解密北极星指标体系如何实现根因分析
解密北极星指标体系如何实现根因分析

在之前的文章中提过我们的观点,AIOps实践中常见的挑战:故障根因与可观测性数据的割裂 认为依赖算法给出根因建议缺乏可解释性,本篇文章重点介绍下我们的根因定位的思路, 按照这个思路去快速实现根因定位,我们认为是能够落地1-5-10的,如果对文章的思路有任何疑问,欢迎联系我们一起探讨。

为什么高效定位故障根因定位难
排障过程本质是我们拿着程序最后的执行结果去猜测验证程序执行异常的过程
当前人为定位故障主要依赖于指标告警,但是现在绝大多数指标反映的程序执行结果,并未对程序执行过程提供更多的信息。举例说明,CPU利用率是程序执行完代码之后的CPU的被使用的反映,内存利用率是程序已经使用内存的执行结果,所以排障过程本质是我们拿着程序最后的执行结果去探索程序执行异常的过程。
在探索程序执行异常的过程中,有哪些数据能反映程序执行过程呢?能反映程序执行过程数据目前常规就是日志以及各种事件(将APM数据称之为程序执行的事件数据,比如执行的代码堆栈、慢方法等)。
由于可观测性盲区的存在导致猜测验证过程依赖专家经验
不管是日志、APM数据所反映出程序执行过程其实都存在很多盲区,关于程序执行盲区,可以参考团队在KubeCon,eBPF大会等会议上分享内容。也可以参考可观测性工具的盲区与故障排查困局 这篇文章,里面有更加详细讨论。
什么数据能够对故障定位起到决定性作用
基于以上的论述,我们认为要能够实现故障定位的关键数据要满足以下特点:
- 覆盖程序执行的盲区,不管程序任何操作都应该有数据能够和程序执行过程对应起来
- 数据分类要足够抽象,便于排障的人员能理解,这点很重要因为团队之前拿着程序依赖内核的行为数据去和用户沟通之时,绝大多数开发不能理解这些数据,就别提用这些数据进行排障
- 每个数据分类要足够隔离,不要相互影响
北极星指标体系是故障定位中的关键数据
北极星指标体系是基于TSA方法论得到的程序执行过程完整数据,关于TSA的方法论,有兴趣的朋友可以参考大神的博客,https://www.brendangregg.com/tsamethod.html 也可以参考这篇公众号的文章,TSA方法:基于线程时间分布分析性能瓶颈http://u6v.cn/5yDFVr
从这套方法论来看,采集的数据是覆盖了程序的完整执行过程,第一个要求满足了,那第二个要求就是我们将程序与内核交互的数据进行抽象而得到的。第三个就是因为我们是根据进程在操作系统上执行On与Off数据而来,所以数据是隔离没有影响的,这里也许有内核专家会疑惑比如由于网络包产生的软中断会消耗很多的CPU,所以CPU时间和网络时间不能隔离,但是我们是基于On与Off数据而来,由于网络包产生的软中断CPU消耗会被计算到ON的CPU时间之上,并能通过内核火焰图反应出最终的问题。
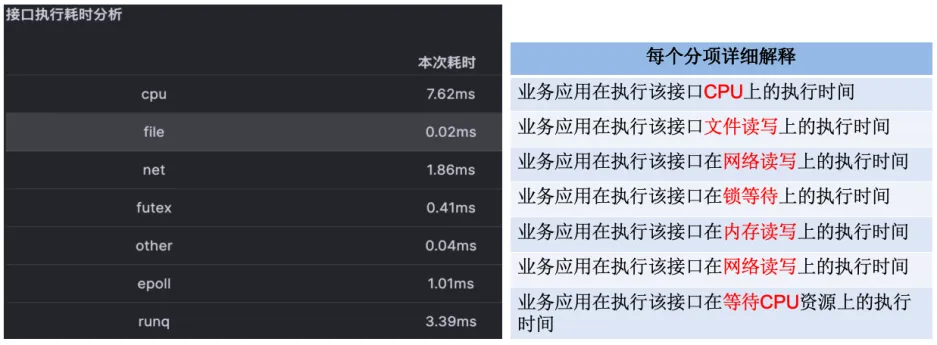
一次接口执行的北极星指标
围绕着北极星排障指标的建模
在有了一次接口执行的北极星数据之后,我们可以对历史数据进行基线判断,也就可以形成以下的数据
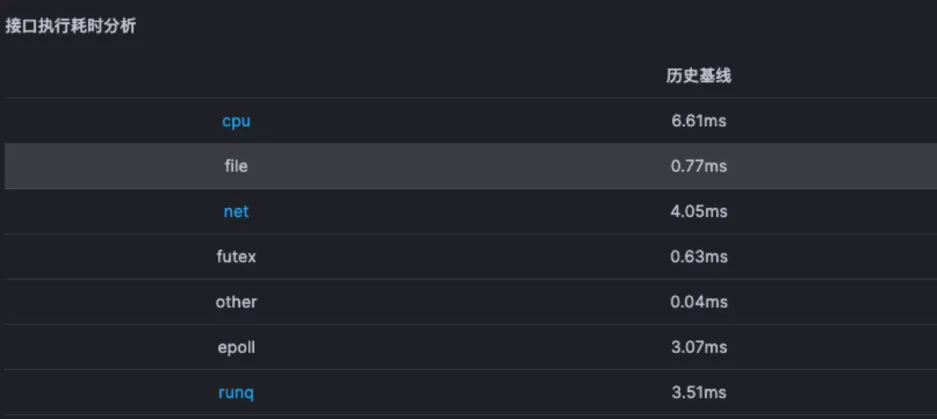
当某一次异常执行过程和基线对比之后,我们可以很快知道故障方向,比如以下的示例,问题明显就是文件方向:

问题:多分项的异常怎么办?
同时出现CPU耗时超出历史基线和net耗时超出历史基线怎么办?该往哪个方向排查?
针对一次请求的异常,我们认为应该聚焦突变最大的异常,所以只会关心突变最大的异常方向,但是并不是忽略其他突变的异常,对于根因定位而言,不能因为一次请求的异常就完全定出根因,应该对请求进行全面的分析。其它异常突变的分项如果真的是根因,在其它请求中一定也会有所反应,而偶发的噪音在其它请求中就能被过滤掉。
基于北极星指标的初因判断
对于突变最大的异常,我们会做一个初因判断,也就是某单次请求的初因异常,这样每个异常请求都会一个初因的标签了。
对请求全面分析之后的节点级故障特征
单次请求的异常可能是偶发因素,但是对节点所有请求进行全面分析之后,并统计之后,就能够形成故障特征,准确度大幅提高。比如某节点其故障特征如下:

对该特征的解释如下:
- 有些请求是幸运儿,没有经过长时间的锁等待就调用成功了下游服务节点,但是由于下游服务节点异常从而产生了网络调用耗时长的初因故障
- 更多的请求由于对外调用连接池的限制,产生了长时间的锁等待,所以产生了锁等待的故障
所以对于该特征的节点,大概率不是故障根因节点,因为其长时间的等待都是由于下游故障而导致的。