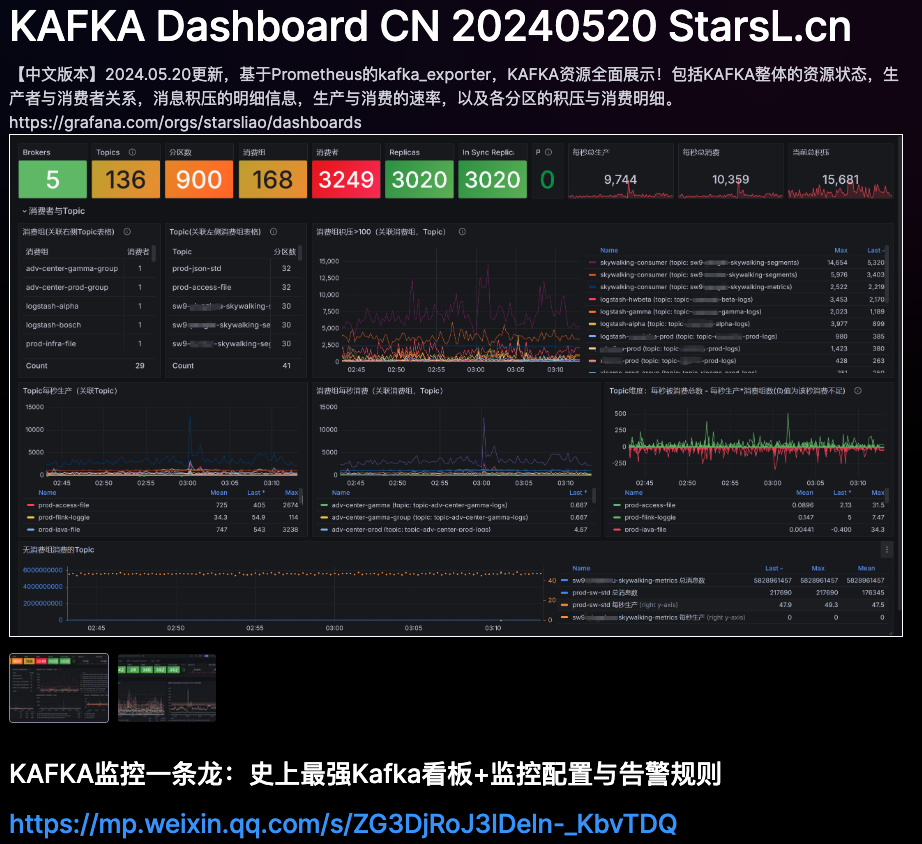
Metrics 作为可观测性领域的三大支柱之一,Metrics数据采集显得尤为重要。传统的prometheus工具采集指标,需要指定�路径抓取,当指标越来越多配置会显得复杂。同时prometheus只能采集指定的指标,当用户需要节点系统相关、中间件等指标还需要引进额外组件。久而久之采集指标配置难以维护。
APO 为了用户更好地一键采集各类指标,选择 Grafana-Alloy 作为APO的指标采集器,兼容OpenTelemtry生态,集成到 APO OneAgent之中,APO OneAgent负责采集所有指标,发送至APO-Server,存储至Victoria-Metrics, APO-front负责展示所有指标。当需要额外采集数据,只需配置OneAgent中Alloy数据采集源,无需更改其他组件,配置灵活,简单易懂。
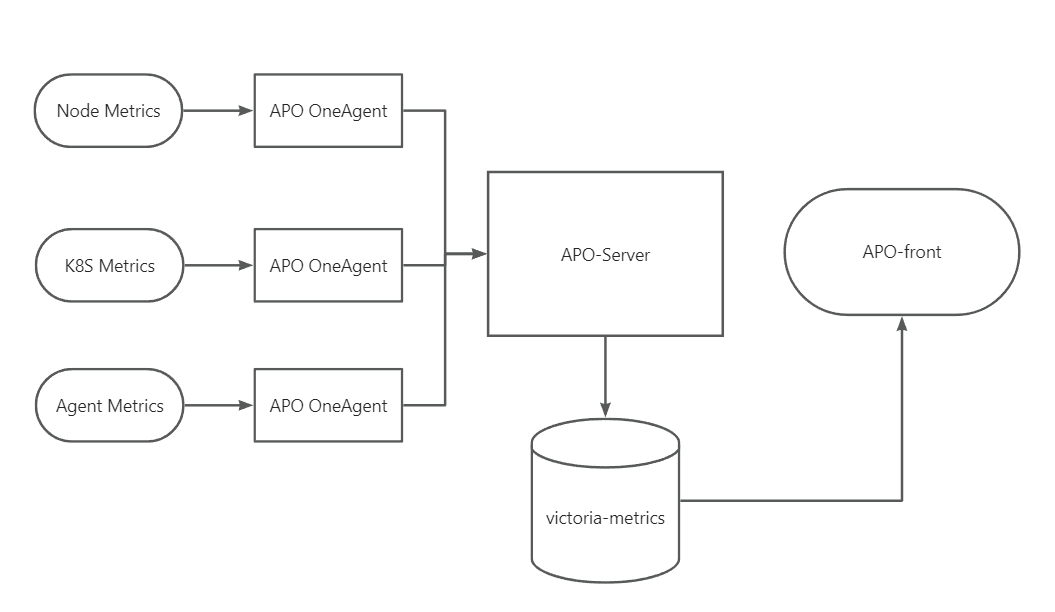
APO 指标采集配置步骤
安装APO-Agent之时,已经安装自带安装了grafana-Alloy。APO启动之后 APO Server并对外提供服务,OneAgent抓取指标,然后发送到 Server,可以在APO Front中的Grafana查看数据。
当用户想要修改指标采集配置,修改 apo-grafana-alloy-config ConfigMap即可(虚机环境下修改apo配置文件config/grafana-alloy/config.alloy)
采集的配置步骤如下:
- 配置APO-server地址
- 配置apo-grafana-alloy-config文件
- grafana查询指标
APO server地址配置
首先需要配置APO Server地址,OneAgent采集指标后将数据发送到APO Server
otelcol.receiver.prometheus "default" {
output {
metrics = [otelcol.exporter.otlp.default.input]
}
}
otelcol.exporter.otlp "default" {
client {
endpoint = "<host-ip>:<port>"
tls {
insecure = true
insecure_skip_verify = true
}
}
}
配置说明:其中 receiver 接收 prometheus 指标,转换成 otel 格式,然后exporter导出发送至APO-Server
APO缺采集配置
以kubernetes环境为例,通常一个集群可能存在如下指标需要采集
- node metrics 节点机器系统相关指标 (磁盘,cpu等信息)
- kubelet metrics 提供 node 和 Pod 的基本运行状态和资源使用情况
- cadvisor metrics container相关的详细资源使用和性能指标数据
机器相关指标采集
jsprometheus.exporter.unix "local_system" {
}
prometheus.scrape "scrape_metrics" {
targets = prometheus.exporter.unix.local_system.targets
forward_to = [otelcol.receiver.prometheus.default.receiver]
scrape_interval = "10s"
}
该组件会采集机器上的各种资源指标
kubernetes 指标采集
其中 discovery.kubernetes 组件负责获取kubernetes信息, APO 这里选择获取node相关的信息
之后采集 kubelet和 cadvisor相关的指标,由于是k8s集群,还需要配置 scheme, bearer_token_file等权限相关信息
discovery.kubernetes "nodes" {
role = "node"
}
prometheus.scrape "kubelet" {
targets = discovery.kubernetes.nodes.targets
scheme = "https"
scrape_interval = "60s"
bearer_token_file = "/var/run/secrets/kubernetes.io/serviceaccount/token"
tls_config {
insecure_skip_verify = true
}
clustering {
enabled = true
}
forward_to = [otelcol.receiver.prometheus.default.receiver]
job_name = "integrations/kubernetes/kubelet"
}
prometheus.scrape "cadvisor" {
targets = discovery.kubernetes.nodes.targets
scheme = "https"
scrape_interval = "60s"
bearer_token_file = "/var/run/secrets/kubernetes.io/serviceaccount/token"
tls_config {
insecure_skip_verify = true
}
clustering {
enabled = true
}
forward_to = [otelcol.receiver.prometheus.default.receiver]
job_name = "integrations/kubernetes/cadvisor"
metrics_path = "/metrics/cadvisor"
}
scrape指标采集
通常用户还会部署一些自定义的探针程序,用于自定义一些监控指标
只需指定 targets 下的 addres 用于指定采集URL, __metrics__path__自定义采集路径,默认为/metircs
prometheus.scrape "agent_metrics" {
targets = [
{
__address__ = "<scrape-path-1>:<port>",
},
{
__address__ = "<scrape-path-2>:<port>",
__metrics__path__ = "/metrics/agent"
},
{
__address__ = "<scrape-path-3>:<port>",
},
]
forward_to = [otelcol.receiver.prometheus.default.receiver]
scrape_interval = "10s"
}
如采集APO node-agent 指标
APO node-agent 用于采集上下游网络指标和进程启动时间指标,路径为 localhost:9500/metrics
prometheus.scrape "agent_metrics" {
targets = [
{
__address__ = "localhost:9408",
}
]
forward_to = [otelcol.receiver.prometheus.default.receiver]
scrape_interval = "10s"
}
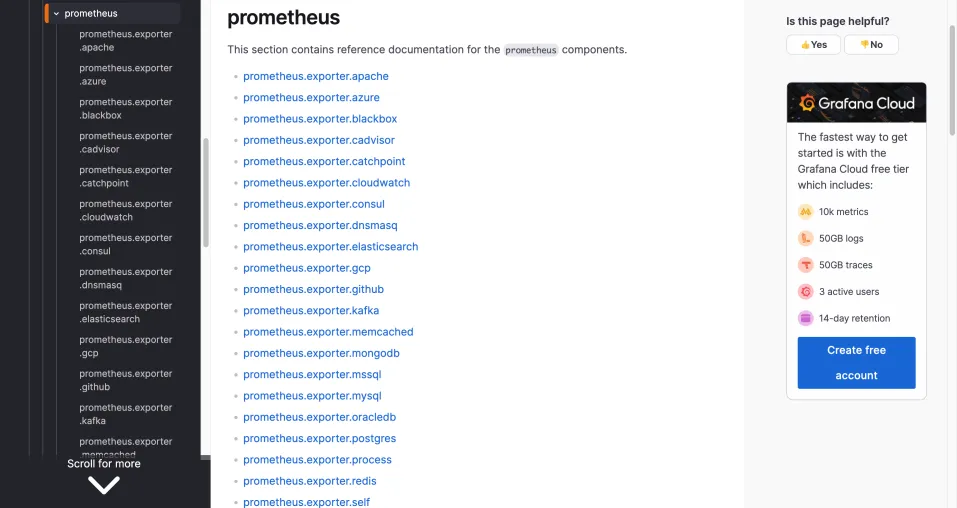
一键采集中间件指标
除了采集基本指标外,用户使用APO还可以根据自己的需求额外配置其他指标采集。
如采集各类 中间件指标
(kafka, redis, mysql, elasticsearch等)
监控 MySQL
1.OneAgent 的 alloy 配置文件添加如下内容,然后重启 OneAgent
# 采集 mysql指标
prometheus.exporter.mysql "example" {
data_source_name = "username:password@(<mysql-url>:3306)/"
enable_collectors = ["heartbeat", "mysql.user"]
}
prometheus.scrape "mysql" {
targets = prometheus.exporter.mysql.example.targets
forward_to = [otelcol.receiver.prometheus.default.receiver]
}
2.APO Front 的 Grafana 中导入 MySQL 模版
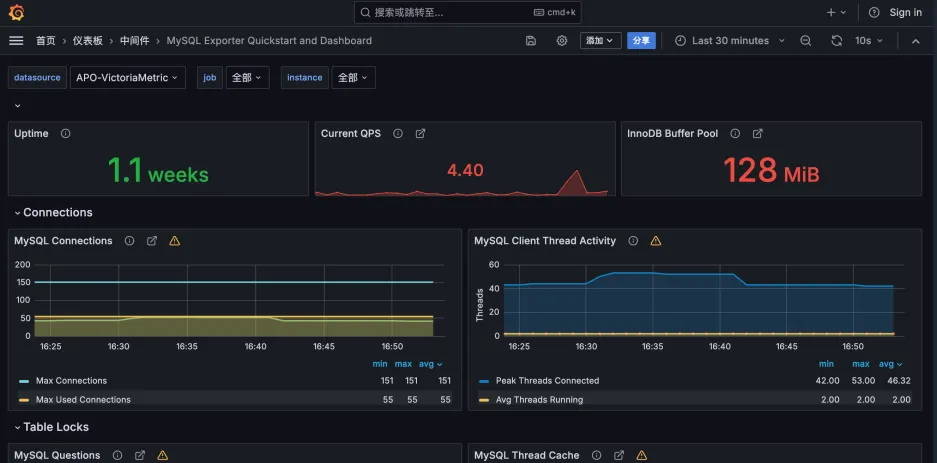
3.验证是否有MySQL指标数据
监控 ElasticSearch
1.OneAgent 的 alloy 配置文件添加如下内容,然后重启 OneAgent
# 采集 elasticsearch指标
prometheus.exporter.elasticsearch "example" {
address = "http://<elasticsearch-url>:9200"
basic_auth {
username = USERNAME
password = PASSWORD
}
}
prometheus.scrape "elasticsearch" {
targets = prometheus.exporter.elasticsearch.example.targets
forward_to = [otelcol.receiver.prometheus.default.receiver]
}
2.APO Front 的 Grafana 中导入 ElasticSearch 模版
3.验证是否有ElasticSearch指标数据
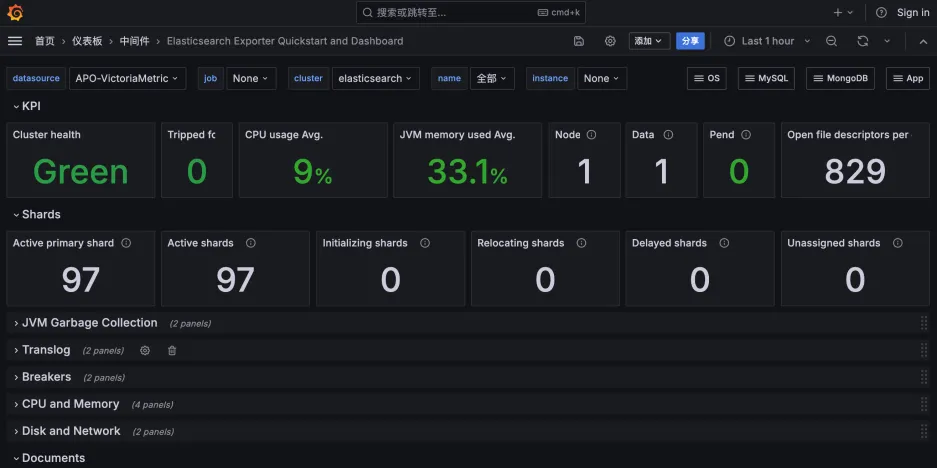
监控 Redis
1.OneAgent 的 alloy 配置文件添加如下内容,重启OneAgent
# 采集 redis 指标
prometheus.exporter.redis "example" {
address = "<redis-url>:6379"
}
prometheus.scrape "redis" {
targets = prometheus.exporter.redis.example.targets
forward_to = [otelcol.receiver.prometheus.default.receiver]
}
2.APO Front 的 Grafana 导入 Redis 模版
3.验证是否有 Redis 指标数据
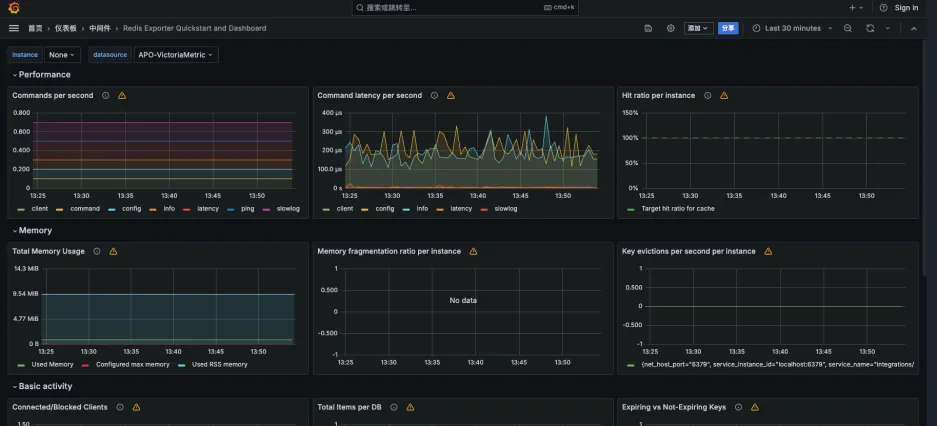
监控 Kafka
1.OneAgent 的 alloy 配置文件添加如下内容,重启OneAgent
# 采集 kafka 指标
prometheus.exporter.kafka "example" {
address = "<kafka-url>:9092"
}
prometheus.scrape "kafka" {
targets = prometheus.exporter.kafka.example.targets
forward_to = [otelcol.receiver.prometheus.default.receiver]
}
2.APO Front 的 Grafana 导入 Kafka 模版
3.验证是否有Kafka 指标数据
更多指标的采集可以参考Grafana-Alloy的官方文档或者咨询我们
Alloy已经支持如下中间件指标采集:
参考资料
otel-collector
otlp-configgrpc
victora-metrics
Sending data via OpenTelemetry
alloy
discovery.kubernetes
otel.receiver.prometheus
prometheus
样例配置文件
logging {
level = "info"
format = "logfmt"
}
otelcol.receiver.prometheus "default" {
output {
metrics = [otelcol.processor.transform.default.input]
}
}
otelcol.processor.transform "default" {
error_mode = "ignore"
trace_statements {
context = "resource"
statements = [
`replace_all_patterns(attributes, "key", "service\\.instance\\.id", "service_instance_id")`,
`replace_all_patterns(attributes, "key", "service\\.name", "service_name")`,
`replace_all_patterns(attributes, "key", "net\\.host\\.name", "net_host_name")`,
]
}
output {
metrics = [otelcol.exporter.otlp.default.input]
}
}
otelcol.exporter.otlp "default" {
client {
endpoint = "<host-ip>:<port>"
tls {
insecure = true
insecure_skip_verify = true
}
}
}
prometheus.exporter.unix "local_system" {
}
prometheus.scrape "scrape_metrics" {
targets = prometheus.exporter.unix.local_system.targets
forward_to = [otelcol.receiver.prometheus.default.receiver]
scrape_interval = "10s"
}
prometheus.scrape "agent_metrics" {
targets = [
{
__address__ = "<scrape-path-1>",
},
{
__address__ = "<scrape-path-2>",
},
{
__address__ = "<scrape-path-3>",
},
]
forward_to = [otelcol.receiver.prometheus.default.receiver]
scrape_interval = "10s"
}
discovery.kubernetes "nodes" {
role = "node"
}
prometheus.scrape "kubelet" {
targets = discovery.kubernetes.nodes.targets
scheme = "https"
scrape_interval = "60s"
bearer_token_file = "/var/run/secrets/kubernetes.io/serviceaccount/token"
tls_config {
insecure_skip_verify = true
}
clustering {
enabled = true
}
forward_to = [otelcol.receiver.prometheus.default.receiver]
job_name = "integrations/kubernetes/kubelet"
}
prometheus.scrape "cadvisor" {
targets = discovery.kubernetes.nodes.targets
scheme = "https"
scrape_interval = "60s"
bearer_token_file = "/var/run/secrets/kubernetes.io/serviceaccount/token"
tls_config {
insecure_skip_verify = true
}
clustering {
enabled = true
}
forward_to = [otelcol.receiver.prometheus.default.receiver]
job_name = "integrations/kubernetes/cadvisor"
metrics_path = "/metrics/cadvisor"
}
# 采集 mysql指标
prometheus.exporter.mysql "example" {
data_source_name = "username:password@(<mysql-url>:3306)/"
enable_collectors = ["heartbeat", "mysql.user"]
}
prometheus.scrape "mysql_metrics" {
targets = prometheus.exporter.mysql.example.targets
forward_to = [otelcol.receiver.prometheus.default.receiver]
}
# 采集 elasticsearch指标
prometheus.exporter.elasticsearch "example" {
address = "http://<elasticsearch-url>:9200"
basic_auth {
username = USERNAME
password = PASSWORD
}
}
prometheus.scrape "demo" {
targets = prometheus.exporter.elasticsearch.example.targets
forward_to = [otelcol.receiver.prometheus.default.receiver]
}