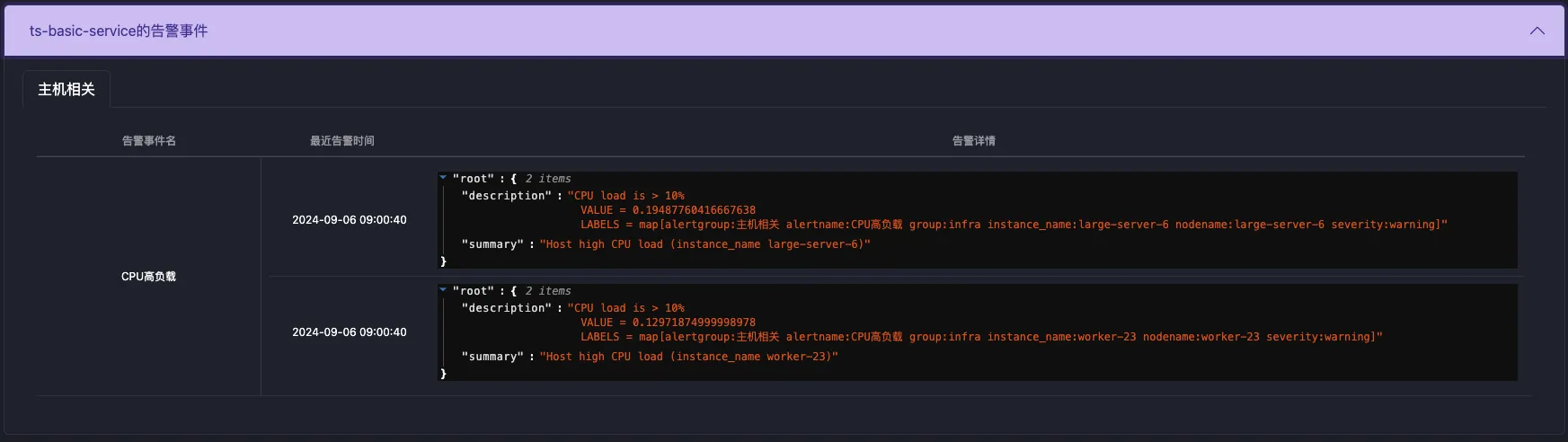
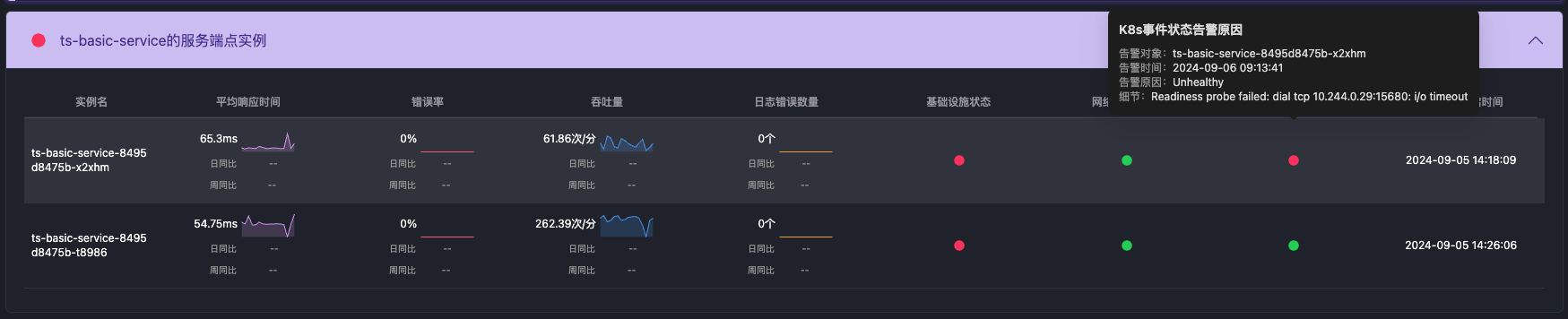
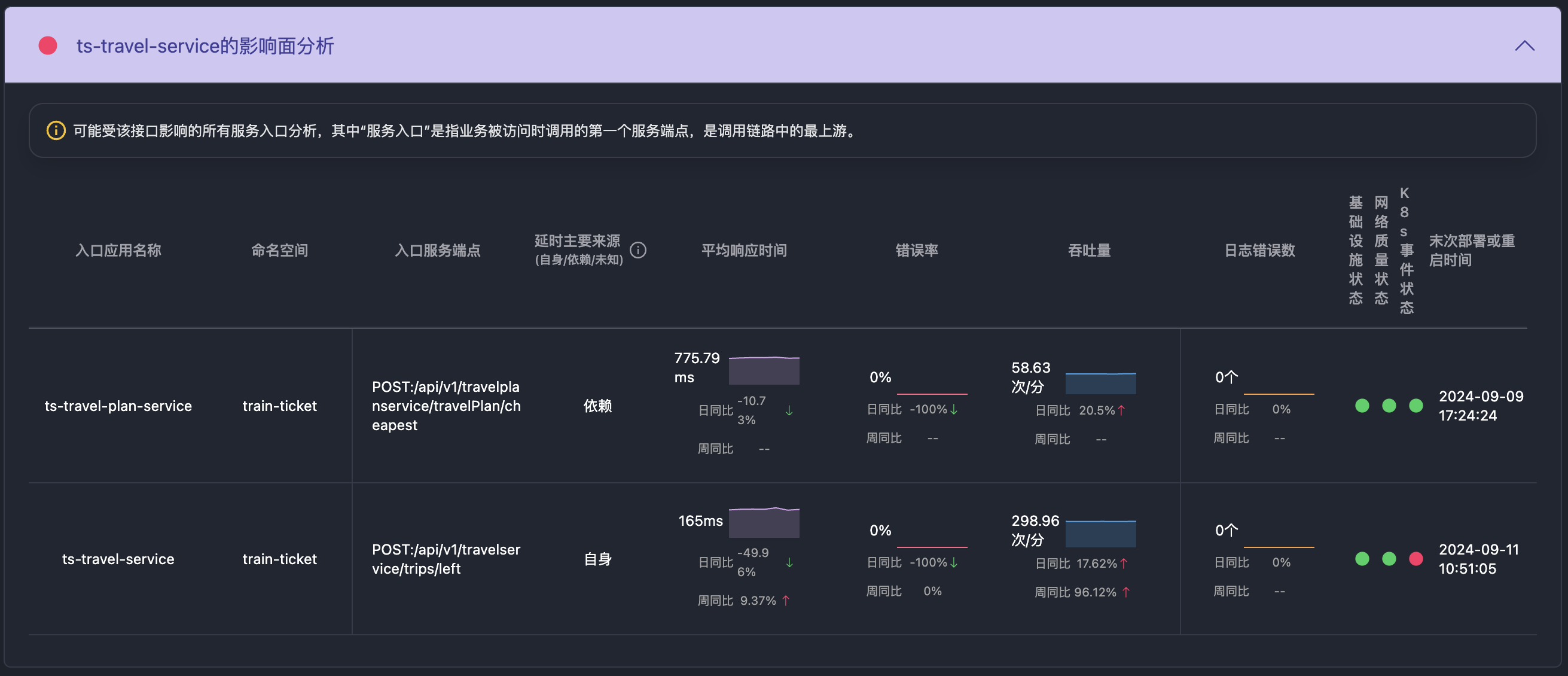
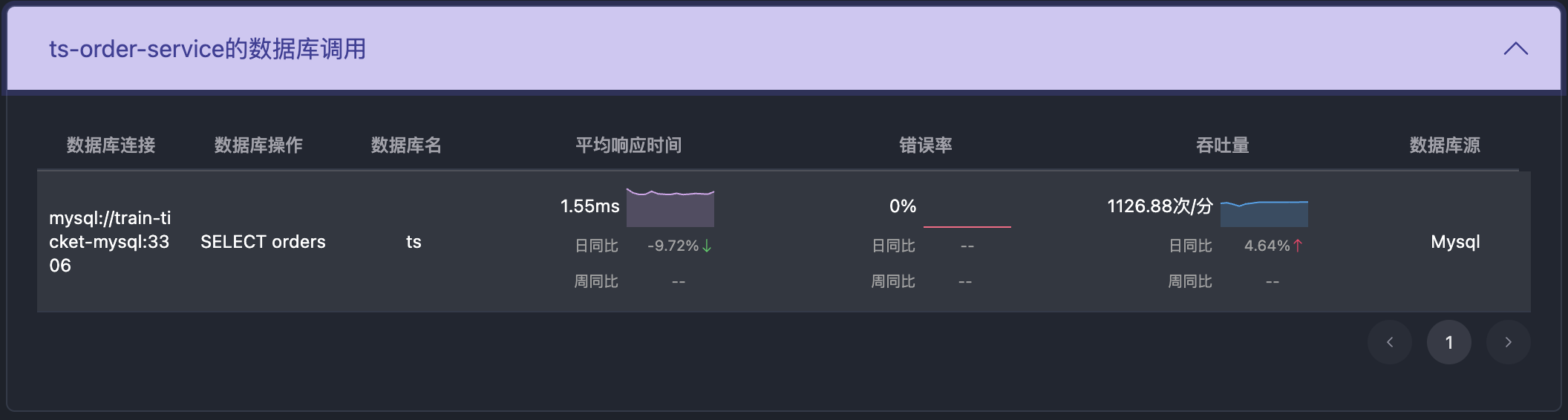
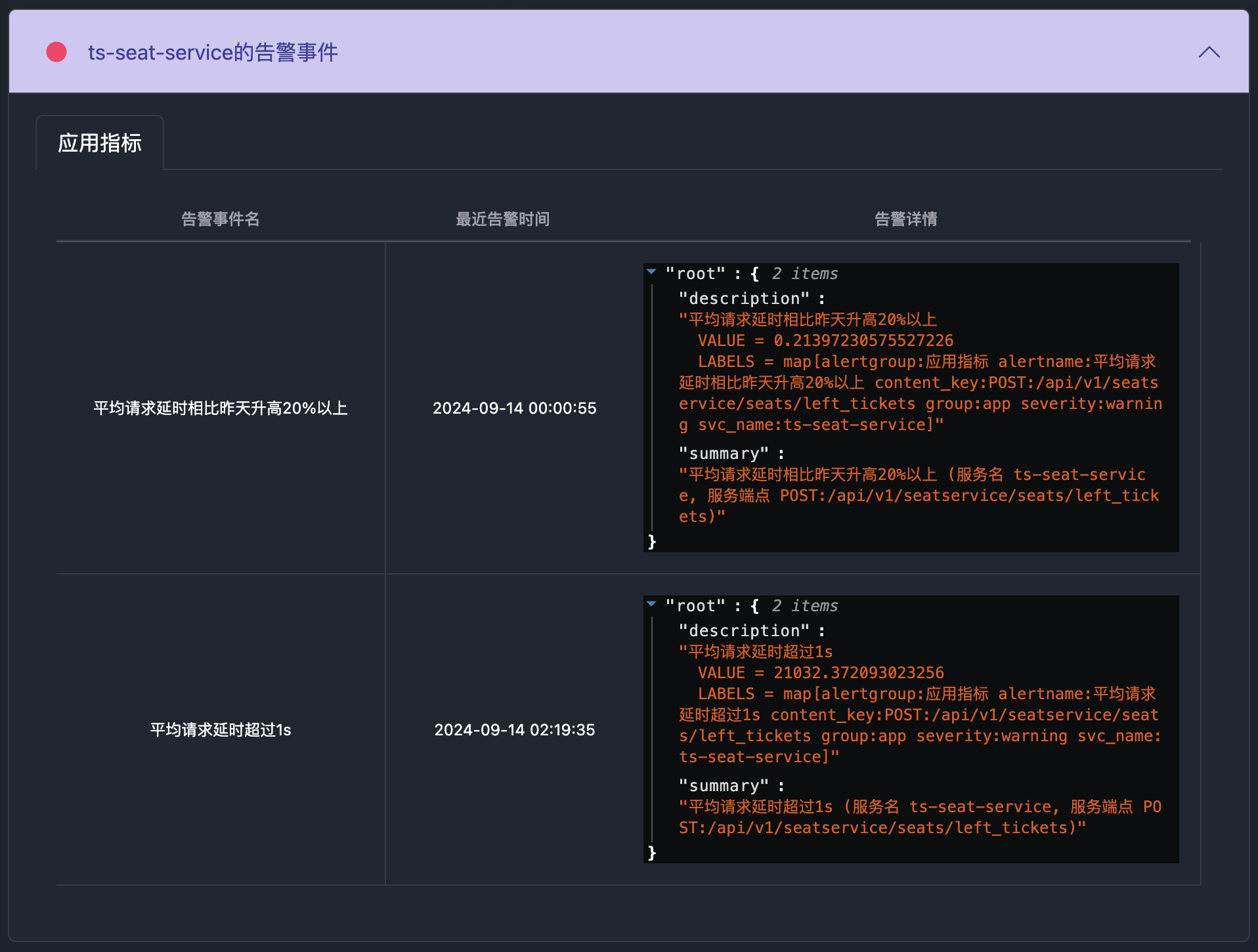
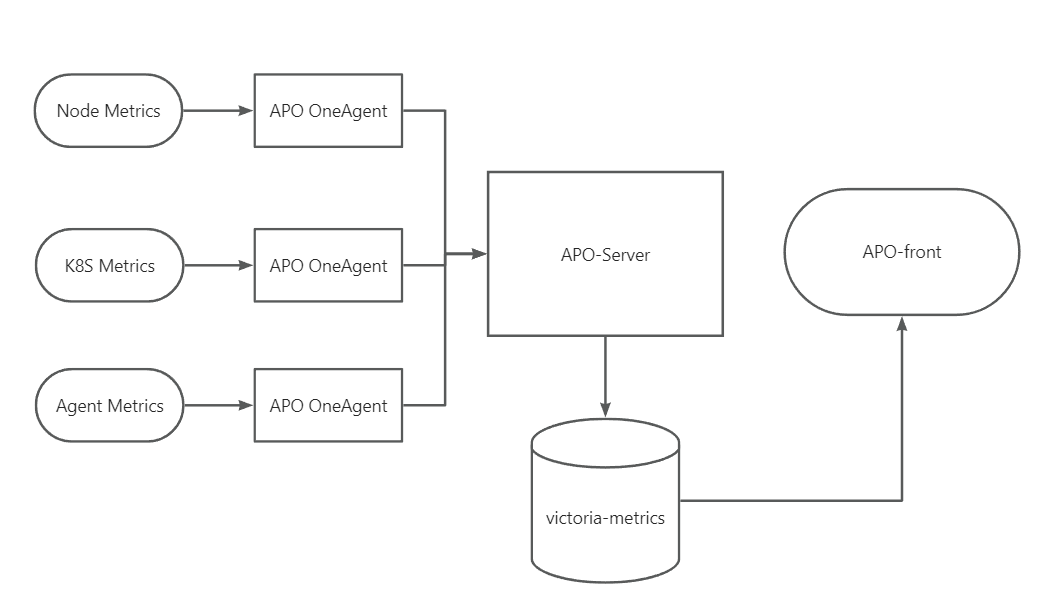
之前的文章介绍过APO是如何使用Grafana Alloy采集prometheus生态的指标体系。这篇文章介绍APO是如何采集Trace和log的,这两项数据的采集存在以下问题:
- 日志需要配置采集的日志目录,并不是每个应用的日志目录都非常规范,这就导致配置工作量的增加
- Trace需要配置针对语言的Agent完成数据采集
- 在容器环境不管是修改镜像或者使用init Container方式,都有挺多配置的工作
OneAgent的设计目标
OneAgent的设计目标是尽量减少用户的配置工作,尽快的完成数据的采集。在设计过程中,参考了很多的业界先进的技术实现,比如datadog的onestep agent的实现机制,另外重要的就是Odigos这家公司的实现。Datadog不用做更多的介绍,这里简单介绍下Odigos这家公司:Odigos的口号是“Instant Distributed Tracing”,有兴趣可以访问其官网:https://odigos.io/ ,OpenTelmetry 的 GO auto instrument 项目:https://github.com/open-telemetry/opentelemetry-go-instrumentation 就是由该公司捐献的。
Odigos开源的https://github.com/odigos-io/odigos 实现中能够实现以下功能:
- 基于应用当前已经启动的POD进行语言识别
- 基于K8s manifest挂载对应语言的探针文件和配置到对应的应用
- 通过更新K8s manifest触发应用重启以应用探针
为了实现OneAgent的设计目标,我们调整了Odigos的执行流程,使用Webhook将'更新K8s manifest'和'应用重启'两个步骤进行了分离:
- 更新内容以patch形式存储到应用的Annotations中
- 用户手动重启pod时,通过webhook拦截pod创建请求,应用Annotations中保存的patch
这样可以避免用户对整个Namespace装载探针时,集群所有应用同时重启,造成资源紧张;而是预先设置好探针配置,在应用下次更新时,自动完成探针的添加。
Odigos中没有包含非K8s应用的实现,我们采用了Linux的Preload机制来完成下面的工作:
- 通过LD_PRELOAD加载Preload库,在应用启动前拦截启动命令,完成语言识别和后续工作
- 基于识别到的语言设置探针配置,通常以特定的环境变量加入到启动命令
- 将改造后的启动命令交给Linux继续执行,完成应用的启动和探针的应用
为了实现OneAgent的设计目标,我们调整了Odigos的执行流程,使用Webhook将'更新K8s manifest'和'应用重启'两个步骤进行了分离:
- 更新内容以patch形式存储到应用的Annotations中
- 用户手动重启pod时,通过webhook拦截pod创建请求,应用Annotations中保存的patch
这样可以避免用户对整个Namespace装载探针时,集群所有应用同时重启,造成资源紧张;而是预先设置好探针配置,在应用下次更新时,自动完成探针的添加。
Odigos中没有包含非K8s应用的实现,我们采用了Linux的Preload机制来完成下面的工作:
- 通过LD_PRELOAD加载Preload库,在应用启动前拦截启动命令,完成语言识别和后续工作
- 基于识别到的语言设置探针配置,通常以特定的环境变量加入到启动命令
- 将改造后的启动命令交给Linux继续执行,完成应用的启动和探针的应用
针对日志数据的采集,我们采用了阿里开源的
https://github.com/alibaba/ilogtail 工具,它有下面一些优点:
- 基于Linux的inotify机制,相较于轮询读取文件,消耗更低
- 内置一套设计良好�的插件系统,性能开销较大的采集阶段使用C语言实现,确保高效;后续处理采用Go实现,可以快速的进行数据完善和处理
- 内置的采集插件支持了对父级目录下日志文件检索,避免用户手动配置每个应用日志地址
在ilogtail基础上,我们实现了功能增强插件,用于统计需要的日志指标,填充日志进程信息和日志数据采样。
程序语言的自动识别
目前的程序语言识别均基于启动命令特征和启动文件信息:
- JAVA: 检查启动命令是否满足 java [-options] class [args。。。] 或 java [-options] -jar jarfile [args。。。] 格式
- PYTHON: 检查启动命令中是否包含python
- Golang: 读取启动文件的内容,检查是否有可识别的buildInfo信息
- NodeJS: 检查启动命令中和启动文件路径中是否包含node
- Dotnet: 检查启动环境变量中的环境变量名中是否包含DOTNET和ASPNET
探针配置的注入
在完成应用语言类型的识别后,开始准备探针的配置信息。
1.OTEL体系下的APM探针均原生支持基于环境变量来设置探针,我们目前主要预设了下面的配置:
- OTEL_EXPORTER_OTLP_ENDPOINT 设置探针数据的发送地址
- OTEL_SERVICE_NAME 设置应用名称
- OTEL_METRICS_EXPORTER/OTEL_LOGS_EXPORTER 设置为 none,关闭指标/日志采集
2.Skywalking当前以内置的配置文件作为中转,也支持使用环境变量进行配置,主要设置:
- SW_AGENT_COLLECTOR_BACKEND_SERVICES 设置探针数据发送地址
- SW_AGENT_NAME 设置应用名称
对于K8s应用,大部分的环境变量会由Odigos通过k8s提供的Device Plugins加入到容器内;
用户已经在K8s Manifest定义了的环境变量,会在K8sManifest显式的合并到用户定义的Envs部分。
对于非K8s应用,环境变量会直接被添加到启动命令中,如果和用户定义变量发生冲突,始终使用用户定义变量。
探针的拷贝
在K8s环境中,由于容器的文件隔离特性,应用无法直接获取到需要的探针文件。Odigos通过将宿主机路径挂载到应用容器内部来向应用提供探针文件,默认将探针文件放到应用的/var/odigos 目录下。
在非K8s环境中,由于应用可以直接获取到宿主机上的探针文件,所以当前没有进行探针文件的拷贝。
日志和进程信息关联
在K8s环境下,采集器通过日志的文件路径可以直接关联到容器,再由容器可以直接关联到所属的应用。这使得在查询日志时,可以通过应用来过滤日志,对于查找关键信息有很大帮助。
非K8s环境中,采集器获得的日志的文件路径就不再像K8s环境中那么规范。不论是ilogtail所使用的inotify机制,或者其他基于文件轮询的日志采集工具,都无法获取到日志是由哪个进程产生的。常规的处理方式是整个项目推行日志文件路径规范,从而可以解析日志文件路径来获取应用信息,这是一种成本较高的解决方案。
APO使用了Linux的Fanotify接口来关联文件和应用信息,它是一个在linux内核2.6.37引入的系统接口,利用Fanotify可以自动关联进程所产生日志文件。
为了降低监听Fanotify事件的资源开销,APO遵循下面这套方案进行文件到应用关联关系的维护:
- 通过inotify获取到日志文件更新信息
- 将日志文件路径添加fanotify监控标记,监控该文件的修改和关闭事件
- 日志文件下次被修改时,获取到修改该文件的进程信息。缓存该日志文件路径对应的进程信息,并关闭对该文件修改事件的监控
- 直到接收到该日志文件的关闭事件,这意味着之前获取的进程停止了对该文件的写入;此时重新开始监控该文件的修改事件,以更新该日志文件路径对应的进程信息
通常仅应用进程会对日志文件进行修改,因此上面这套方案可以以极低的消耗完成较为可靠的日志文件路径到进程信息的关联。
APO通过OneAgent中的集成修改的Odigos机制,实现了不同语言的应用程序自动完成OTEL trace探针的安装和环境变量配置,同时通过集成ilogtail采集了日志,并能够实现日志和应用的关联。
OneAgent能够在容器环境和传统虚拟机上同样工作。
APO介绍:
国内开源首个 OpenTelemetry 结合 eBPF 的向导式可观测性产品
apo.kindlingx.com
https://github.com/CloudDetail/apo