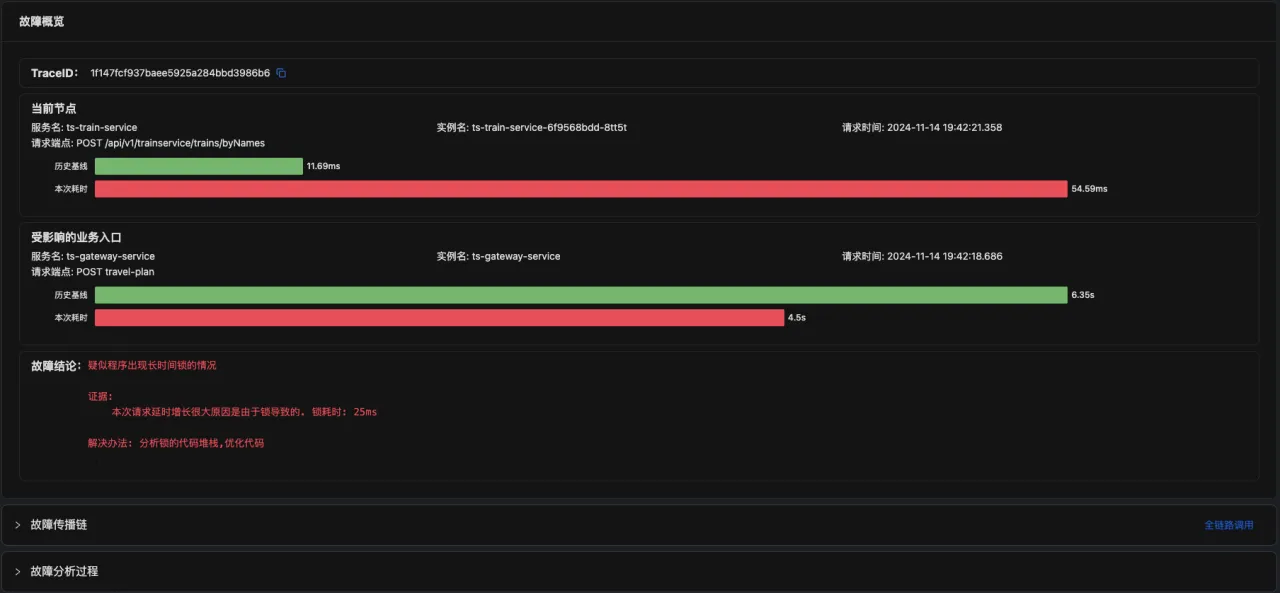
最终给用户的结论是:“应用慢” → “容器 CPU 被 throttle 350ms”这样的确切原因。
我们的架构与集成
为了帮助团队快速落地,我们在设计上保持了兼容与易用:
- 数据采集:eBPF DaemonSet收集内核级信号,与Prometheus/Jaeger/Loki无缝集成
- 分析流程:BPF 指标筛选 → 调用链推理 → 日志语义确认 → LLM 生成自然语言报告
- 部署模式:支持自托管与 SaaS,两者均可在现有 Kubernetes 集群中无侵入部署
典型场景对比
| 故障场景 | 故障场景 | eBPF技术优势 |
|---|---|---|
| 容器CPU throttle | Metrics 平均值被平滑,Trace 无法感知 | 捕捉每次调度延迟和 throttle 时间 |
| 数据库锁等待 | 应用 Trace 仅显示“慢查询” | 捕获内核锁等待与线程阻塞 |
| 内核TCP重传 | 仅见请求超时 | 捕获重传计数与网络抖动 |
| JVM GC暂停 | 需应用层埋点 | 直接检测内核调度停顿 |
技术体验途径
欢迎体验我们的沙箱演示环境,体验如何将故障排查从数小时的推测转化为分钟级的精准定位。
同时欢迎加入我们的技术社区,共同探讨eBPF与LLM融合的最佳实践。