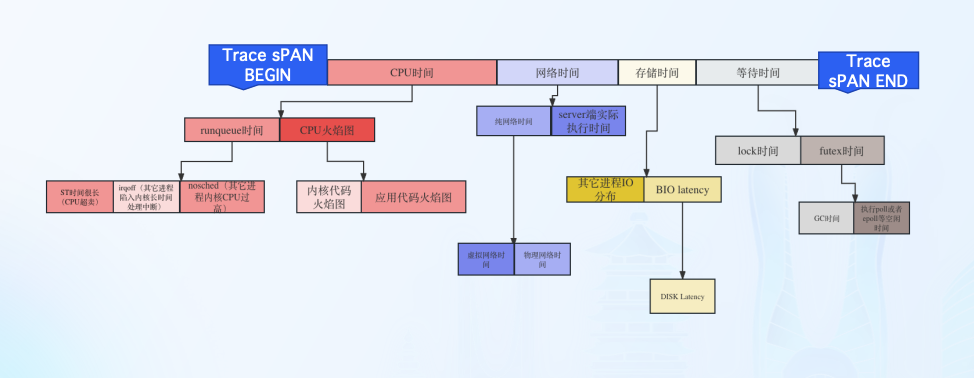
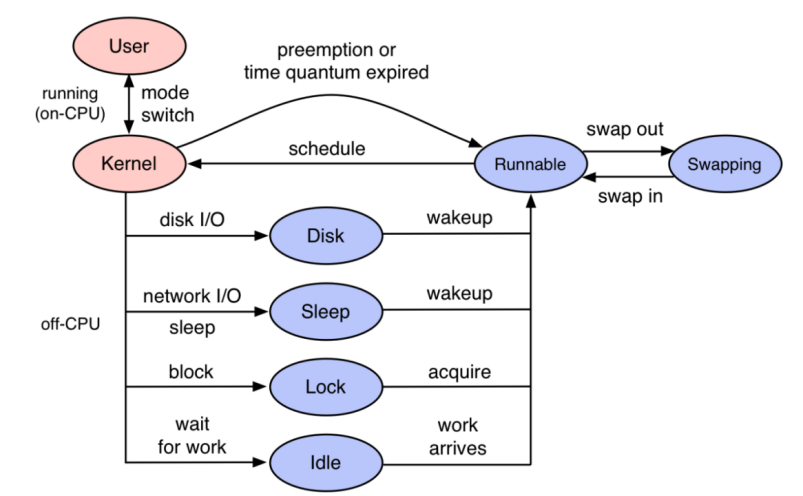
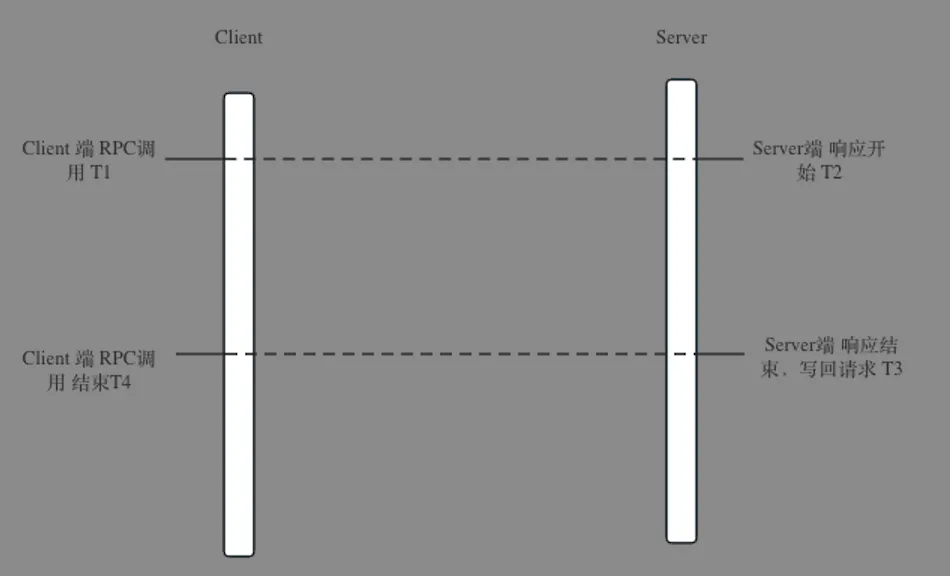
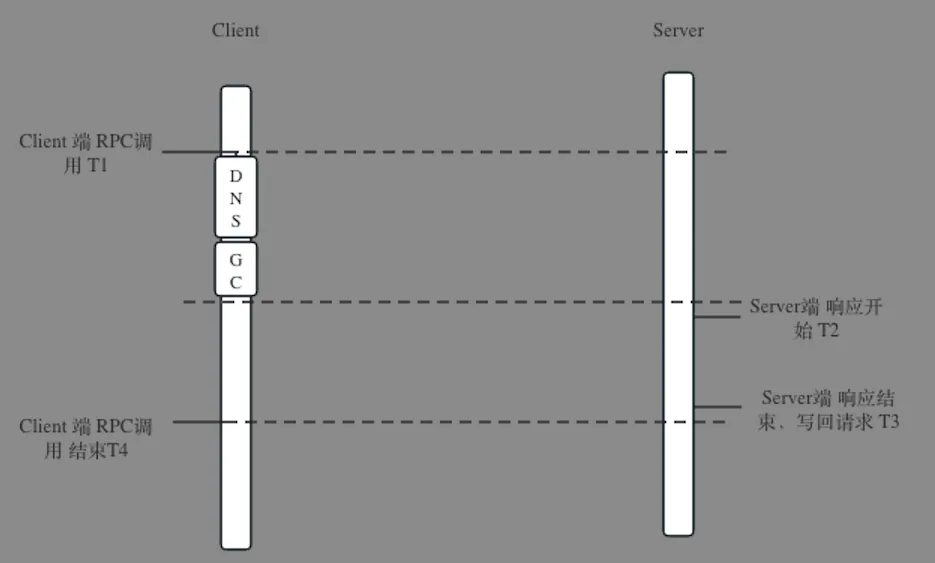
Originx 并不期望做一个完整覆盖全栈的监控体系,而是利用北极星指标体系标准化找出故障方向,然后联动各种成熟的监控数据形成证据链条,并将各种数据融合在一个故障报告之中。更多信息请参考文章
Log | Metrics | Trace 的联动方式探讨
Oringinx 智能化实现全栈故障定位
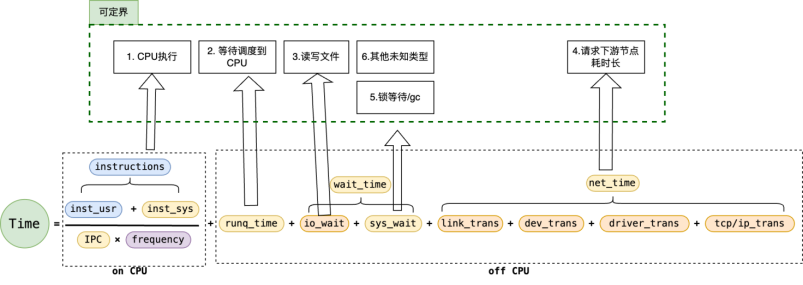
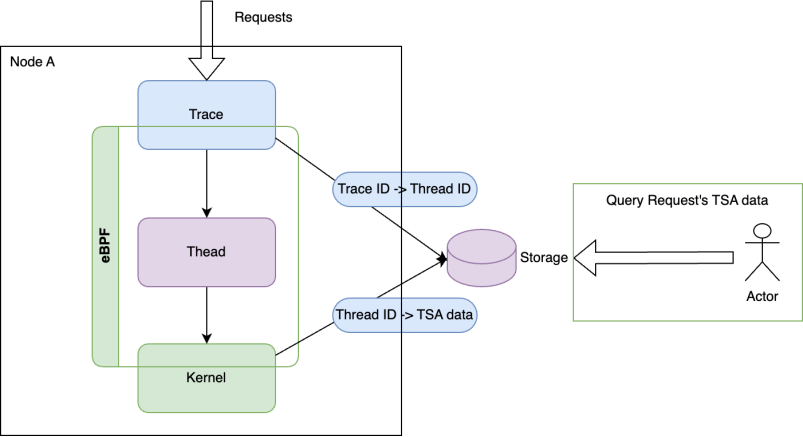
Originx 的设计目标是力争实现全栈故障种类的定位,自身的 eBPF 探针采集北极星排障指标,然后北极星排障指标引导到故障根因,Originx 的核心工作原理请参考下方网址或者或者扫描下方二维码
http://u6v.cn/6wIL7w

在已经识别出故障方向之后,利用各种成熟的开源监控作为数据来源,形成完整的证据链条,最终形成用户能够直接使用的故障根因报告。
下面我们将呈现如何利用 Originx 的功能实现应用程序故障的根因定位。
应用程序故障
代码缺陷导致应用崩溃或错误
○ 案例:2023 年双 11 期间,某汽车在线订单平台的 Tomcat 服务节点出现了严重的线程池耗尽问题。事发当天上午 10 点多,随着大促活动的用户流量激增,结算服务的响应时间明显下降。到中午时,大量来自北京地区的用户反馈在提交订单结算时,页面卡顿严重,部分直接超时失败。经过一天的紧张排查,最终发现是 Java 结算模块存在循环等待的死锁问题。该模块中存在太多的锁粒度,再加上连接池等配置不合理,并发压力下更容易发生死锁。临时解决方案是扩容结算服务的资源,并重启 Tomcat 释放线程。次日即行修复死锁代码,并持续优化相关模块的并发能力。这次事故虽然只持续了一天,但给用户造成了极差的下订体验
如果出现案例描述中 Tomcat 服务节点由于代码锁粒度太大出现了严重的线程池耗尽问题, Originx 轻松能够帮助用户分析出根因:
Originx 的解决之道:
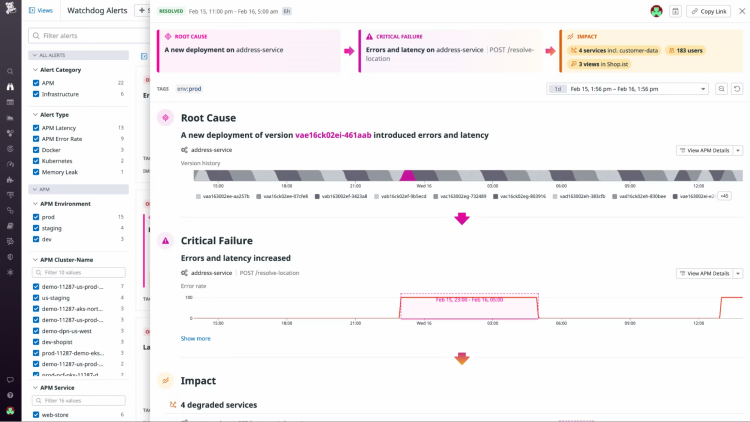
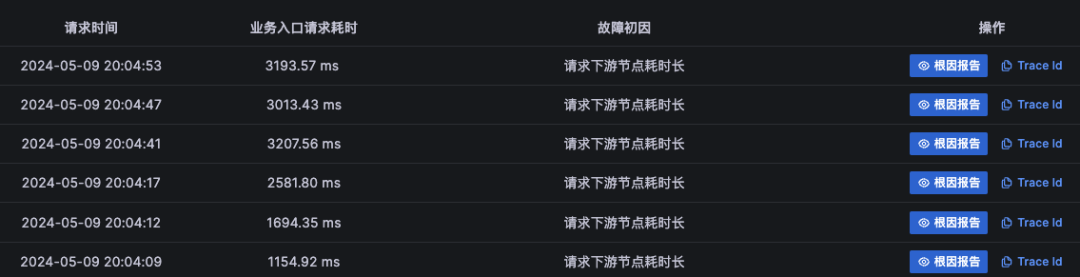
1、在 Originx 首页,Originx 的 SLO 告警就会针对 SLO 违约告警
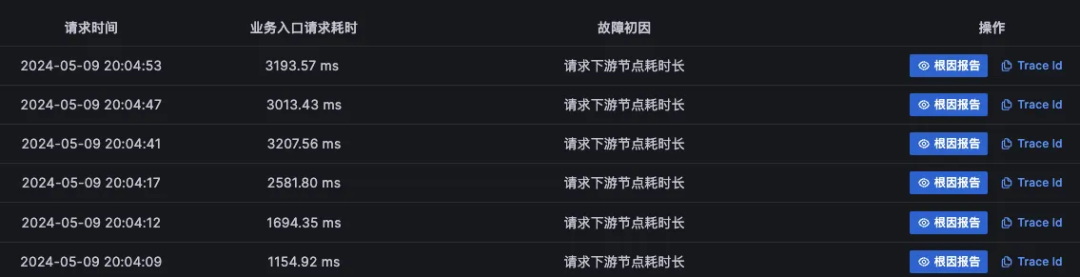
2、同时会分析出可能的故障根因节点,当点击详情之后,每个节点的故障初因列表会被呈现�出来
大概率是真实故障原因的疑似故障根因节点效果如下:(因为真正故障点的初因应该是一致的,或者有极少数的初因不一致的情况)
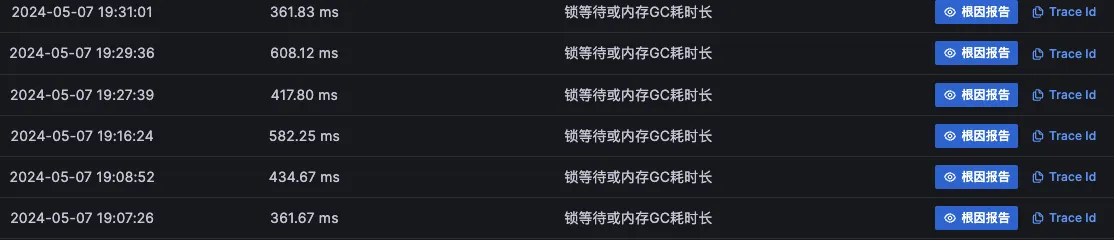
被级联影响的疑似故障根因节点效果如下:(Originx 会将 Trace 数据中突变变化前 3 的节点当成疑似根因节点,所以被级联影响的节点由于突变较大大概率会被当成疑似节点,而被级联影响的故障根因点大部分初因应该是下游节点耗时长,同时也可能存在因为采用池化调用框架导致出现隐藏锁而得到初因为锁的情况)

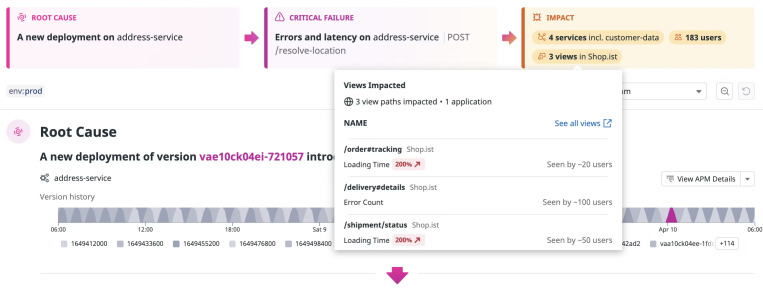
Originx 下个版本会呈现所有疑似根因的依赖关系,这样就能让人更好的理解谁是根因节点了,大概率是被依赖最深的节点,但是其他节点的根因报告不能完全忽略,最好能够也随机花几秒钟查看下其他根因报告
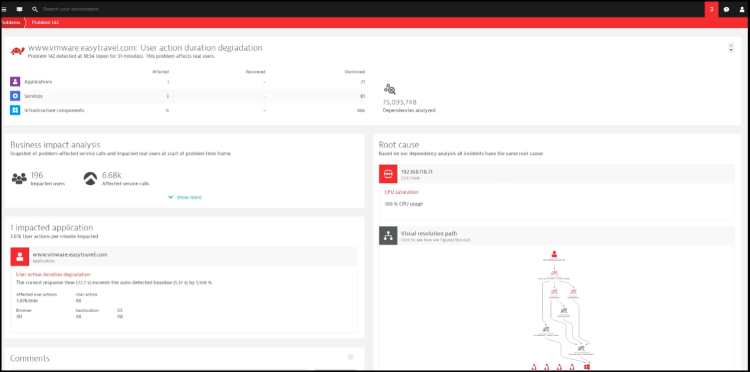
3、在确认故障根因节点之后,可以从故障根因节点的任意根因报告中查看根因报告详情
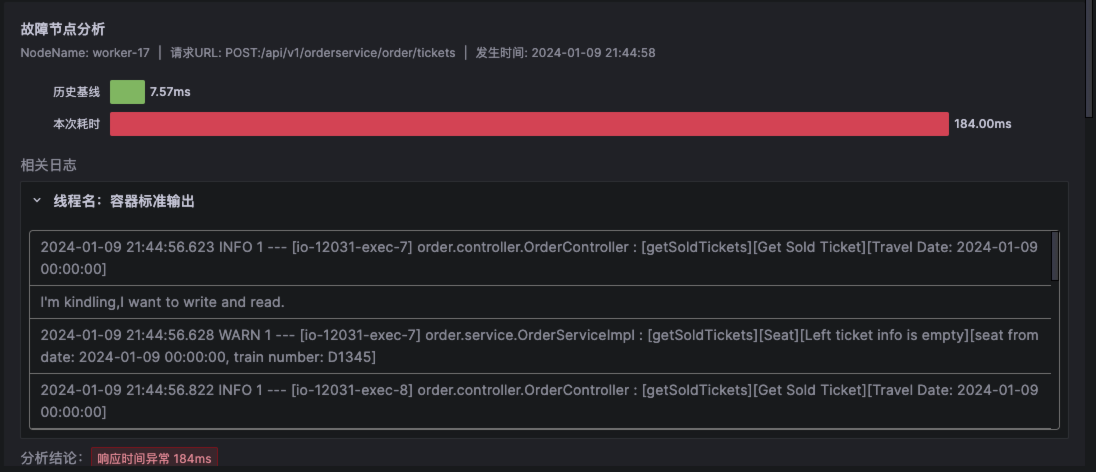
4、在故障报告的报告头部呈现的是故障概览,这里关联了 TraceId 以及发生的时间,如果有必要可以使用 TraceId 去关联分析 Tracing 数据

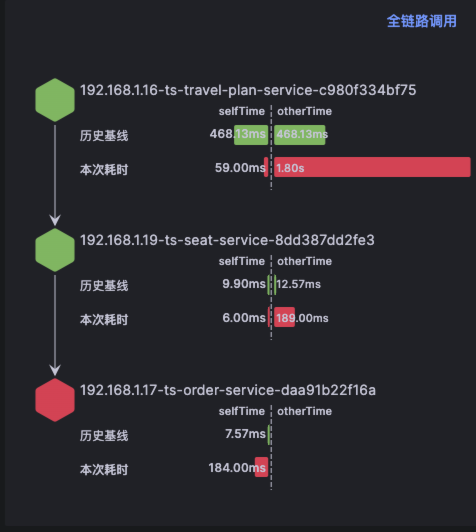
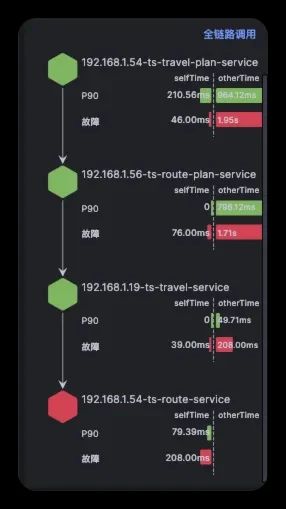
5、在故障报告左边栏中,确认故障传播链路,近似于下图,通过这个数据可以确认在此次报告中故障节点判定是否正确
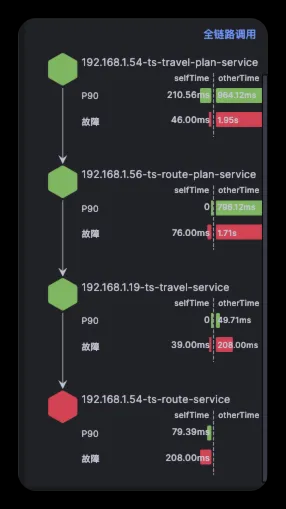
6、在故障根因中,能够看到根因结论,在多份报告中看到同样的根因报告,这个时候其实可以采取应急手段来恢复业务了,针对本案例的情况:比如重启应用或者扩容,具体的应急策略需要根据公司的政策来确定,有些企业的业务是不能重启的,那就只能扩容,有些企业的资源是有限的,那就只能在对业务影响最小的时候重启

7、在故障报告中,以下的数据都是为了提供证据链条来确认故障报告的准确性
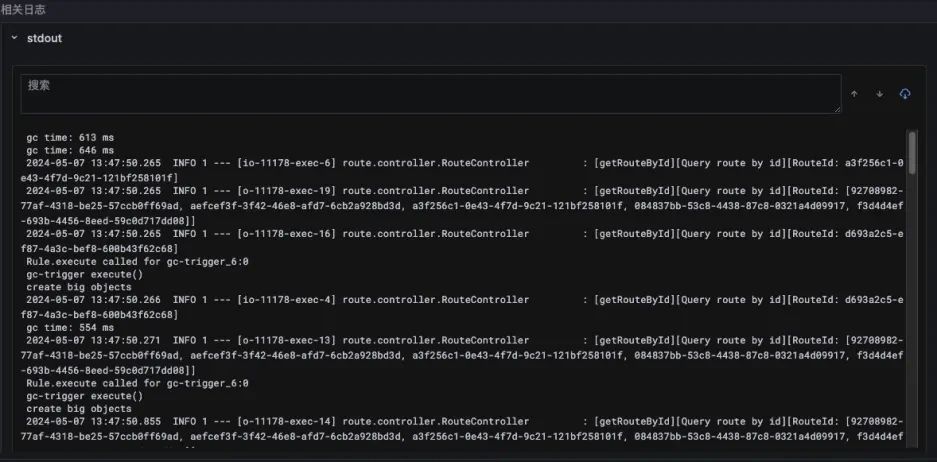
日志数据,关联了 Trace 在节点执行(也就是故障概览呈现的故障发生时间)时间段的日志数据
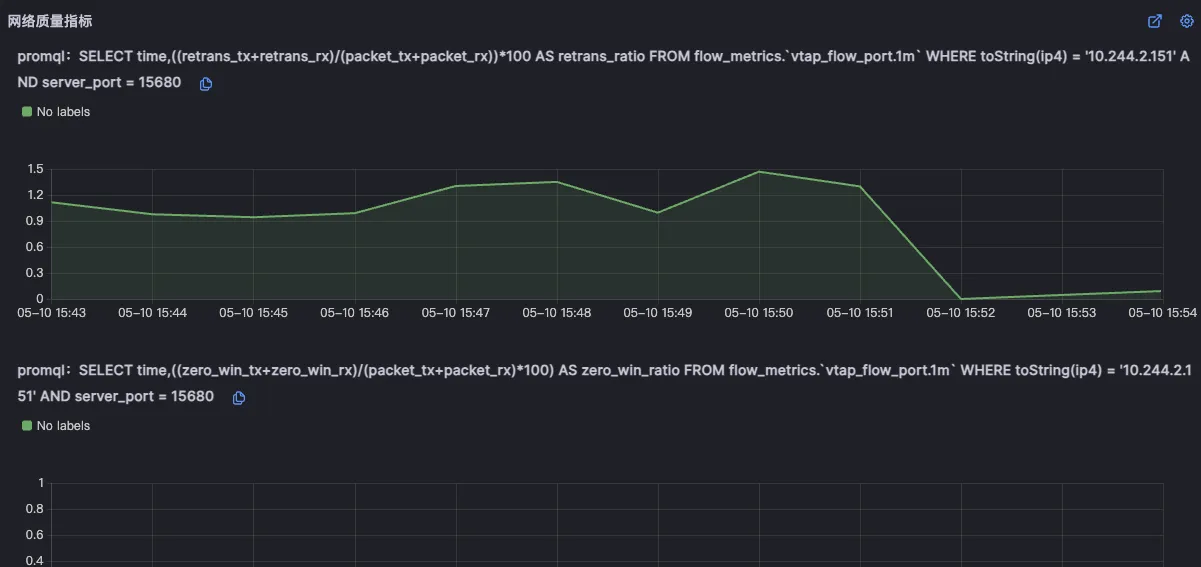
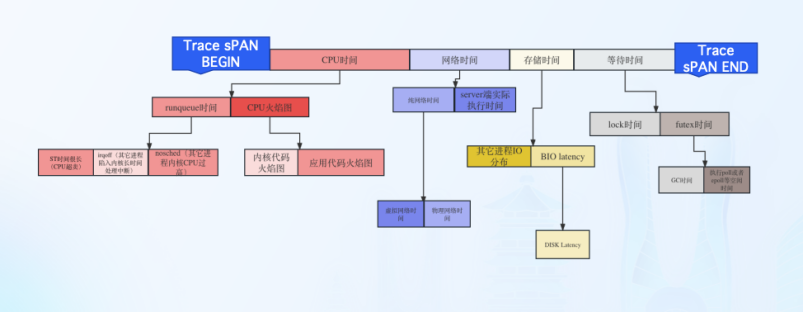
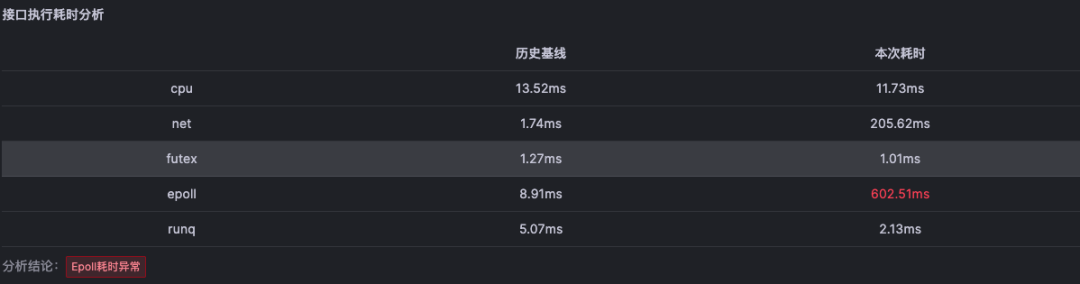
北极星指标(通过北极星指标,Originx 给出了异常幅度最大的异常方向,本案例的方向就是 Futex 也就是锁的方向)

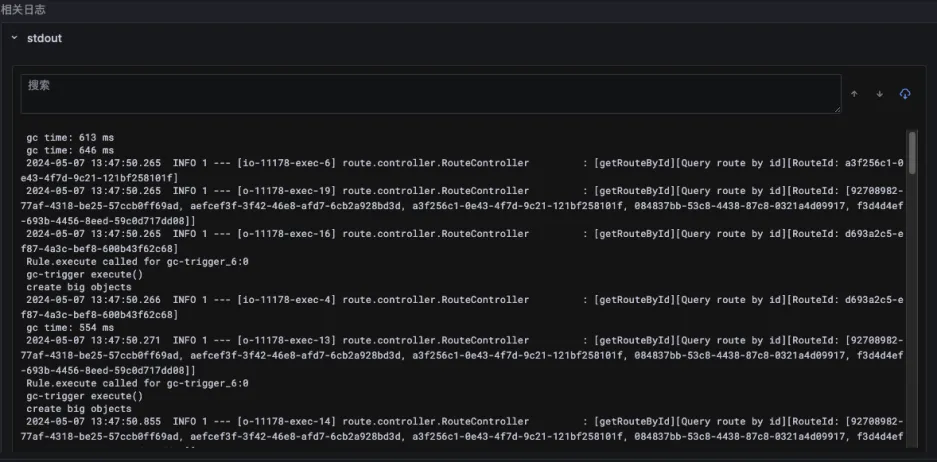
由于北极星指标已经明确了异常方向是锁的方向,所以以下的证据链条会重点分析锁的方向。在 JVM 实现中,GC 也会采用内核 Futex 机制来实现线程等待,所以当分析 Futex 异常之时,Originx 会先确认此时是否发生了 GC,如果有 GC 发生,就会关联 GC 相关的数据

接下来 Originx 会关联程序锁的相关数据
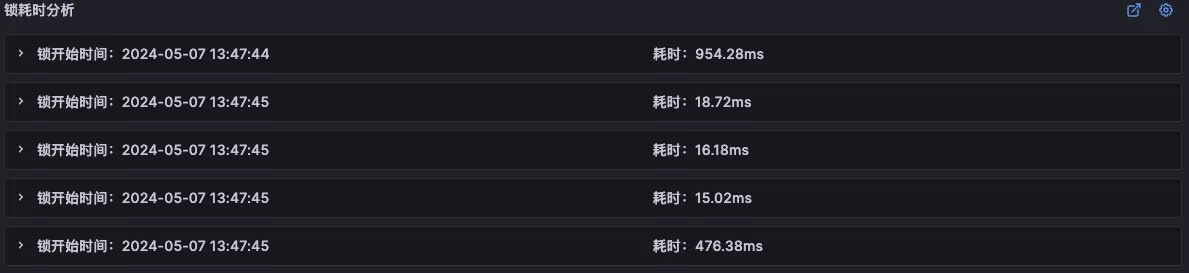
在锁具体相关信息中,可以看到锁的执行堆栈
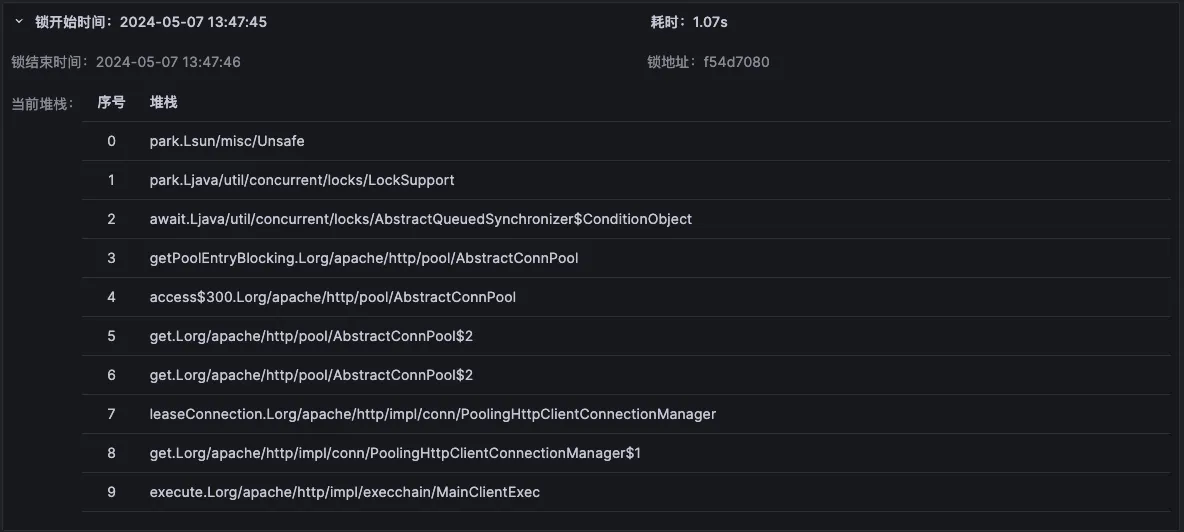
8、总结:通过锁的堆栈分析,可以确认程序出现了长时间的锁,这个时候可以进行 patch 快速修复,或者回滚代码至之前的版本规避锁的问题,或者扩容来人为提高并发
资源不足(CPU、内存、磁盘)
○ 案例: 2023 年 5 月 12 日,一家大型商业银行的新版网上银行系统在上线后不久遭遇了某些业务场景执行超时的错误。由于代码中存在一个未被发现的逻辑错误,导致在特定参数组合场景下,系统会重复执行某项业务逻辑,造成 CPU 使用率异常飙升。这种情况在测试环境中难以复现,因此未被及时发现。故障发生后,客户在进行转账和查询等操作时遇到了明显的延迟,严重时甚至导致服务不可用。银行紧急协调开发团队进行排查,在生产环境中利用 jstack 等工具查找 CPU 飙升的原因,最终在 4 小时内定位到了问题源头。通过快速发布补丁修复了 BUG,并重新部署了服务。此次事件导致银行损失了大量客户交易,并对其声誉造成了一定影响
如果出现案例描述中代码在某些参数特定组合场景下,导致代码会递归执行导致 CPU 飙高,人为分析是比较困难的,只能等待场景复现才能去故障现场使用 jstack 等命令分析 CPU 高的线程在干什么,Originx 轻松帮助用户分析出根因:
Originx 的解决之道:
1、在 Originx 首页,Originx 的 SLO 告警就会针对 SLO 违约告警
2、同时会分析出可能的故障根因节点,当点击详情之后,每个节点的故障初因列表会被呈现出来
3、根据不同节点的初因情况来确认根因节点,在这种案例中根因节点会是以下几种情况:
根因节点的表现形式应该有“初因 CPU 耗时长”的报告,同时根据容器或者虚拟机的资源规格,如果资源规格较小,CPU 资源不足,就会出现很多请求“等待调度 CPU 耗时长”的初因表现
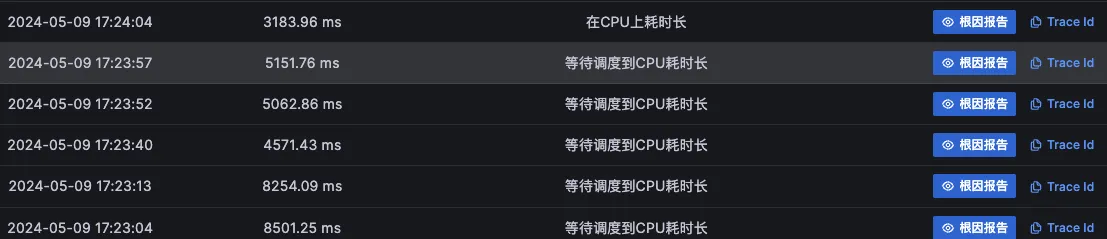
注意过滤掉其他受影响的级联节点,如果不确定节点是否是被级联影响,可以查看根因报告,稍微花个一分钟确认下
4 、在故障报告的报告头部呈现的是故障概览,这里关联了 TraceId 以及发生的时间,如果有必要可以使用 TraceId 去关联分析 Tracing 数据(具体截图可以参考之前的案例)
5、在故障报告左边栏中,确认故障传播链路,近似于下图,通过这个数据可以确认在此次报告中故障节点判定是否正确(具体截图可以参考之前的案例)
6、在故障根因中,能够看到根因结论,在多份报告中看到同样的根因报告,这个时候其实可以采取应急手段来恢复业务了,针对本案例的情况:
比如回滚或者扩容,具体的应急策略需要根据公司的政策来确定,有些企业的业务是不能回滚的,那就只能扩容

7、在故障报告中,以下的数据都是为了提供证据链条来确认故障报告的准确性
日志数据这里不再截图和之前案例类似
北极星指标(通过北极星指标�,Originx 给出了异常幅度最大的异常方向,本截图的方向就是 CPU)

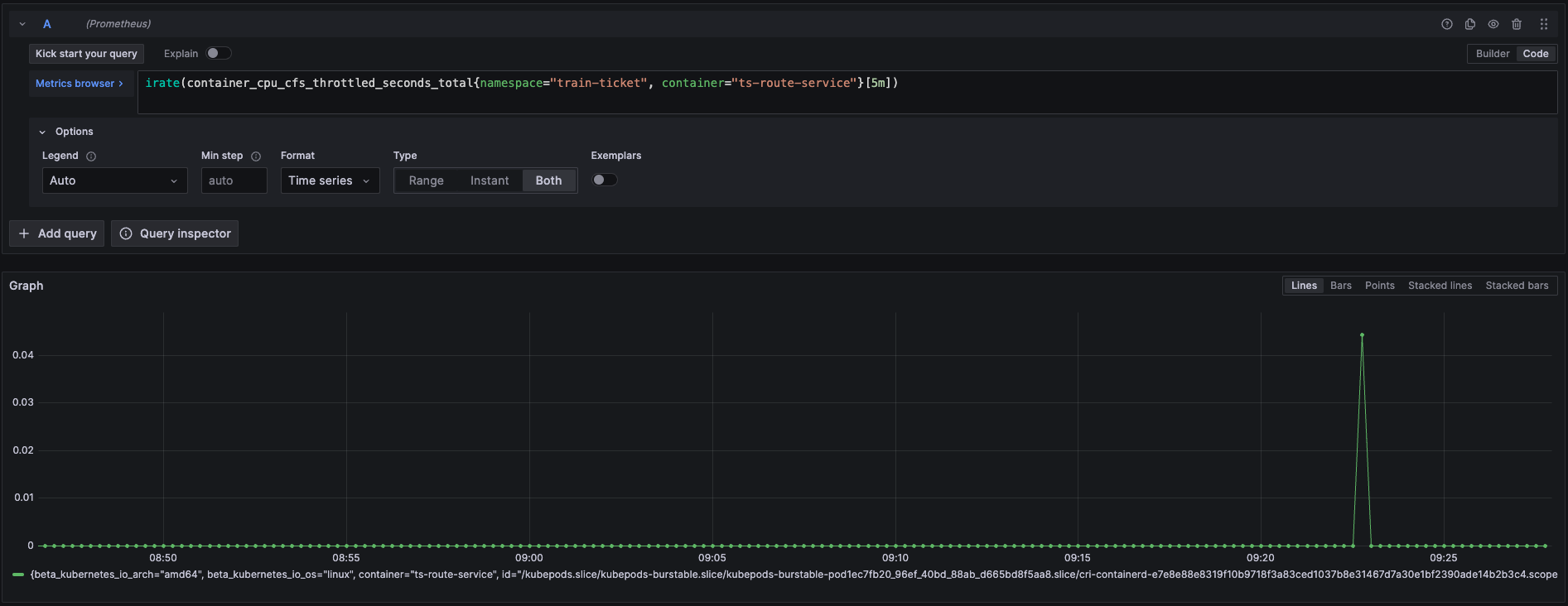
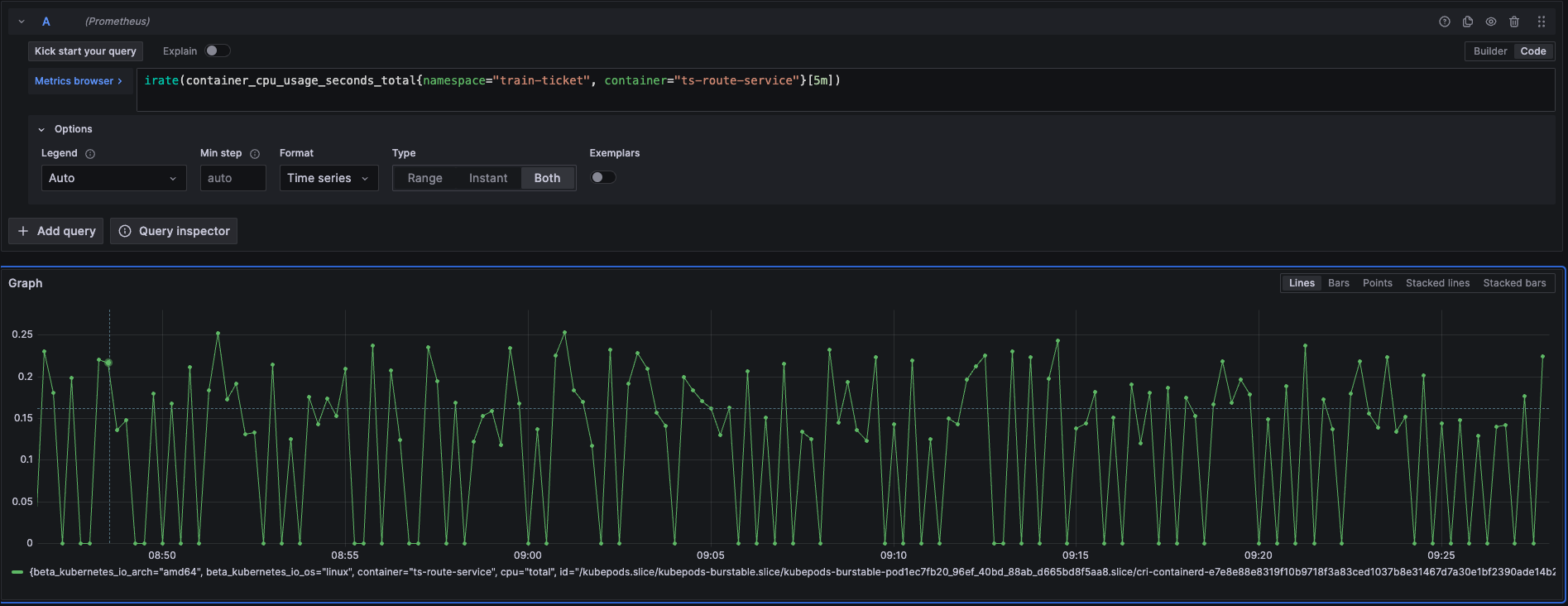
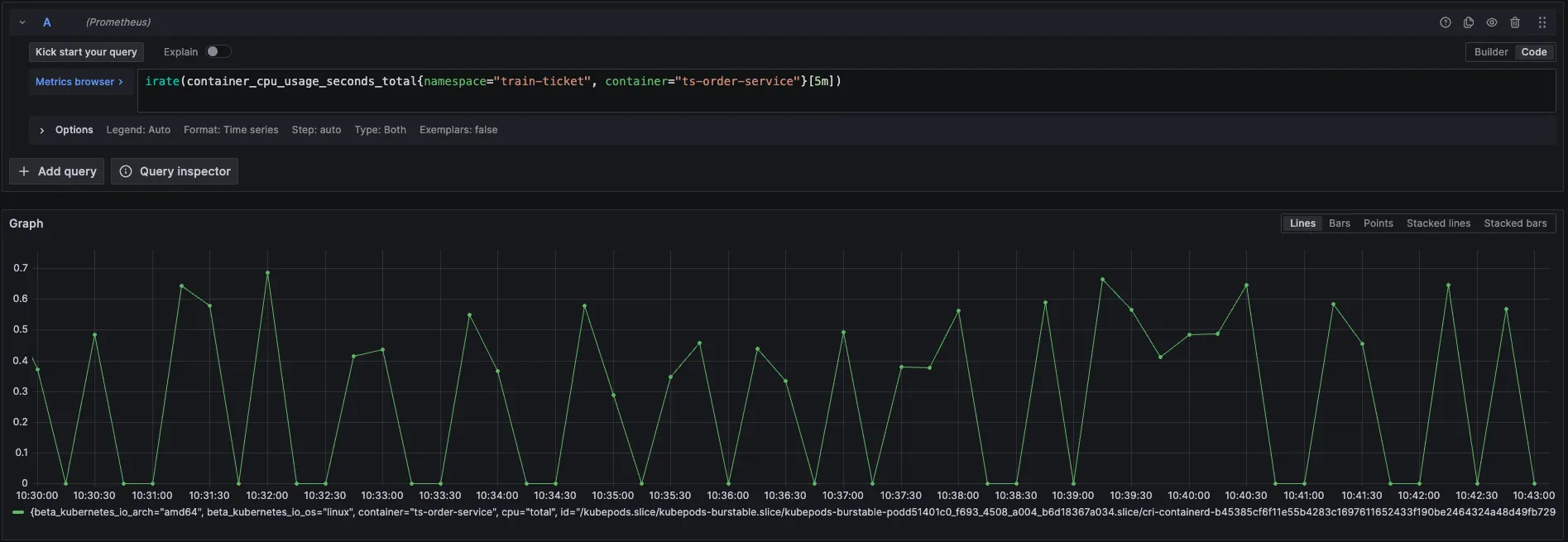
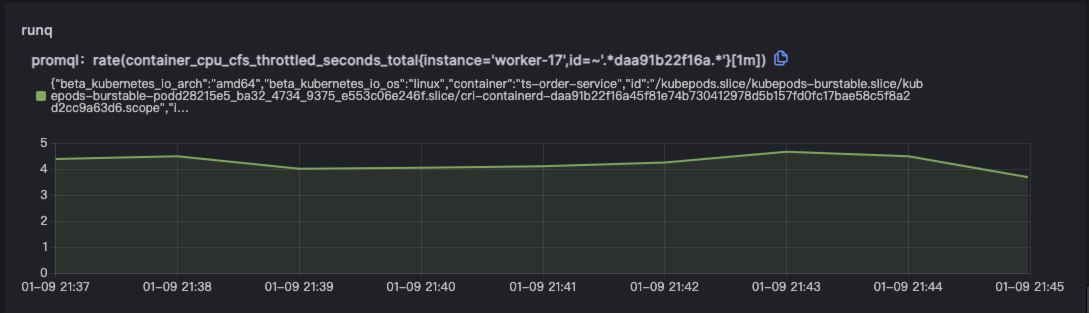
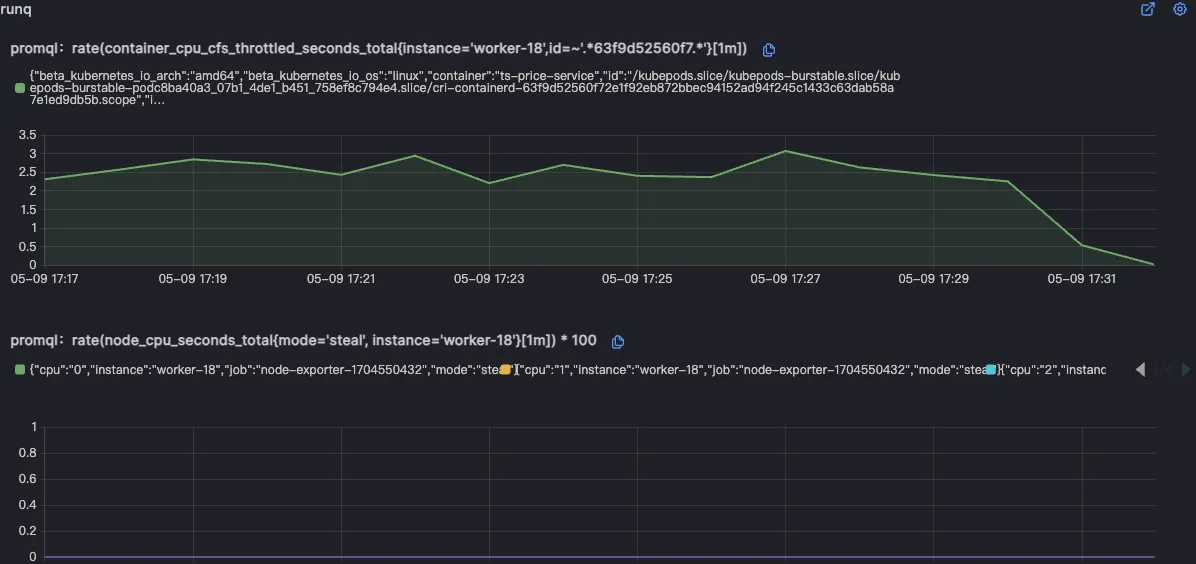
北极星指标(通过北极星指标,Originx 给出了异常幅度最大的异常方向,本截图方向就是 RunQ 方向,如果是 RunQ 方向,Originx 会同时查看 CPU 是否也突变了很大幅度, 如果 CPU 也突变了很大幅度,那说明 RunQ 的产生就是由于 CPU 消耗过高导致线程等待调度所致,如果 CPU 没有太大突变,说明是由于其它进程抢占 CPU 导致的调度等待)

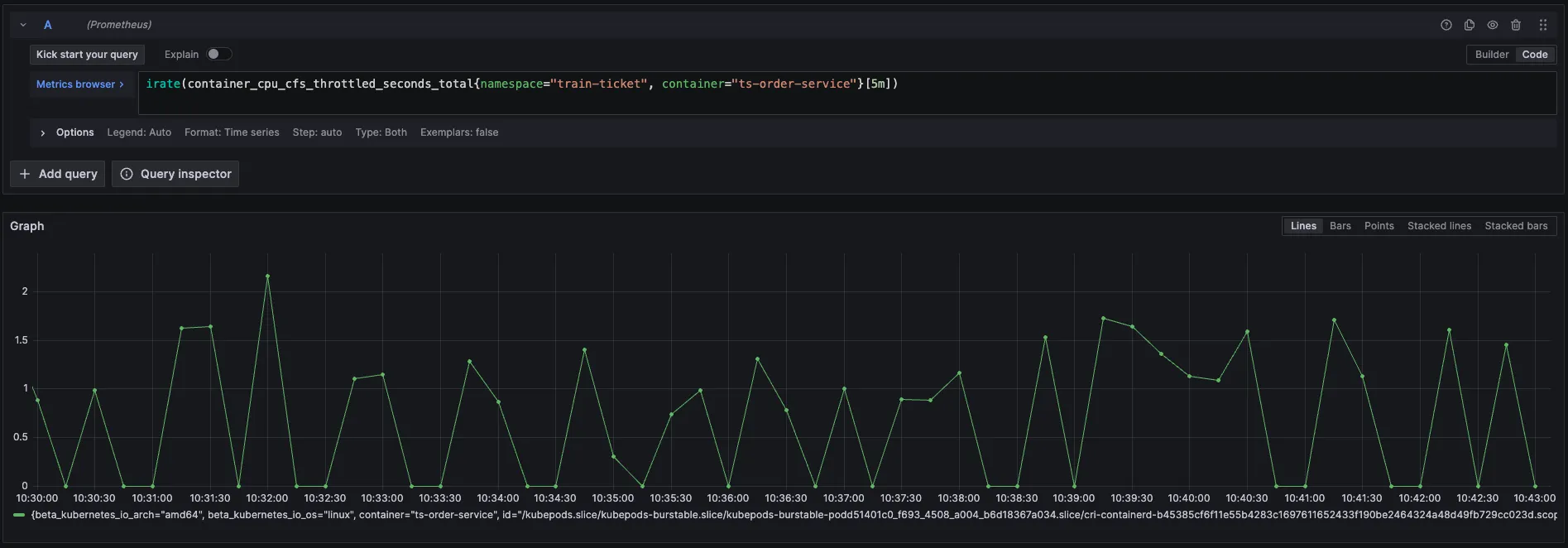
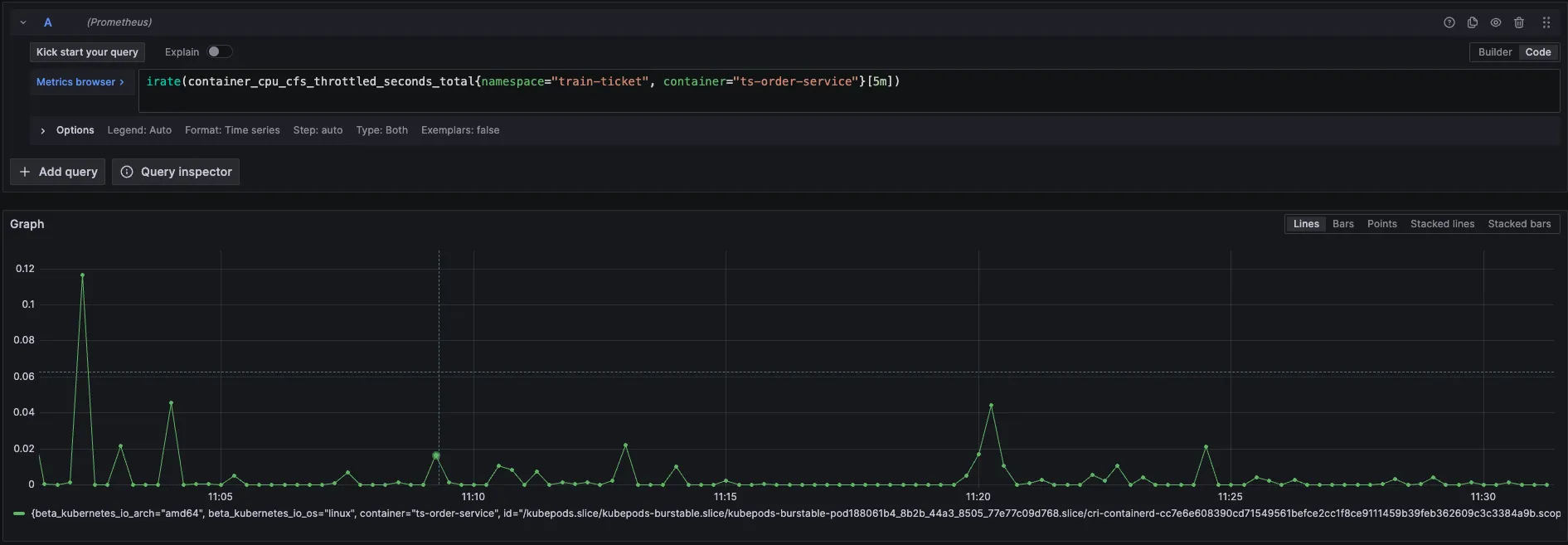
如果是 RunQ 突变较大,还会关联 cpu_throuttled 相关指标来证明程序存在此问题
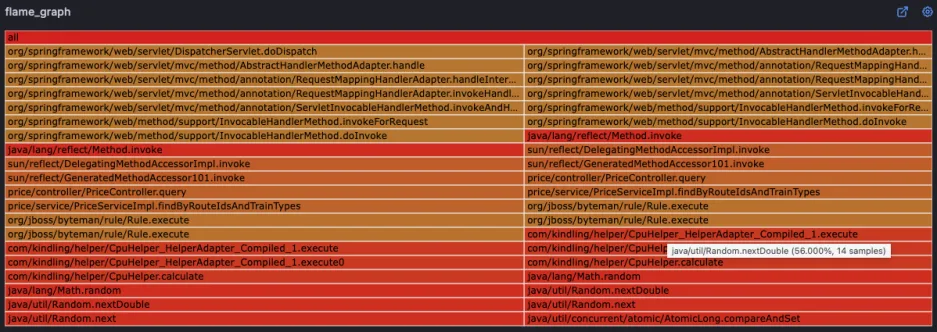
在 CPU 火焰图中可以看到哪些代码在循环执行
应用配置问题
○ 案例: 2023 年 3 月 15 日,一家领先的金融支付服务公司遭遇了支付处理延迟的问题。由于对高峰时段的实例数扩缩容配置人为操作错误,导致在线支付服务的实例数量未能满足既定需求。在随后的高峰交易时段,支付系统出现了严重的延迟,部分交易无法完成,影响了客户的支付体验,并导致公司损失了数百万的潜在交易额。经过紧急扩展服务实例并重新配置负载均衡策略,服务在 2 小时内逐步恢复。此次事件突显了容量规划在金融服务中的重要性,并促使公司加强了对服务容量和性能监控的投资
如果出现案例描述中实例数配置出错导致不足以应对高峰流量时, Originx 轻松能够帮助用户分析出根因:
Originx 的解决之道:
1、在 Originx 首页,Originx 的 SLO 告警就会针对 SLO 违约告警
2、同时会分析出可能的故障根因节点,当点击详情之后,每个节点的故障初因列表会被呈现出来
3、根据不同节点的初因情况来确认根因节点,在这种案例中根因节点会是以下几种情况:
-
此种情况并不常见,但是应用如果是CPU密集型的,产生以下这个现象还是非常有可能的。由于实例配置错误,扛不住流量高峰,表现为整个微服务链路上的容量瓶颈节点的出现CPU资源不足的初因,因为每个请求都需要消耗较多的CPU,流量高峰导致其CPU不足,从而产生以下这种根因节点。排查思路和资源不足思路基本类似。

-
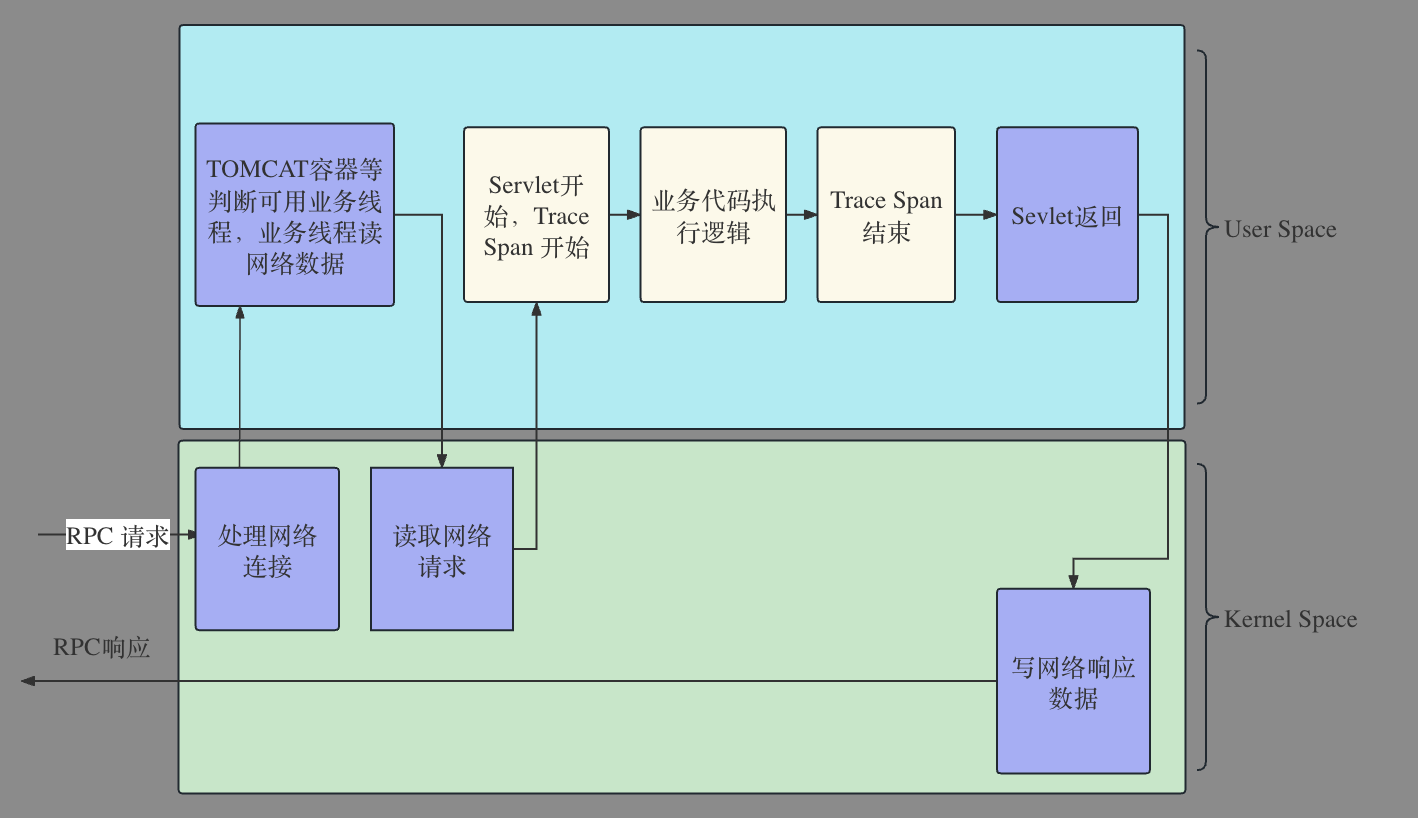
接下来讲的情况比较常见,对于绝大多数在线业务而言是IO密集型,所以当实例配置错误,扛不住流量高峰,表现和第一种情况不一致。表现出来是故障根因节点的上游节点出现很多调用下游的故障初因。主要原因是由于非CPU密集型不会消耗很多的CPU,但是其线程数量有限,每个线程都会被消耗在某些网络IO等待上,这里和锁场景又不一样,并不会产生很多代码锁。如果从APM视角来看就是发现客户端执行时间很长,服务端执行时间完全不匹配客户端执行时间的APM经典问题。如果从网络监控来看,能够看出故障节点有问题,但是并不清楚为什么有问题,也不知道该如何应急和复盘。本质的原因是故障节点由于配置错误,导致在流量高峰时所有的业务线程都被耗尽,但是由于Accept线程和IO线程仍然能够读取请求,只是找不到可用线程来处理业务,所以看到的现象是server端网络时间比Trace开始时间早一段时间。在Originx未来规划中,会接入线程满指标,这样结合线程满指标和下游节点耗时长更容易确认故障根因节点。

4、 在故障报告的报告头部呈现的是故障概览,这里关联了 TraceId 以及发生的时间,如果有必要可以使用 TraceId 去关联分析 Tracing 数据(具体截图可以参考之前案例)
5、在故障报告左边栏中,确认故障传播链路,近似于下图,通过这个数据可以确认在此次报告中故障节点判定是否正确(具体截图可以参考之前案例)
6、在故障根因中,能够看到根因结论,在多份报告中看到同样的根因报告,这个时候其实可以采取应急手段来恢复业务了,针对此种故障,恢复业务最好的手段就是扩容。这个故障其实还有其他几个可能,就是故障执行了长时间的 GC 导致线程不能执行,产生同样的现象。如何区分 GC 和线程慢?就是 GC 一般不会分布超过一分多钟,如果同样故障根因的故障报告分布在不同的时间段,那就明确了故障就是线程满
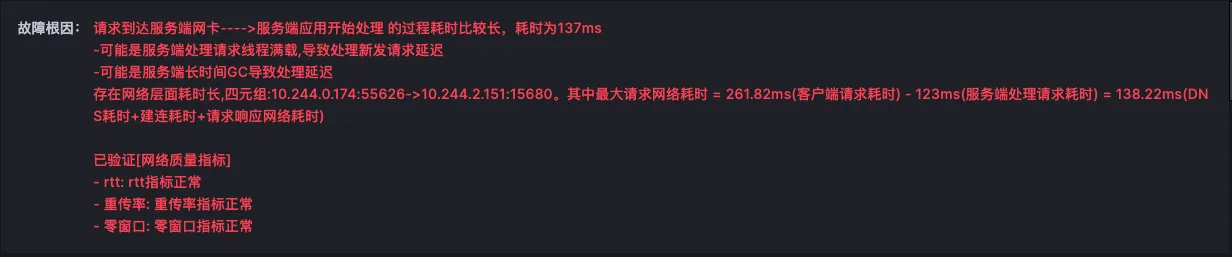
7、在故障报告中�,以下的数据都是为了提供证据链条来确认故障报告的准确性
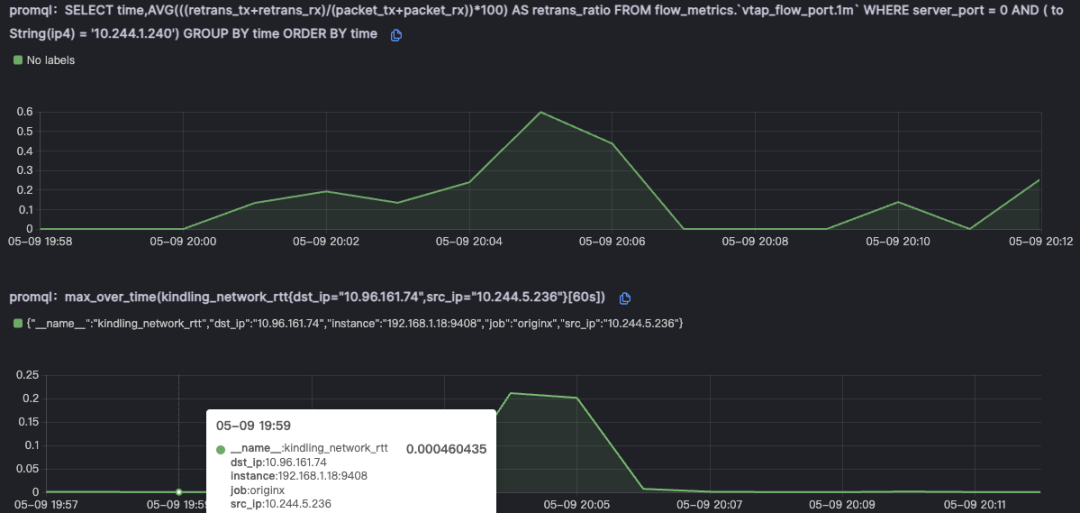
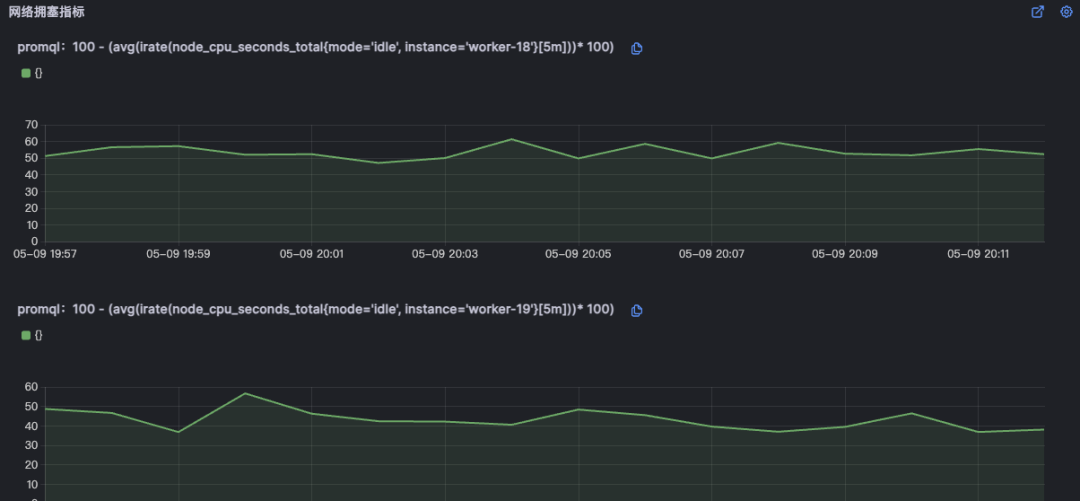
北极星指标(通过北极星指标,Originx 给出了异常幅度最大的异常方向,本截图的方向就是网络)

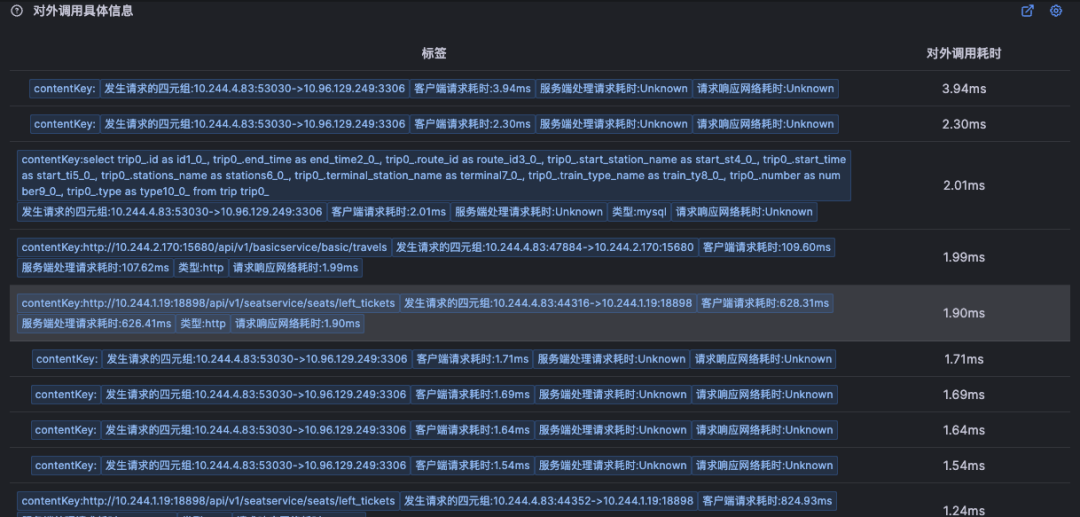
然后列出来所有的对外网络调用,这个网络调用是从内核层获取,可能会比 APM 看到的数据要多

针对最长的网络层面耗时,会对耗时进行分析,判断网络到底消耗在哪个网卡,我们可以看到标红的时间段说明了这段时间就是由于没有业务线程处理业务请求导致请求被 io 读取之后,而产生的额外时延

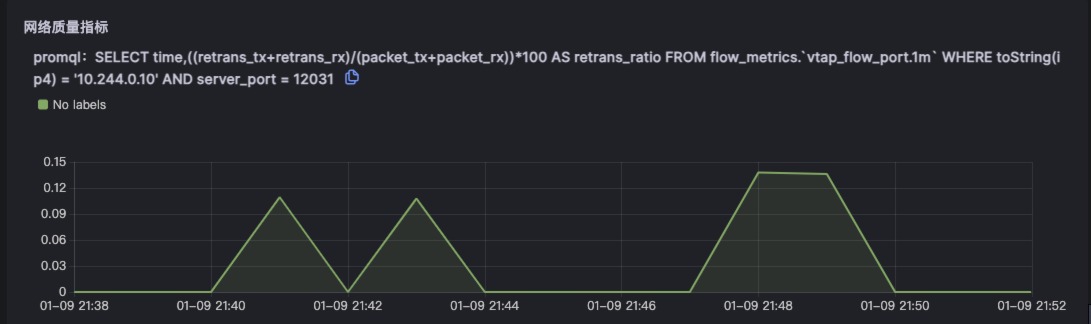
为了进一步证实不是由于网络导致的故障,会关联网络重传和丢包指标以证明网络没有问题