如何找到并发请求中的锁

经常听大家讲到在业务平峰期间一切正常,但当并发上升时用户端延时上升,体验急剧下降,往往这时候是由于应用锁导致。例如用户端访问时延是3s,数据库访问耗时500ms,而数据库索引和慢请求也都已优化,那么其他的2.5s到底是消耗在哪里?如果这其中的体验差距是由锁导致,那么又该如何快速定位这些锁,并将他们消除呢?
一方面受制于现有可观测性工具能力的限制,我们并不能有效地发现然后将其解决,另一方面传统的压测方法也并不能完美复刻生产环境的全部真实情。对于这些并发上升导��致的问题,以及应用中看不见的锁,Kindling-OriginX 提出新的解决方法。
历史经验不准
实际工作中往往习惯于使用个人历史经验判断是哪些服务出现故障,哪些应用容易出现锁,微服务架构下,应用缩容扩容,应用实例数的不同,相同的问题常常表现出不同的现象。这就导致使用历史经验判断并不能有效的找到问题。
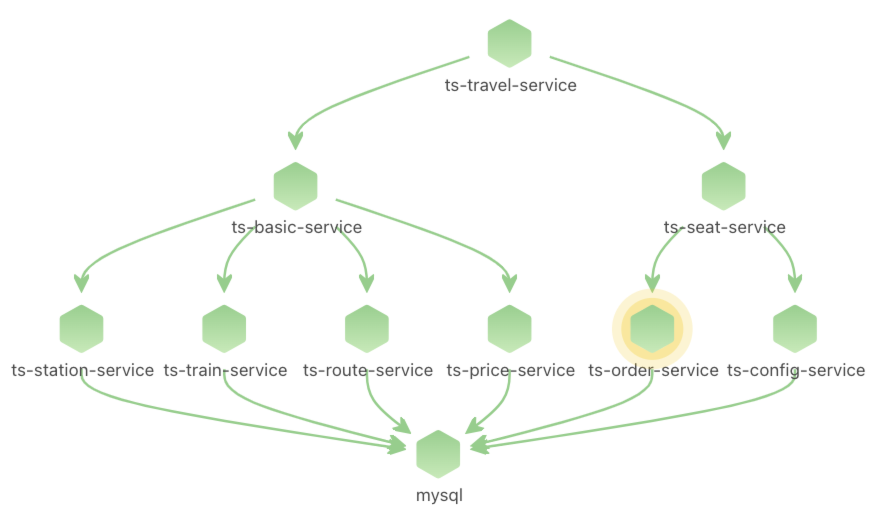
Kindling-OriginX 能够快速给出全部异常节点的根因报告,同时报告已给出分析结论,不论问题表现的现象如何,用户都能够快速简单的进行统一分析。例如下图的拓扑结构中,同样的性能问题,因为每个节点的实例数的不同,都会导致表现出不同的现象。Kindling-OriginX 已经分别对报告做了聚合,对数据做了分析,用户只需要简单查阅报告即可。
无法找到锁在哪里
实际生产环境中,一方面不可能事无巨细将应用所有变化都记录在日志中,另一方面很多数据也无法直接进行观测得到。往往知道应用里有锁,但是根本没有有效手段去找到锁在哪里。
Kindling-OriginX 通过实时监控和深度分析,快速识别性能瓶颈的同时,对每一个慢请求从系统调用级别进行拆解分析,究竟是GC、CPU等待、或是代码质量问题一目了然。
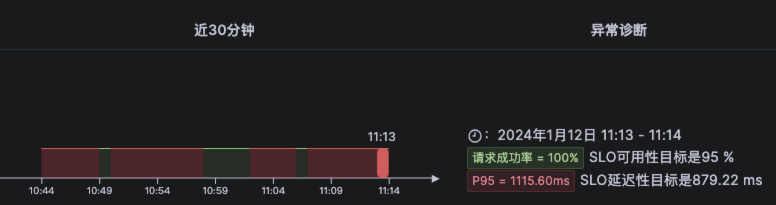
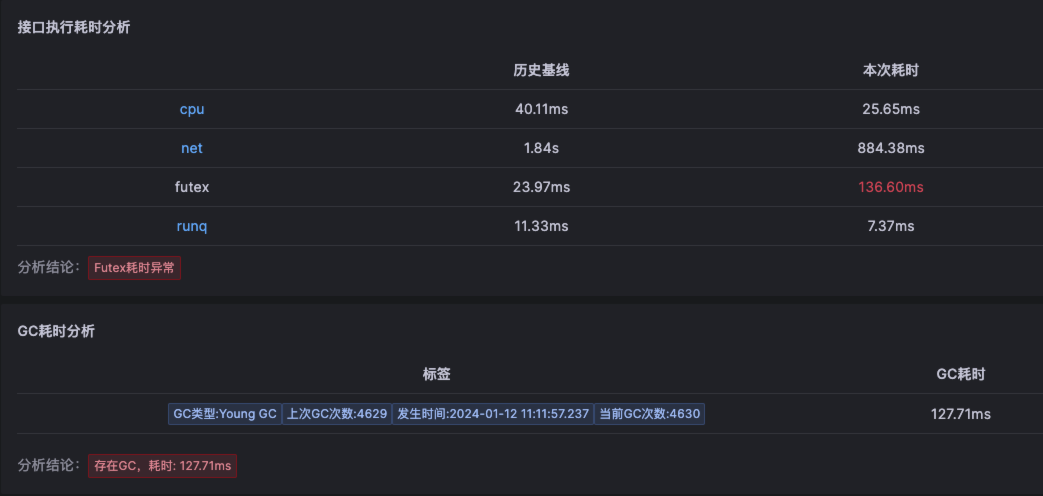
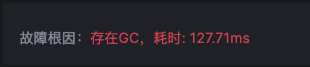
例如在下图示例中,futex耗时远大于历史基线值(futex是一种用于用户空间应用程序的通用同步机制,这里简单起见可以将其理解为一种锁机制),再结合自动化GC关联分析,得出故障根因是有锁,且该锁是由于系统发生GC导致
人工分析不可行
实际生产环境中,时时刻刻产生大量的 Trace 数据,要从这些大量的低价值数据中找出问题的根源,需要耗费大量时间进行人工分析,几乎不可能通过人工的方式找到关键数据。这不仅增加了工作负担,而且没有任何时效性可言。
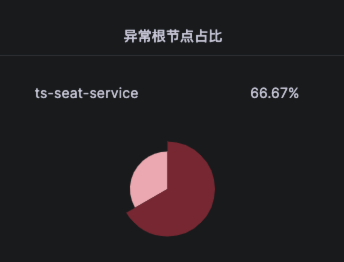
Kindling-OriginX 通过异常占比与报告收敛的方式进行数据聚合,即使在大量 Trace 数据的情况下,也能对数据情况一目了然,快速找到所关心的数据。

干扰数据导��致无法找到锁
系统整体性能急剧下降时,所有机器往往都处于高负载状态,越多的连接也会导致CPU需要处理的上下文切换越多,内存对象频繁的创建和释放也可能会导致出现因垃圾收集(GC)造成的延迟。这些干扰信号都可能会导致真正的问题被掩盖。
Kindling-OriginX 针对干扰数据多的问题,一方面将报告数据收敛聚合,避免数据过多造成的干扰,另一方面报告中直接给出根因结论,只需快速查阅就能得到结论,无需再进行人工分析和有效性判别。
传统的可观测性工具在面对并发请求中的锁时无法提供有效的定位方式和解决方案,个人历史经验的误判,海量数据的分析、噪声信号的干扰,以及在动态复杂环境下的有效诊断,都要求更先进的技术和方法。Kindling-OriginX 提供全新的自动化、智能化关联分析 Log、Metrics、Trace 数据解决方案,通过 eBPF 和TraceProfiling 技术还原每一次请求过程,精准定位分析并发上升时应用中的各类问题。