什么是北极星排障指标体系
简介
北极星排障指标体系是一组指向性明确的指标,通过这些标准化的指标体系指出问题根因和结论,在排障过程中给予参与人员明确的方向指导,给出问题的明确界限。通过北极星排障指标体系,可以根据企业业务流程和自身工具情况构建出标准化的排障流程,进而真正能够在实际生产环境中落地1-5-10。
北极星指标
北极星指标也叫唯一关键指标(OMTM,One metric that matters),产品现阶段最关键的指标,其实简单说来就是公司制定的发展目标,不同阶段会有不同的目标。为什么叫“北极星”指标,其实大概的寓意就是要像北极星一样指引公司前进的方向,目标制定最好是能符合SMART原则,具体指具体(Specific)、可以衡量的(Measurable)、可实现(Attainable)、相关性(Relevant)、有明确的截��止期限(Time-bound)。 北极星指标通常具有三个价值,指引未来、团队协同和结果导向。例如电子商务类的商业模式,他们的核心价值通常是用户下单购物,因此常见的北极星指标是GMV或订单量。对于媒体网站或内容类商业框架,企业更关注用户的阅读和创作,那么北极星指标通常为阅读量、停留时长、作品数等。而即时通讯类APP的核心价值是用户间的信息传输,所以企业通常会把消息数、发送消息的用户数等作为北极星指标。
北极星排障指标
目前问题
- 传统可观测性工具存在盲区
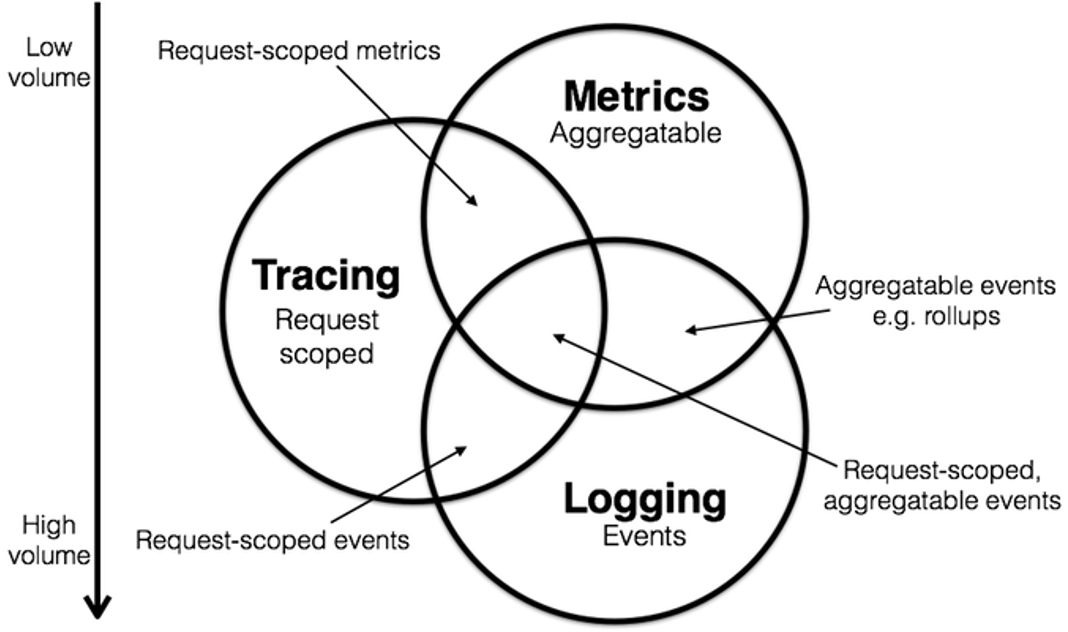
目前虽然 Tracing、Metrics、Logging 已经成为绝大多数云原生业务的标配,但在实际生产环境中可观测性工具仍旧存在着很多盲区。实际应用过程中,大多数情况下往往仍旧采用填坑的方式,一方面在有可能有问题的部分增加日志及相关追踪信息,另一方面根据历史数据和经验在发生过问题的部分增加指标和相关事件记录信息,导致很容易丢失故障现场信息,同时无法真正发现问题根因。同时,传统可观测工具提供和记录的各类相关指标往往只有专家才能对其进行解读,并将其理解运用解决生产环境中的实际问题,这便使得数据、指标记录了,但是盲区却仍旧存在。
- 排障周期不可预期
排障周期是指从发现问题到最终解决问题的整个过程。在理想情况下,这个周期应该是可预测的,这意味着团队可以估计出从识别问题到解决问题所需的时间。然而,在实际操作中,排障周期往往是不可预期的。主要原因有:排障极大程度上依赖参与排障人员的主观经验,排障知识的积累因人而异,导致其周期没法预估,受当次故障处置参与人员的经验和能力影响大;另一方面排障周期往往取决于故障发生时或发生前先看到什么现象,其会对处置人员的定位思路和处置决策产生影响,存在一定运气成分,进而使得同样的故障,即使是相同的根因,也会由于不同的现象导致排障周期不同。
北极星排障指标体系理论
基于目前的问题及困境,龙蜥社区与 Kindling 社区联合发布了北极星排障指标体系,通过将传统北极星指标的概念和方法论引入到排障流程中,构建出了一套排障指标体系与标准化的步骤,力求在目前困境中找到一条可操作可落地的标准化排障之道。
北极星排障指标-CPU时间
程序在CPU资源上所消耗的时间
- OnCPU
程序代码执行所消耗的CPU cycles,可以通过程序火焰图确认代码在 CPU上执行消耗的时间与代码堆栈.
- Runqueue
线程的状态是Ready,如果CPU资源是充分,线程应该被调度到 CPU上执行,但是由于各种原因,线程并未调度到CPU执行,从而产生的等待 时间。
北极星排障指标-网络时间
网络时间属于两次OnCPU时间之间的OffCPU时间
- 网络时间打标过程
第一次OnCPU最后一个系统调用执行为sock write与第二次 OnCPU第一个系统调用为sock read,也可以理解为网络包出网卡至网络包从网卡收回的 时间。
- 网络时间分类
DNS,TCP建连,常规网络调用
北极星排障指标-存储时间
属于两次OnCPU时间之间的OffCPU时间
- 存储时间打标过程
第一次OnCPU最后一个系统调用执行为VFS read/write与第二次 OnCPU第一个系统调用为VFS read/wirte。
- 存储时间真实情况
存储真实执行情况,由于内核的pagecache存在,所以绝大多数VFS read/write从程序视 角看:执行时间不超过1毫秒。
北极星排障指标-等待时间
- futex
通常指的是一个线程在尝试获取一个futex锁时因为锁已经被其他线程占用而进入等待状态的时间。在这段时间内,线程不会执行任何操作,它会被内核挂起。
- mutex_lock
线程在尝试获取互斥锁时��,因为锁已经被其他线程持有而进入等待状态的时间长度。这段时间对于程序的性能至关重要,因为在等待期间,线程不能执行任何有用的工作。
实现要点
- OnCpu时间
进程真正获取cpu的时间,从获取cpu(sched_switch)到失去cpu(sched_switch)的时间。
- Runqueue时间
进程在运行队列中的时间,记录线程从被唤醒(sched_wakeup)到获取cpu(sched_switch)的时 间;如果线程主动让出cpu,则记录失去cpu到重新获取cpu的时间。
- 等待时间
进程从失去cpu(sched_switch)到被唤醒(sched_wakeup)的时间,然后通过sched_switch off 时抓的堆栈,进行阻塞原因分析。
- 等待网络的时间
通过系统调用来辨别:__sys_recvfrom, sendmsg, recvmsg。
- 等待存储的时间
通过系统调用来辨别: vfs_write, vfs_read, do_sys_openat。
- 等待锁时间
futex: futex_wait, mutex_lock lock: mutex_lock, mutex_lock_interruptible
- server端实际执行时间
应用采用同步方式向其他服务器发送请求或者发起新链接,或者进行 DNS,记录发送请求时的四元组: S1=(source_ip, source_port, dest_ip, dest_port);在 server 端进行监听,若获取的四元组 S2 和 S1 相同,则记录 server 端开始执行的时间戳 T1;当 server 端进行请求响应,获取四元组 S3,若 S3 的四元组与 S1 对应相同,则记录结束执行的时间戳 T2;T2 - T1 则为 server 端实际执行时间。

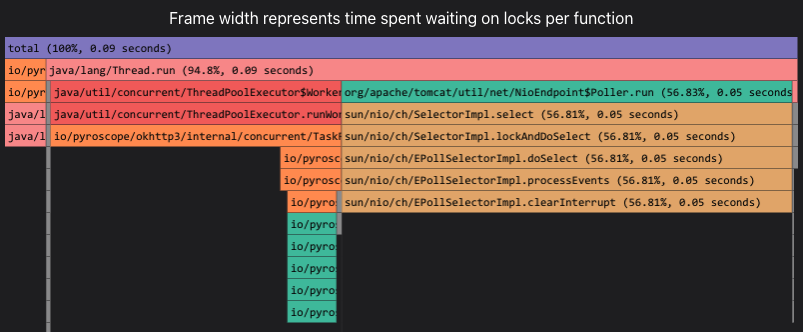

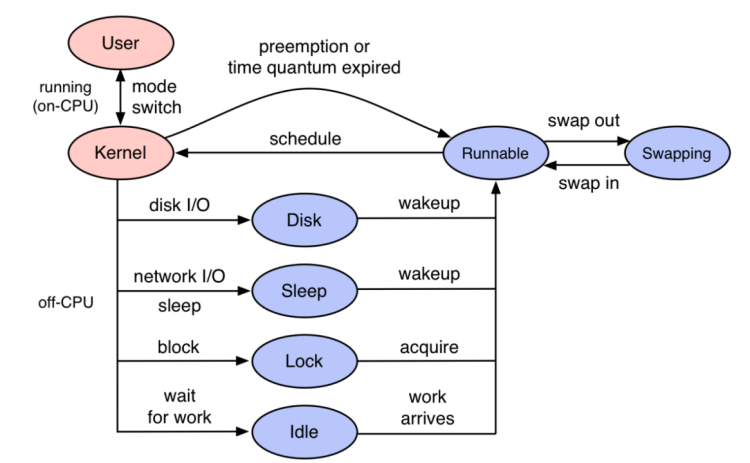
 如果使用Trace-Profiling,应该能够明确给出当时业务是卡住下列事件之一
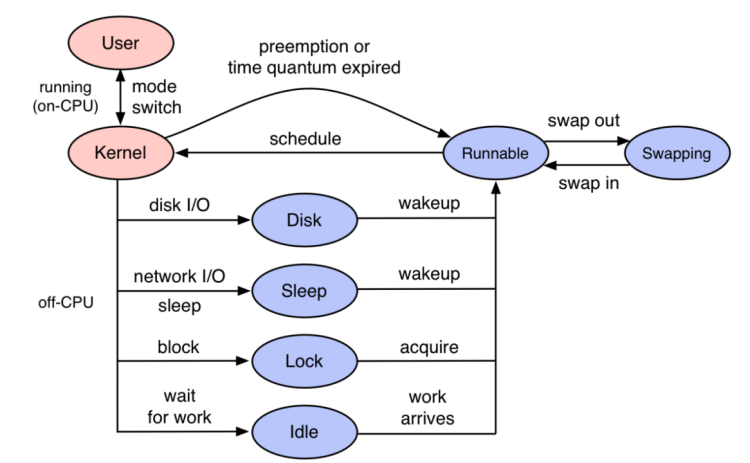
如果使用Trace-Profiling,应该能够明确给出当时业务是卡住下列事件之一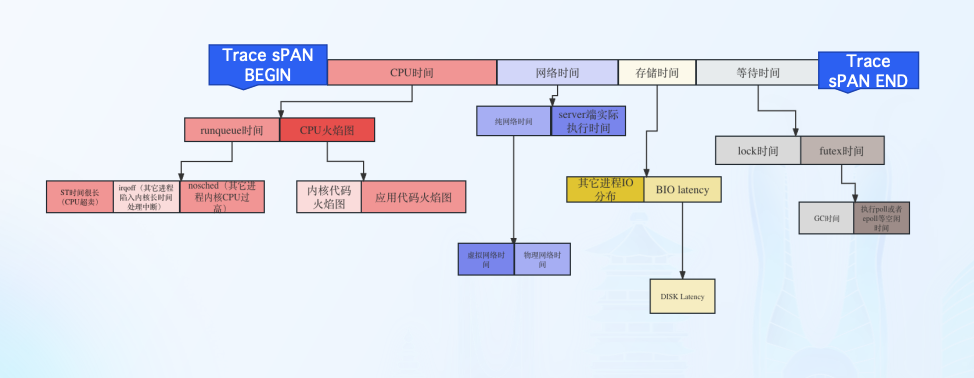






 程序代码是以线程为载体进行执行,线程执行过程中可能会因为disk、sleep、lock、idle等各种原因放弃CPU上执行转入等待状态。
等待事件完成之后,线程状态变成Runnale等待cpu调度,如果此时CPU资源紧张,就会出现很长的等待时间。
开源项目 Kindling 的 trace-profiling 就是利用eBPF获取各个点位信息,同时结合Trace,真实地还原出程序的执行过程。从 Kindling 的 trace-profiling 去看trace的完整执行过程,每一个毫秒都知道程序在干什么。
程序代码是以线程为载体进行执行,线程执行过程中可能会因为disk、sleep、lock、idle等各种原因放弃CPU上执行转入等待状态。
等待事件完成之后,线程状态变成Runnale等待cpu调度,如果此时CPU资源紧张,就会出现很长的等待时间。
开源项目 Kindling 的 trace-profiling 就是利用eBPF获取各个点位信息,同时结合Trace,真实地还原出程序的执行过程。从 Kindling 的 trace-profiling 去看trace的完整执行过程,每一个毫秒都知道程序在干什么。