这样的可观测数据平面让AI自动诊断故障

当今云原生和微服务盛行的时代,分布式系统的复杂性与日俱增。保障系统稳定性、快速进行故障诊断成为了运维和开发团队面临的核心挑战。传统的可观测性工具在数据收集和展示方面取得了长足进步,但在应对海量数据、告警风暴以及深度根因分析方面仍显不足。AI,特别是大模型(LLM)的崛起,为自动化故障诊断带来了新的曙光。然而,要充分释放 AI 在可观测性领域的潜力,我们需要一个全新的、为 AI 量身打造的数据平面。
APO (AutoPilot Observability) 正是为此而生。作为一款开源的可观测性平台,APO 并非简单地将 AI 应用于现有数据,而是从根本上重新设计了数据平面,使其更适合 AI Agent 进行分析和推理,从而实现更高效、更精准的自动化故障诊断。本文将深入探讨大模型在可观测性领域的价值,分析为何需要为 AI 定制数据平面,并详细介绍 APO 如何构建一个真正适合 AI 的可观测性数据基础。
LLM:解锁高效数据分析的钥匙
可观测性的三大支柱——Metrics, Tracing, Logging——为我们理解系统状态提供了丰富的数据源。Grafana、Datadog、Jaeger 等工具在可视化和手动分析方面做得非常出色。但面对日益庞大的系统和数据量,传统方法遇到了瓶颈:
- 告警风暴与信息过载:系统抖动或关联故障可能触发大量告警,淹没关键信号,导致运维人员疲于奔命,产生“告警疲劳”。
- 专家经验依赖:精准、快速的故障诊断�往往依赖少数经验丰富的专家,这种能力难以复制和规模化,成为效率瓶颈。
- 高昂的 On-Call 成本:运维人员需要 7x24 小时待命,处理重复性高、压力大的排障工作,时间和心理成本巨大。
大模型驱动的 AI Agent 和 Agentic Workflow 为解决这些痛点提供了革命性的途径。通过将领域知识(如系统架构、常见故障模式)和排障经验(如何关联分析 Metrics, Tracing, Logging)注入 AI Agent,我们可以:
- 自动化初步分析:AI 可以快速扫描海量数据,识别异常模式。
- 执行根因推断:结合上下文信息和知识库,AI 可以提出可能的故障原因。
- 辅助甚至替代重复工作:AI 可以处理大量标准化的排障流程,将工程师从繁琐的任务中解放出来。这不仅能大幅提升故障诊断的效率和准确性,还能显著降低运维压力,提升整体系统稳定性。
为什么需要专为LLM优化的数据平面?
仅仅将现有的可观测性数据(如 Prometheus 的指标、Jaeger 的链路、Loki 的日志)直接喂给大模型,效果往往不尽人意。原因在于,传统的数据平台主要面向人类工程师,侧重于可视化和手动探索,而 AI Agent 对数据的需求有着本质的不同:
- AI 需要“可理解”的数据结构:
AI 并非全知全能,难以直接理解各种异构、原始的数据格式。例如,直接输入原始的 Trace Span 数据,AI 可能难以准确构建服务依赖关系。数�据需要经过预处理和结构化,转换成 AI 更容易理解的格式(如图、结构化指标)。 - 数据间需要显式的关联性:
故障诊断往往需要结合多种数据源。例如,通过指标发现延迟升高,通过链路定位到问题服务,再通过日志查找具体错误。如果这些数据(Metrics, Tracing, Logs)之间缺乏统一的、可关联的标签(如 TraceID、Pod Name、时间戳),AI 就需要执行复杂的跨系统查询和关联操作,效率低下且容易出错。 - 实时性与效率要求数据预聚合与模式提取:
AI Agent 需要快速响应(例如,用户问“服务 X 为什么慢了?”时,期望秒级回答)。这要求数据平面能够提供预先计算好的统计信息和模式,而不是让 AI 每次都从海量原始数据中临时计算。直接分析原始数据不仅消耗大量 Token(成本高昂),速度也无法满足交互式分析的需求。 - AI 对噪声敏感,需要过滤和统计:
单次的网络抖动或偶发的应用错误可能产生“噪声”数据。AI 分析需要基于统计趋势而非孤立事件,以避免误判。例如,需要将零散的错误日志聚合成错误率指标,将单次请求的毛刺延迟平滑为 P99 延迟趋势。
传统数据平面的局限与 APO 的创新设计
了解了 AI 对数据的特殊需求后,我们再来看传统可观测性数据平面(如 Jaeger Trace, Loki Log, Prometheus Metrics)存在的具体局限,以及 APO 是如何通过创新设计来克服这些挑战的:
面向存储/UI 的数据结构对 LLM 不友好
- 问题:传统工具的数据结构设计优先考虑存储效率(如压缩)或 UI 展示(如可视化)。
- 对 AI 的挑战:这些非 AI 优化的数据结构可能导致 AI 理解困难、识别错误,甚至产生“幻觉”。
- APO 的设计:APO 针对性地设计了适合 AI 理解的拓扑和指标数据结构,并通过 Few-shot Prompt Engineering 进行了优化,显著提高了 AI(如 DeepSeek-V2)识别服务拓扑、指标异常的准确率(实验准确率超过 98%)。
数据孤岛与关联性缺失
- 问题:Trace, Log, Metrics 数据通常存储在独立的系统中,缺乏统一的上下文标识进行默认关联。工程师需要手动将 Jaeger 中的延迟、Prometheus 中的 CPU 飙升、Loki 中的错误日志拼接起来分析。
- 对 AI 的挑战:AI 需要执行多次跨系统查询和复杂的关联逻辑,耗时可达秒级甚至分钟级,无法满足实时故障诊断的需求。
- APO 的设计:APO 利用 eBPF 技术,在数据采集层面就将 Trace、Log、Metrics 与丰富的上下文信息(如 Pod、Node、进程、线程、TraceID)进行自动关联。输出的 API 级别拓扑数据本身就包含了关联信息,AI 无需再进行耗时的二次关联。
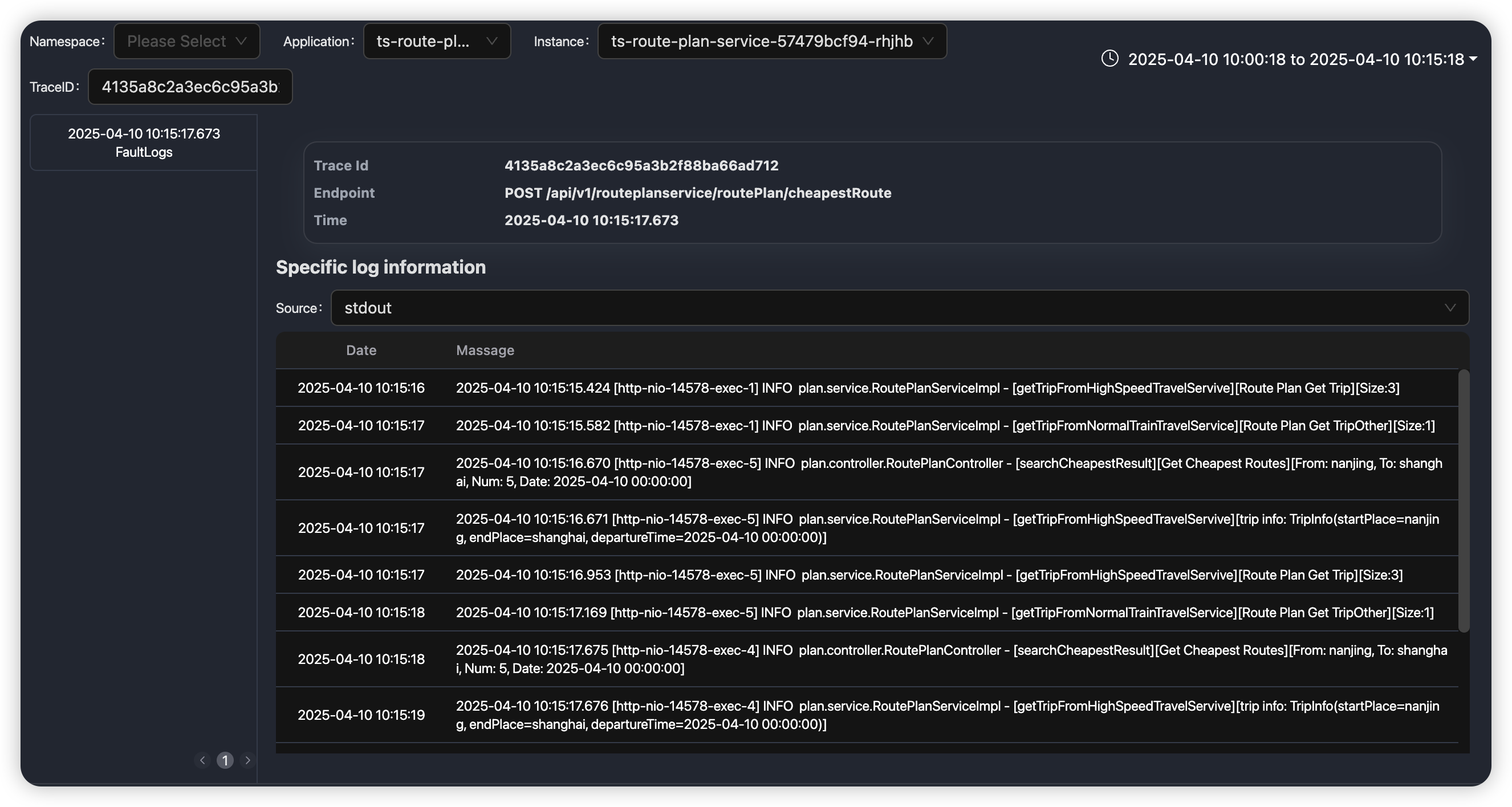
缺乏预处理与模式提取
- 问题:传统平台存储的是原始数据记录(如每个 Span、每条 Log),缺乏统计意义上的模式信息。工程师需要人眼观察火焰图或日志大海捞针。
- 对 AI 的挑战:让 AI 直接处理海量原始数据,计算量巨大,响应缓慢,且成本高昂。
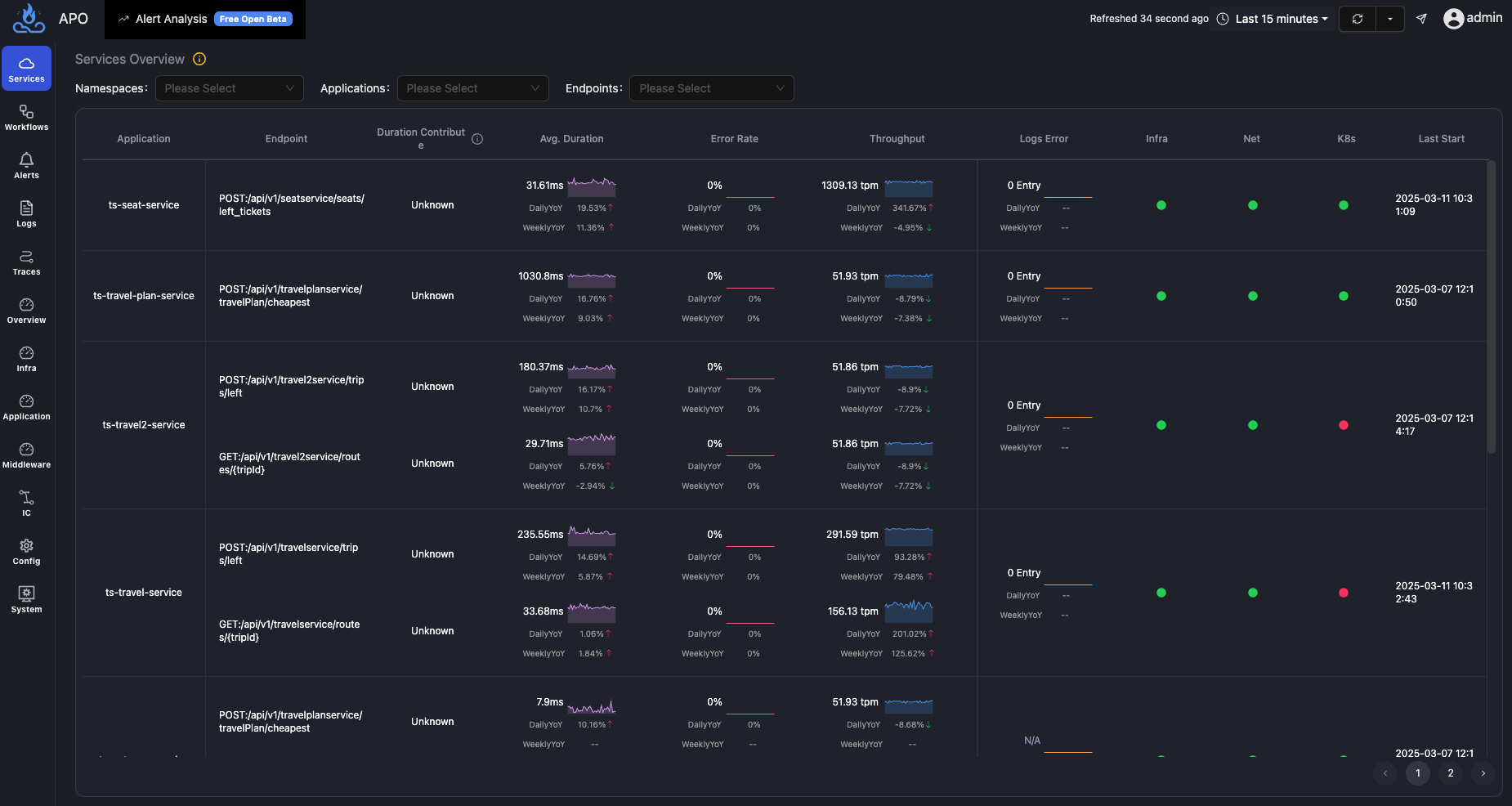
- APO 的设计:APO 在数据处理管道中对 Trace 和 Log 进行预聚合和模式提取。例如,将大量 Trace 预计算为 API 级别的服务调用图和关键性能指标(延迟、错误率、吞吐量),甚至可以预先计算出下游节点对整体延迟的贡献度(如“数据库调用耗时占比 71%”)。AI 可以直接利用这些统计结果快速定位问题方向,而非在原始数据中低效探索。
服务拓扑粒度粗糙,缺乏业务视角
- 问题:基于 Tracing 生成的服务拓扑通常只到服务级别(Service-Level)。当某个服务(如 service-a)出现性能问题时,难以直接判断影响了哪些具体业务功能(如“下单接口”还是“查询接口”),需要进一步下钻分析。
- 对 AI 的挑战:AI 的分析停留在服务层面,无法直接关联到业务影响,需要多轮交互或复杂的下钻查询才能触达问题本质,可能导致分析不准确或效率低下。
- APO 的设计:APO 将服务调用拓扑细化到 API 级别(如
/api/order,/api/product/{id}),更贴近实际业务场景。同时,APO 引入了“业务入口”的概念,将相关的 API 调用链路按业务功能进行分组。这使得 AI 的分析结果更精确,输出的故障诊断报告也更容易被业务和开发人员理解。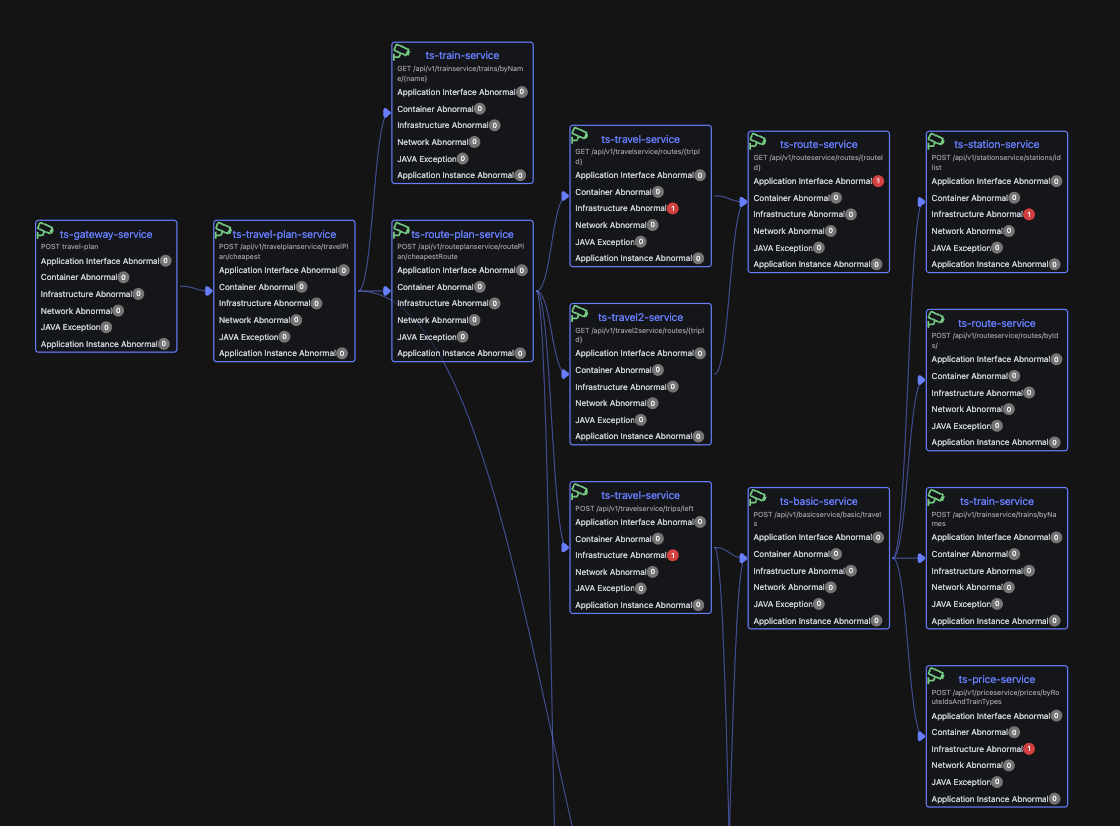
关键数据仅有关联性,缺乏因果性
- 问题:传统可观测性数据(如 Metrics 和 Trace)通常只能展示现象之间的相关性(例如,API 延迟升高与 CPU 使用率升高同时发生),但难以直接证明因果关系。Trace 数据虽然能展示请求路径,但仍可能存在监控盲区(如内核态耗时、锁等待),无法精确分解请求耗时的具体构成。
- 对 AI 的挑战:AI 在缺乏因果性指标的情况下,难以建立标准化的、可靠的故障诊断路径,更多依赖于模式匹配和相关性猜测,导致诊断结论可能不准确或不稳定。
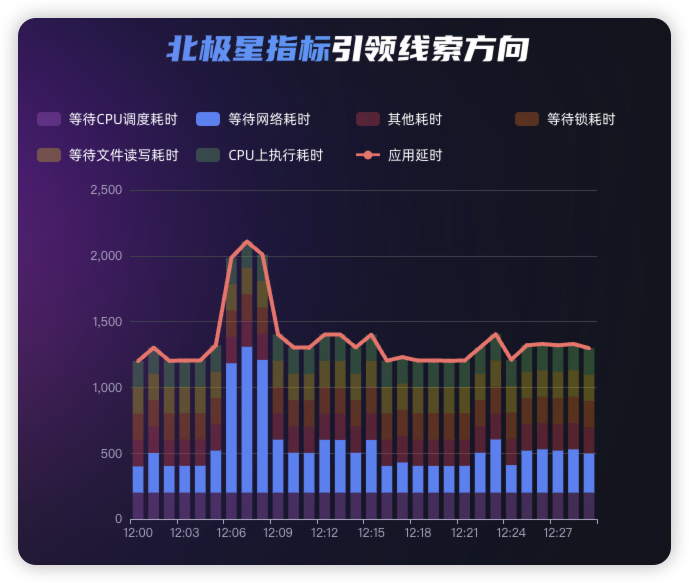
- APO 的设计:APO 再次利用 eBPF 技术深入内核和应用运行时,实现了请求级别的耗时分解(北极星指标)。能够将一个 API 请求的总耗时,精确地分解为 CPU 执行耗时、CPU 等待调度(runqueue)耗时、网络调用耗时、磁盘 I/O 耗时、锁等待耗时等具有明确因果关系的组成部分。这为 AI 提供了一条清晰、标准化的分析路径,能够准确定位性能瓶颈的直接原因,极大提升了故障诊断的准确性和深度。
总结:APO - 为 AI 打造的智能可观测基石
为了让 AI 在可观测性领域发挥最大价值,APO 通过以下关键设计构建了一个面向 AI 的数据平面:
- LLM 友好的数据结构:精心设计拓扑和指标结构,提升 AI 理解准确性。
- eBPF 驱动的数据关联:自动关联 Trace, Log, Metrics 及系统上下文。
- 预处理与模式提取:将原始数据转化为包含统计意义的指标和模式。
- API 级业务拓扑:细化服务调用图至 API 级别,并按业务入口分组。
- 因果性北极星指标:基于 eBPF 实现请求耗时精确分解,直击性能瓶颈。
通过这些专门为 AI 设计的优化,APO 构建的数据平面能够让 AI Agent 更高效、更准确地进行故障诊断和根因定位,显著提升系统稳定性,真正成为工程师的得力助手,将他们从繁琐、重复的排障工作中解放出来。
如果你对利用 AI 提升可观测性和故障诊断效率感兴趣,如果你也希望借助大模型的力量来保障系统稳定性,那么 APO 值得你深入了解和尝试。想了解更多或亲自体验 APO 的魔力吗?欢迎访问我们的项目地址,查阅文档、下载试用,并加入我们的社区,让我们一起探索 AI 可观测性的未来!
