APO 如何快速判断云环境网络质量是否有问题
· 阅读需 8 分钟
APO 向导式可观测性平台

基于 eBPF 获取网络指标存在局限
eBPF 可以获取到网络 rtt 以及 srtt 等指标,这些指标确实能够反应网络质量,但是其实现是有局限性的,在当前绝大多数客户使用场景是不能反映网络质量的。
eBPF 在网络质量监控中的局限性主要体现在以下几个方面:
- TCP 建连时获取 srtt 指标: eBPF 在 BCC 中的实现是通过在 TCP 建连时获取内核维护的 srtt(smoothed round-trip time)指标。但是,TCP 连接建立完成后,内核并不会持续追踪每个网络包的传输时间。这就意味着在长连接场景中,srtt 指标并不能反映当前的网络质量变化。不仅仅是 BCC,我们自己开源的 Kindling 也有同样的局限,同时我们也对比了 datadog 等 eBPF 探针实现,发现都有这个问题。
- 长连接场景中的不足: 现代微服务架构中普遍使用长连接来减少连接建立和拆除的开销。然而,在这种场景下,内核并不会持续更新 srtt 指标,从而无法反映长连接期间的网络质量变化。
- 实验验证: 通过在 Tomcat 配置数据库连接池连接 MySQL,然后在两者之间注入网络延时故障的实验。在连接建立后,如果在任意一端注入延迟,BCC 的 srtt 指标将不会变化,因为内核不会追踪这些后续包的传输时间。
有没有其他方式判断网络质量
文章《孙英男-B 站大规模计算负载云原生化实践》是 B 站建立容器云过程的分享,他们在判断网络质量抖动的时候使用的 ping 来判断网络是否抖动。
使用 ping 来判断网络质量是大家常用的一个习惯,而对于 ping 的延时大家在实践中已经形成了一些认知,比如如果 ping 的延时超过 100ms,那么在线网络游戏估计玩不成了。
使用 Ping 来判断网络质量的优点
- 简单易用: ping 命令几乎可以在所有操作系统中使用,无需复杂的配置。
- 实时监控: 可以实时地检测网络延迟和丢包率。
- 网络连通性: 可以快速判断两个节点之间的连通性。
- 低开销: 相比其他方法,ping 对系统和网络资源的消耗较低。
使用 Ping 来判断网络质量局限性
- 误导性结果: 有时网络中的 ICMP 数据包优先级较低,可能导致延迟或丢包率看起来比实际情况更严重。
- ICMP 流量限制: 某些网络设备(如防火墙)可能会限制 ICMP 流量,导致 ping 测试结果不准确,甚至 ping 不通
- 大规模集群的限制: 高频 ping 造成的网络负载:在大规模集群环境中,对大量节点进行频繁 ping 操作,会产生大量 ICMP 流量,从而增加网络负载,影响正常业务流量。虽然一次 ping 的资源开销很小,但是集群规模大了之后,每个容器两两之间都进行 ping,这种消耗将是非常大的,大量的 ping 操作会消耗系统的 CPU 和内存资源,尤其是在需要同时监控许多节点的情况下。
如何才能低开销的完成网络质量的快速判断
虽然 eBPF 和 ping 包的方式都有一定局限性,但是 eBPF 的局限性受限于内核的实现,该局限没有办法突破的,而 ping 包的局限是可以突破的。
- 误导性结果的突破:用户认知的突破,如果发现 ping 延时很严重了,那真实的网络流量更加严重,这点突破很容易。
- ICMP 流量限制:防火墙的配置即可允许 ping 包的发生。
- 大规模集群的限制:大规��模集群中,如果两两相互都需要 ping 这是非常耗资源的做法,但是我们注意到实际场景中容器通过网络与其他容器交互的范围是有限制的,并不会和所有的容器都进行交互,这点是有优化空间的。
大规模集群适用低开销基于 ping 包的网络质量评估方案
开源项目 coroot 有一个非常好的思路,他们使用了一个叫做 pinger 的组件,该组件工作原理如下:
- 基于 eBPF 获取容器之间的关系图,并不是获取 SRTT 等指标
- 根据节点关系图来发送 ping 包,上游节点对下游节点进行 ping,这样能够极大的降低任意两两 pod 互相 ping 的开销
但是 coroot 的 eBPF 实现要求内核版本高于 4.14,国内还有很多操作系统停留在 centos7 系列的用户,他们是没有办法用 coroot 的实现。
我们在 coroot 的基础之上,针对国内的环境做了优化,主要优化如下:
- 通过读取 proc 目录下来获取关系图,而不是通过 eBPF 获取关系图,这样就降低了对内核版本的依赖
- 沿用了 coroot 原有 pinger 组件的思路,上游节点对下游节点进行 ping,极大降低任意两两 pod 互相 ping 的开销
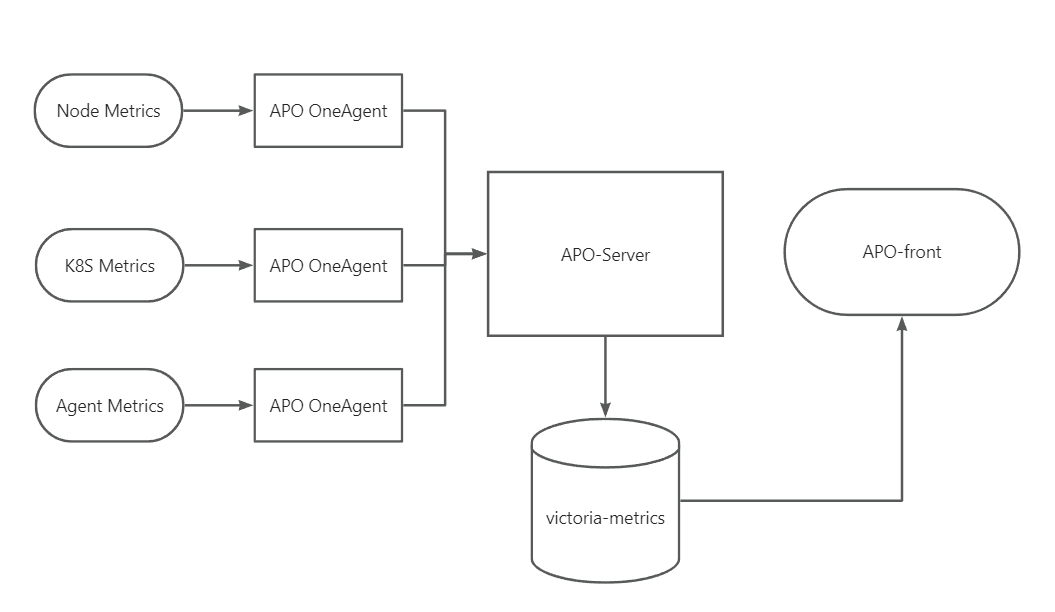
- 数据最后通过 exporter 暴露到 prometheus 或者 victoria metrics 中
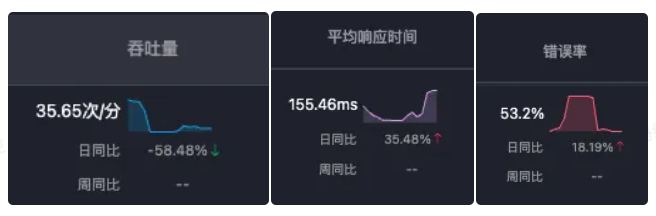
最终效果图,展示 srcip 到 dstip 的 ping 值
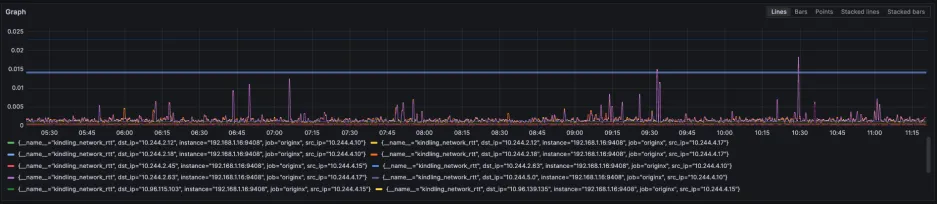
题外话:我们不去修改 coroot ebpf 代码使其适配低版本内核主要是基于投入产出比,适配低版本内核需要调整代码量较大,我们通过 eBPF 采集的北极星因果指标是适配了低版本内核的。




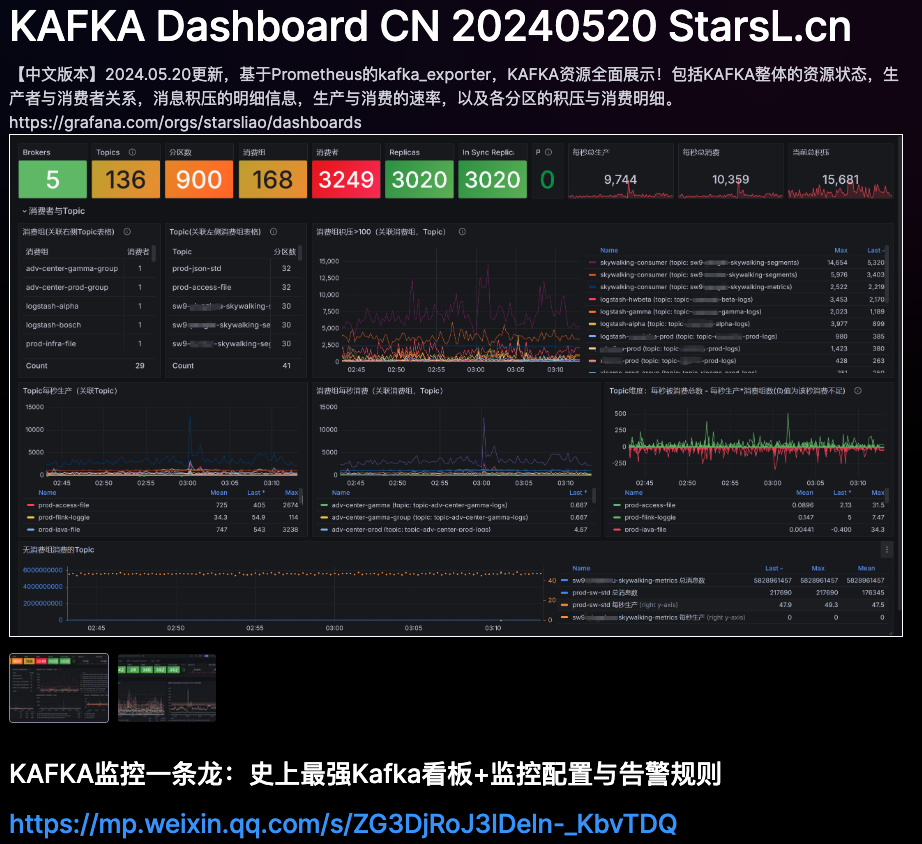

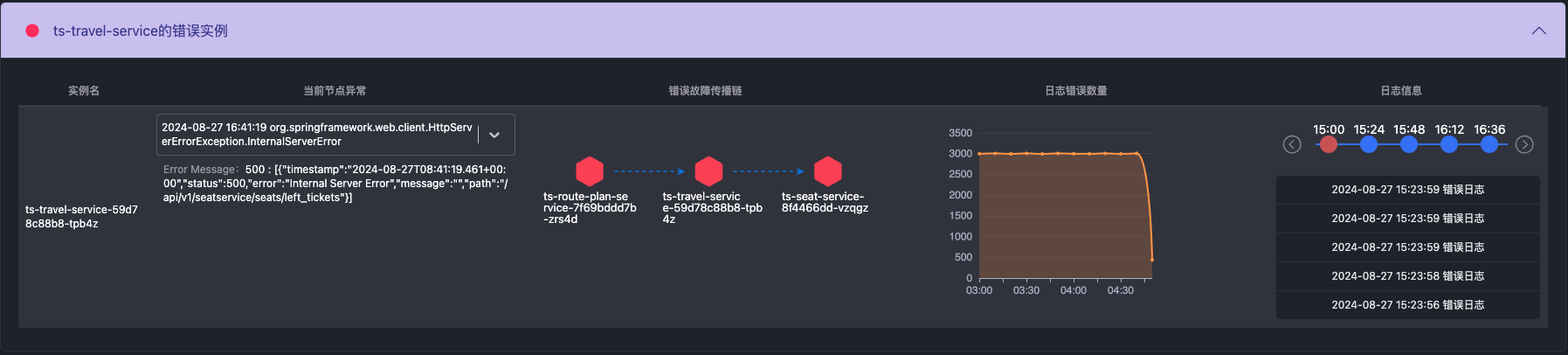
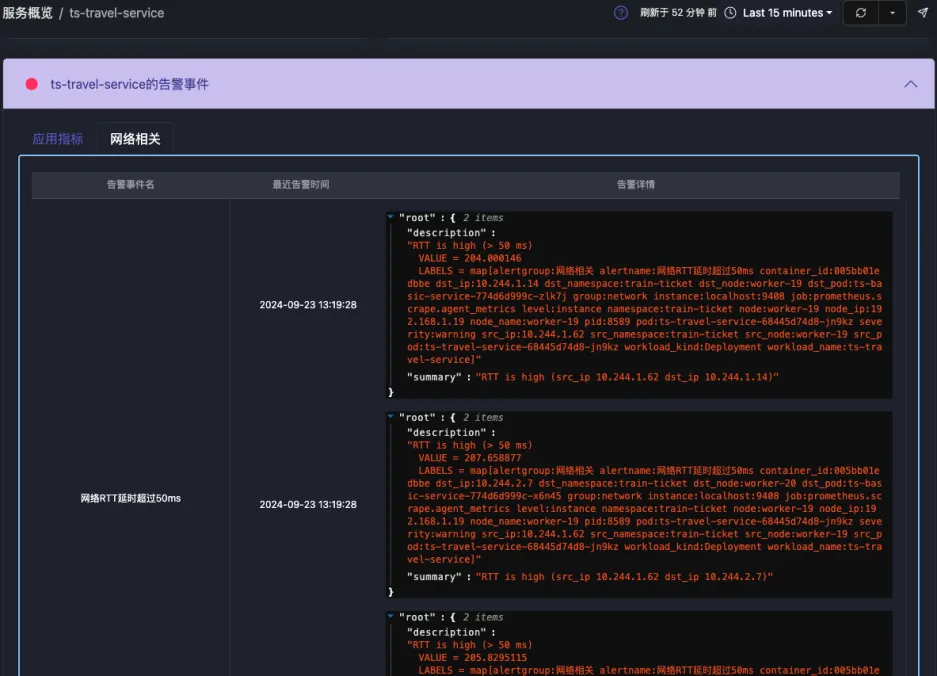
 带有Exception的日志
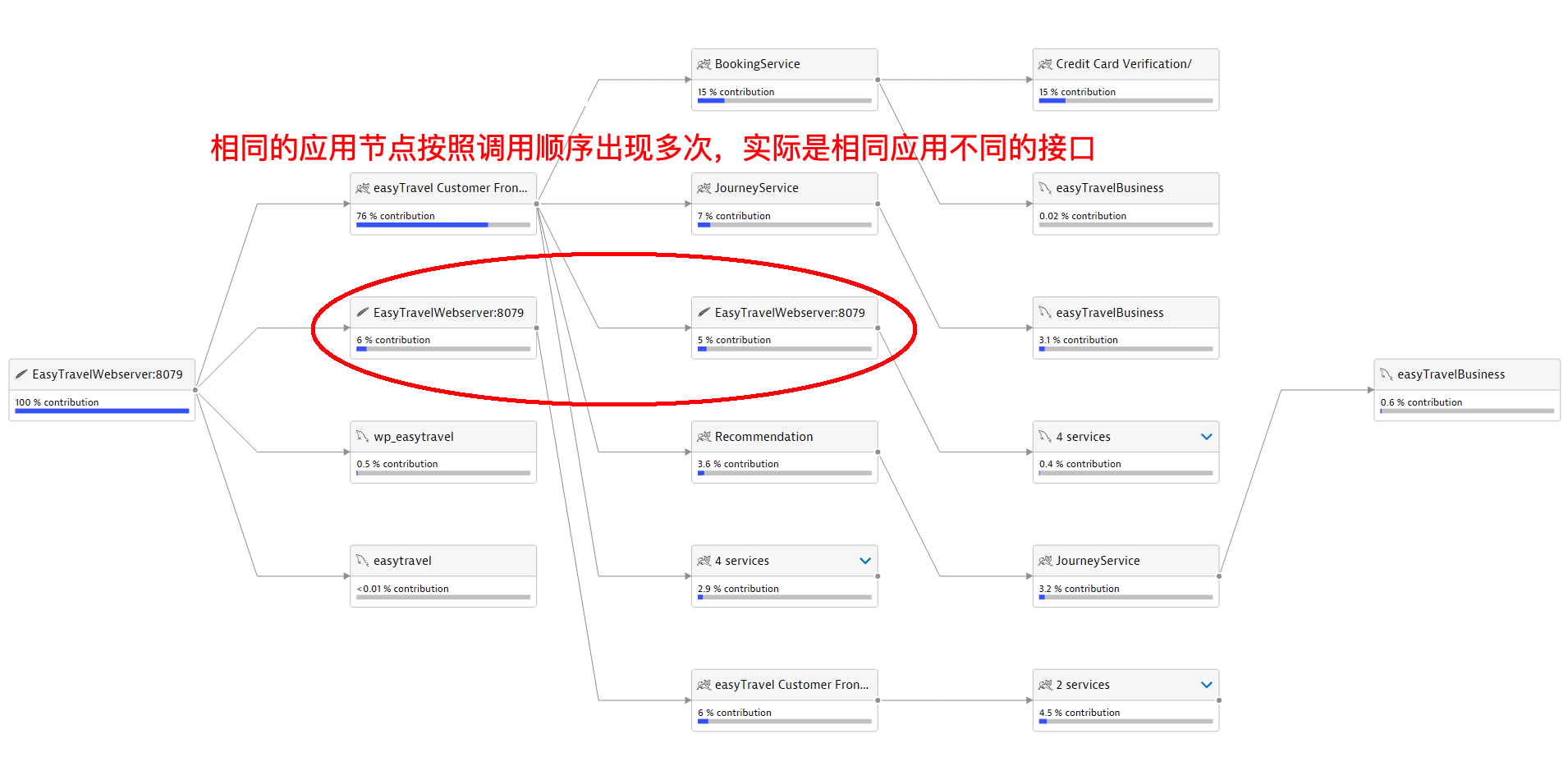
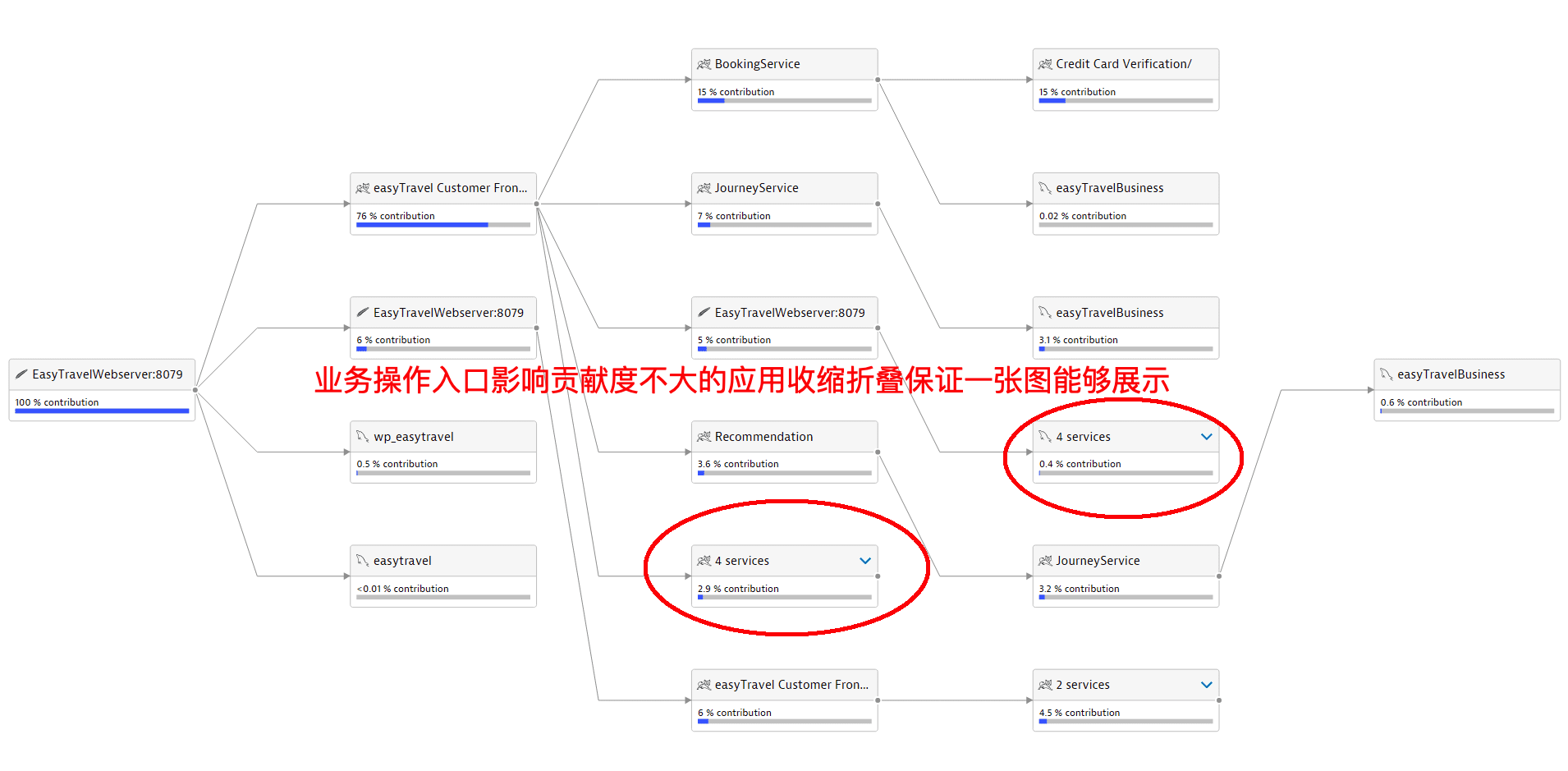
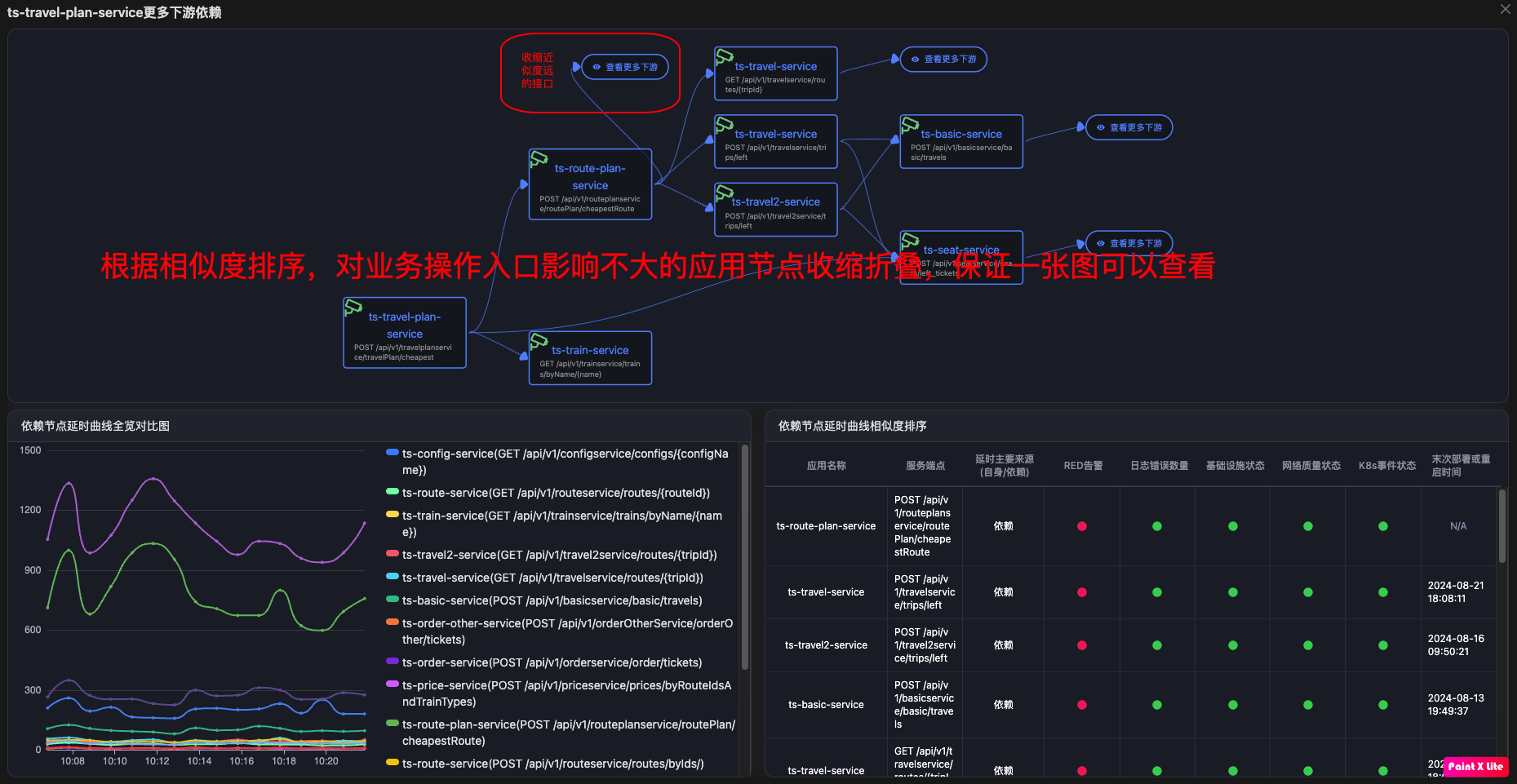
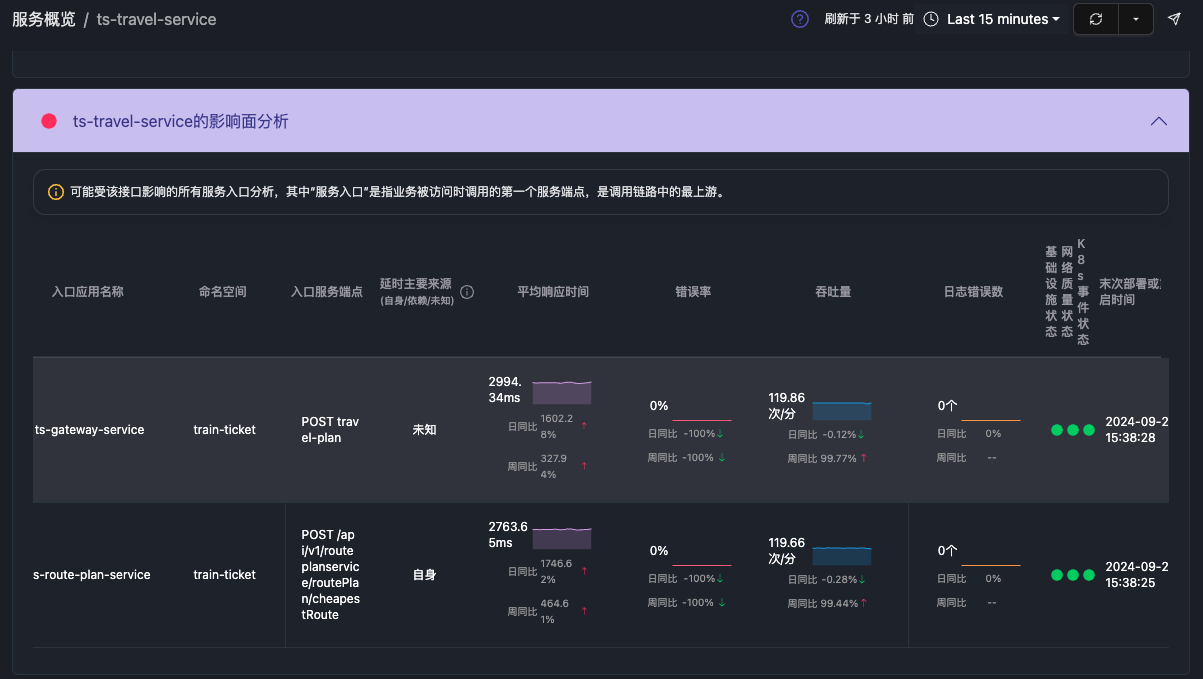
带有Exception的日志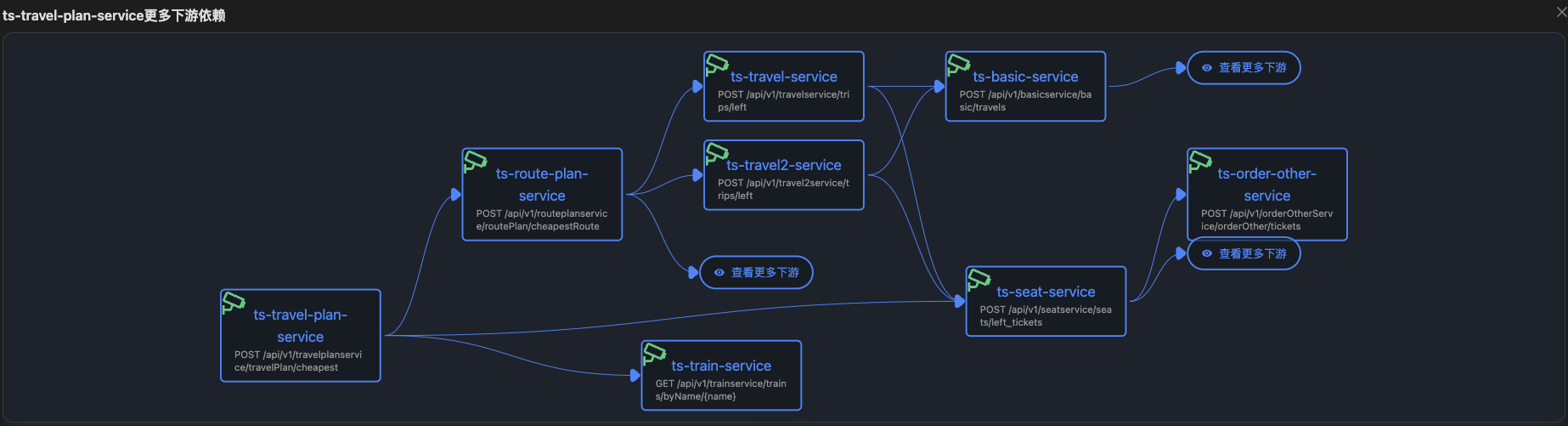 URL级别拓扑每个节点代表service+URL
URL级别拓扑每个节点代表service+URL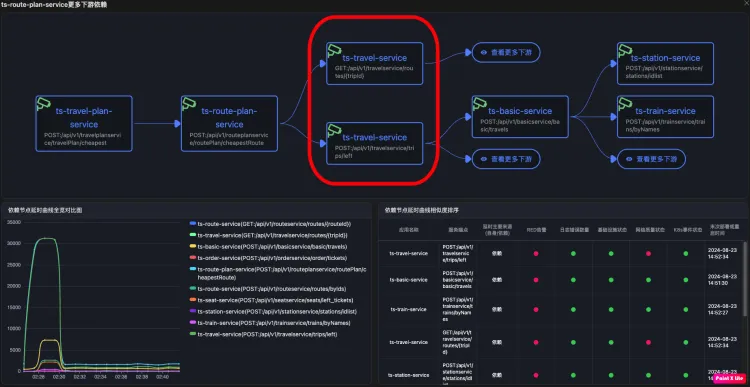 同一个服务不同的URL会作为不同节点出现
同一个服务不同的URL会作为不同节点出现








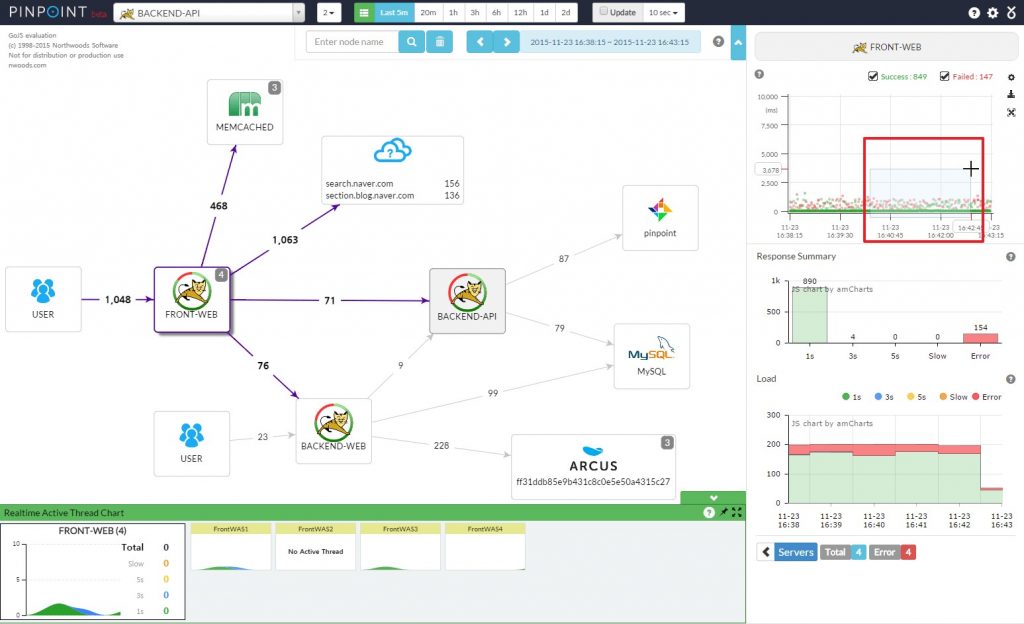 pinpoint的应用级别拓��扑
pinpoint的应用级别拓��扑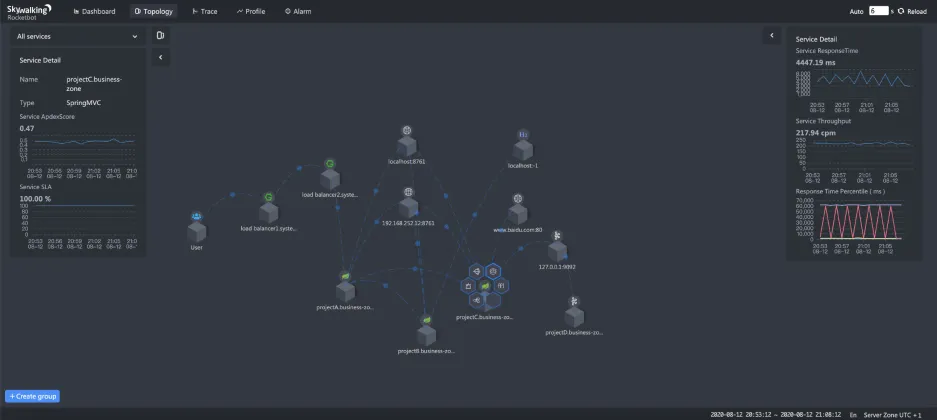 skywalking的应用级别拓扑
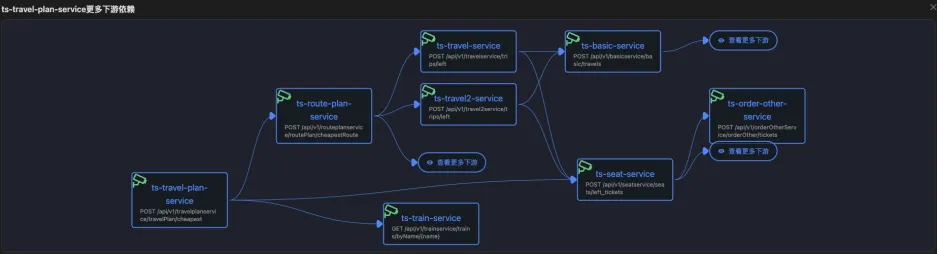
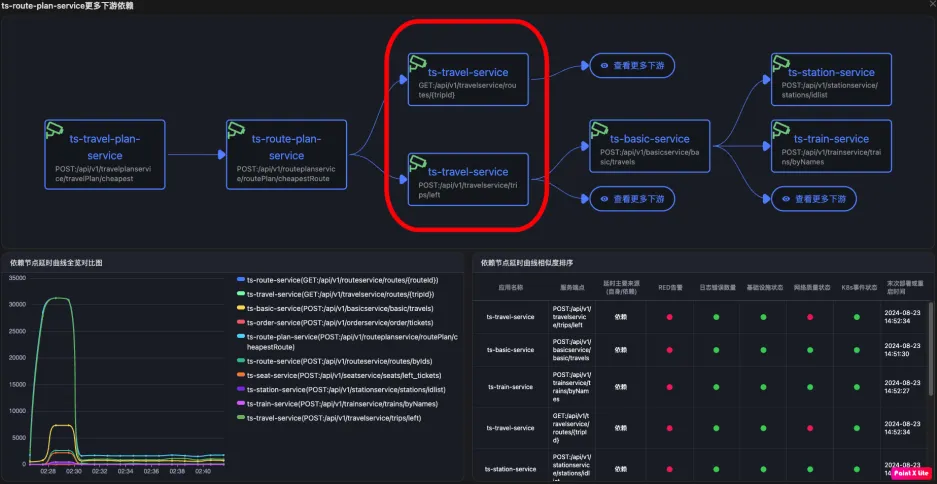
skywalking的应用级别拓扑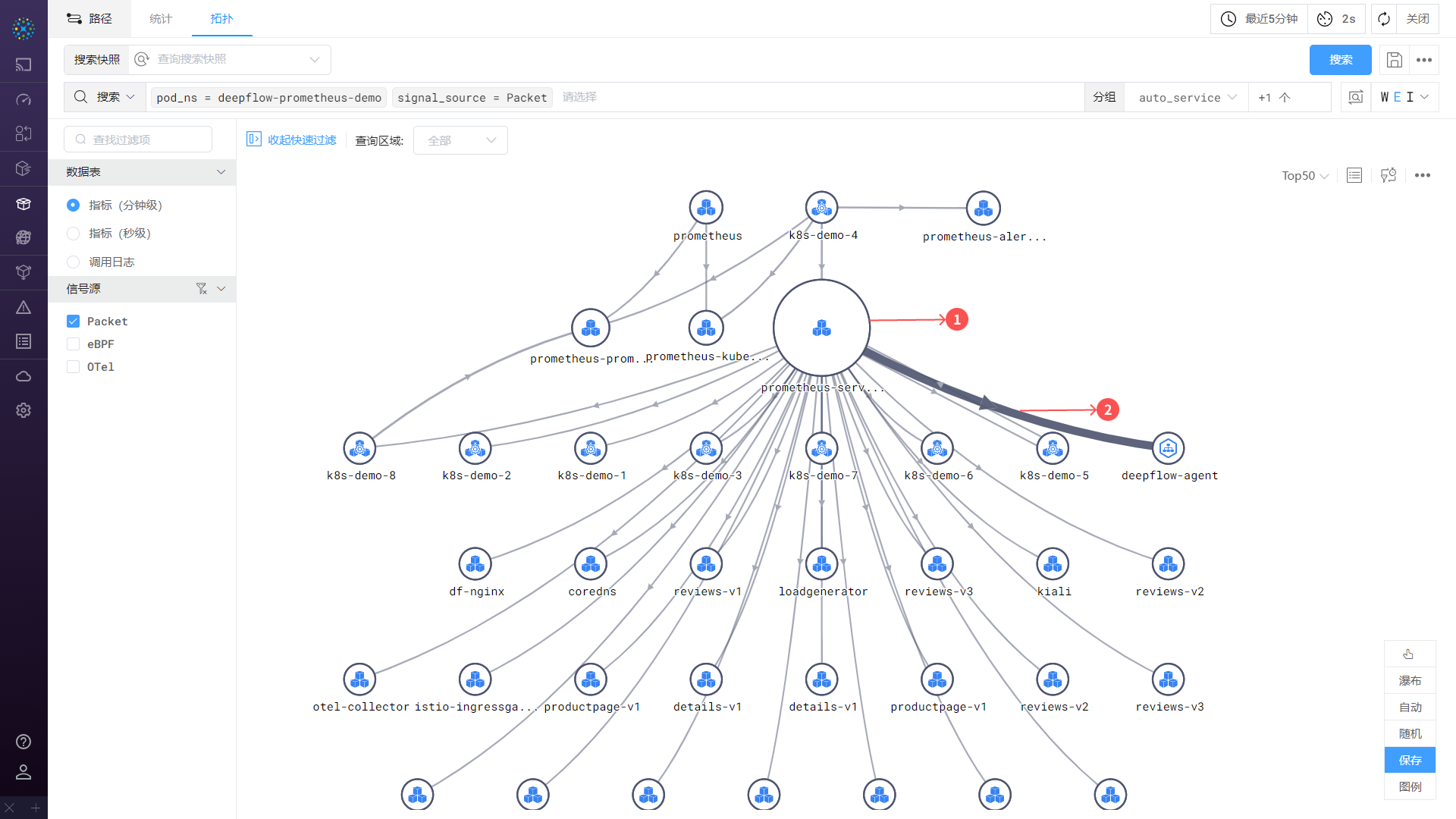 deepflow基于流量的应用级别拓扑
deepflow基于流量的应用级别拓扑