APO全量日志对接logstash和fluent日志采集生态

APO 日志介绍
采集流程图
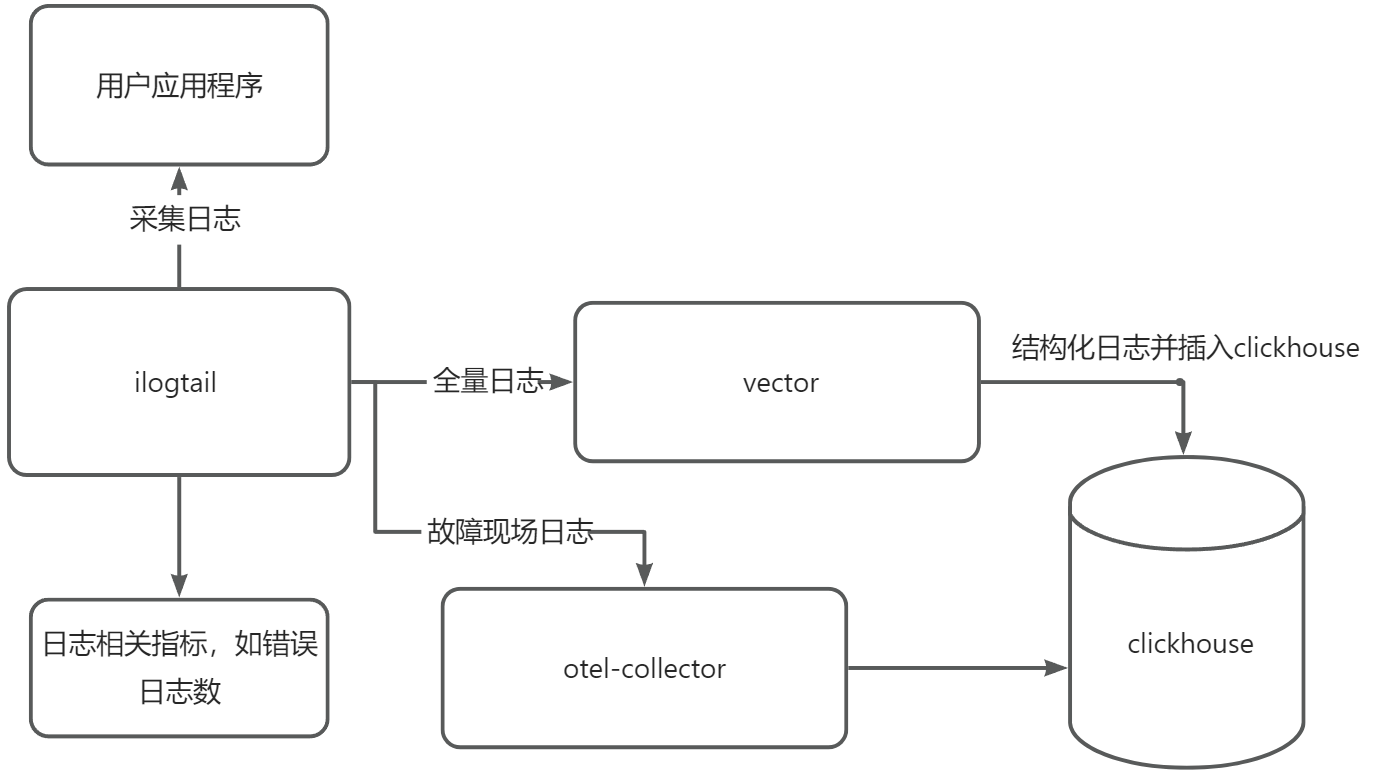
APO 使用 ilogtail 作为日志采集组件并改造支持额外功能, 在 vector 中进行日志结构化处理。
APO 日志功能
- 日志指标
统计日志数并生成日志数指标。出现错误日志时,计算日志错误指标
- 故障现场日志
应用程序出现慢或者错误trace时,将这段时间内的日志收集并写入clickhouse中。使用 k8s 信息或 pid 信息关联故障链路和故障现场日志
- 全量日志
1.APO日志界面中提供了为不同应用配置不同的日志解析规则,vector 根据解析规则将日志结构化,解析规则中提取的日志字段会单独成列加快查询
2.日志库支持全文检索和查看日志上下文
APO 日志中使用logstash或fluent
用户如果已经使用 logstash 或者 fluent 生态的日志采集组件,可直接与APO日志进行对接。但需要注意的是,使用对接日志采集组件可能会导致某些信息的缺失或功能无法使用。
APO 日志仅全量日志功能可用
APO 日志不可用功能
- 故障现场日志:APO 使用改造后的 ilogtail 添加 K8S 信息或 PID 信息,使用 logstash 或 fluent 替换 ilogtail 会导致在 K8S 和虚机环境中均无法关联链路和日志信息,导致功能缺失
- 日志指标:APO 使用 ilogtail 统计日志指标,使用 logstash 或 fluent 替换 ilogtail 导致该功能缺失
logstash 或 fluent 需填充 K8S 相关信息
确保在 Kubernetes 环境中部署日志采集组件,同时日志需要填充以下标签信息,同时这些标签信息需要适当的重命名。重命名具体实现可以参考后续提供的 vector 配置示例。
- container.name -> 容器名
- container_id -> 容器ID
- k8s.namespace.name -> Kubernetes 命名空间
- k8s.pod.name -> Pod 名称
- host.ip -> 节点 IP
- host.name -> 节点名称
- source -> 文件路径
- content -> 日志内容
- timestamp -> 日志采集时间
APO 接入日志采集组件示例
当用户在 K8S环境中使用 Logstash 生态(如 filebeat, logstash)或 Fluent 生态(如 fluentd, fluent-bit),可参考如下示例接入 APO 日志。
Logstash 生态示例 - 使用 Filebeat
1.设置 NODE_IP 和 NODE_NAME 环境变量
env:
- name: NODE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
- name: NODE_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.hostIP
2.配置 Filebeat
日志采集组件如果和 APO Server 不在同一集群,output.logstash 中的 hosts URL 设置为 Server 所在节点IP,Port 改为 30310
filebeat.inputs:
- type: filestream
id: kubernetes-container-logs
fields:
host.ip: ${NODE_IP}
fields_under_root: true
paths:
- /var/log/containers/*.log
parsers:
- container: ~
prospector:
scanner:
fingerprint.enabled: true
symlinks: true
file_identity.fingerprint: ~
processors:
- add_kubernetes_metadata:
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: "/var/log/containers/"
output.logstash:
hosts: ["apo-vector-svc.apo:4310"]
3.更新 apo-vector 的 ConfigMap
# 替换sources内容
sources:
logstash_log:
type: logstash
address: 0.0.0.0:4310
# 替�换 transforms 的 flatten_logs 内容
transforms:
flatten_logs:
type: remap
inputs:
- logstash_log
source: |
."host.name" = .host.name
."host.ip" = .host.ip
.content = .message
."_source_" = .stream
."_container_id_" = .container.id
."k8s.namespace.name" = .kubernetes.namespace
."k8s.pod.name" = .kubernetes.pod.name
."container.name" = .kubernetes.container.name
del(.agent)
del(.log)
del(.message)
del(.kubernetes)
del(.container)
del(.input)
del(.orchestrator)
del(.ecs)
del(.host)
del(.@metadata)
del(.stream)
# 调试日志信息,日志采集对接成功后可移除
sinks:
to_print:
type: console
inputs:
- flatten_logs
encoding:
codec: json
json:
pretty: true
Fluent 生态示例 - 使用 Fluent Bit
1.设置 NODE_IP 和 NODE_NAME 环境变量
env:
- name: NODE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
- name: NODE_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.hostIP
2.配置 Fluent Bit 的解析、 输入、过滤器和输出配置。日志采集组件如果和 APO Server 不在同一集群,OUTPUT 中的 Host 设置为 Server 所在节点IP,Port 改为 30310
[Input]
Name tail
Path /var/log/containers/*.log
Refresh_Interval 10
Skip_Long_Lines true
Parser cri
Tag kube.*
[Filter]
Name kubernetes
Match kube.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Labels false
Annotations false
[FILTER]
Name modify
Match *
Add host_ip ${NODE_IP}
[OUTPUT]
Name forward
Match *
Host apo-vector-svc.apo
Port 4310
3.修改 apo-vector 的 ConfigMap 以匹配 Fluent Bit 输出格式
# 替换sources内容
sources:
fluent_log:
type: fluent
address: 0.0.0.0:4310
# 替换 transforms 的 flatten_logs 内容
transforms:
flatten_logs:
type: remap
inputs:
- fluent_log
source: |
."host.name" = .kubernetes.host
."host.ip" = .host_ip
."_source_" = .stream
.content = .message
."_container_id_" = .kubernetes.docker_id
."k8s.namespace.name" = .kubernetes.namespace_name
."k8s.pod.name" = .kubernetes.pod_name
."container.name" = .kubernetes.container_name
del(.kubernetes)
del(.stream)
del(.message)
del(.host)
del(.host_ip)
# 调试日志信息,日志采集对接成功后可移除
sinks:
to_print:
type: console
inputs:
- flatten_logs
encoding:
codec: json
json:
pretty: true
APO 日志对接问题排查
配置修改后,如果 APO 日志界面仍未出现日志,需要进行排查
问题1 vector中有日志事件,但APO 界面无日志
需要通过vector日志查看日志事件格式是否正确
vector 配置中添加调试日志信息配置。观察vector日志中事件,通常正确的日志信息包含如下信息。
{
"_container_id_": "852a7484f030",
"_source_": "stdout",
"container.name": "java-demo-1",
"content": "{\"level\":\"ERROR\",\"method\":\"org.apache.juli.logging.DirectJDKLog.log\",\"msg\":\"Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception [Request processing failed; nested exception is org.springframework.web.client.ResourceAccessException: I/O error on GET request for \\\"http://localhost:8082/api/jpa-demo/sleep\\\": Read timed out; nested exception is java.net.SocketTimeoutException: Read timed out] with root cause\",\"thread\":\"http-nio-8081-exec-2\"}",
"host.ip": "192.168.1.69",
"host.name": "node-69",
"k8s.namespace.name": "default",
"k8s.pod.name": "apo-java-demo-b7994cc54-ss58f",
"timestamp": "2024-09-25T07:46:38.146950792Z"
}
如果发现信息缺失,请参考填充 K8S 相关信息确保所有信息填充
问题2 vector日志中未收到任何日志事件
需要排查一下对接采集组件是否可以正常写入vector
请查看filebeat,fluent-bit等采集组件等日志信息
APO介绍:
国内开源首个 OpenTelemetry 结合 eBPF 的向导式可观测性产品
apo.kindlingx.com