我们这样做「故障分析AI智能体」,邀请你来试试

在可观测性领域,我们始终在追问一个问题:当系统出故障时,为什么定位和恢复还要这么复杂、这么慢?
我们从一开始就在做一件事——降低产品使用门槛,让你在最紧急的时刻,能用最快的方式找到根因、恢复业务。
我们不断琢磨,不断实验:到底怎样才能真正做到?
渐渐地我们发现,如果继续沿用传统的可观测性思路,终究会撞到瓶颈。因为人力去关联、比对、排查的方式,已经跟不上复杂系统的节奏。
而这正是 AI Agent 能够改变的地方。
AI 的价值,不只是“帮你分析链路数据”,而是彻底改写人与可观测性工具的关系。它可以主动思考、串联不同来源的线索,把人从一堆碎片化的数据里解放出来,直接对话式地给出分析和方向。
这就是为什么我们坚信:未来的可观测性,一定会被 AI Agent 重塑。
基于这个想法,我们开发了故障分析智能体:Syncause。
故障发生时,AI Agent 能做什么?
让我们先理清楚故障处理的本质。当故障发生时,我们的处理过程通常是:
发现 → 响应 → 诊断 → 恢复 → 复盘。
但在实际的故障诊断和解决过程中,我们发现可以分为三个关键阶段:
第一阶段:快速定向。 故障发生了,但到底是什么类型的问题?是应用层的bug?数据库压力过大?网络连接异常?还是��外部依赖服务挂了?这个阶段的目标是缩小排查范围,找到大致方向。
第二阶段:紧急止血。 知道了问题方向后,如何最快恢复业务?回滚代码?切换流量?扩容资源?还是重启服务?这个阶段的核心是快速止损,让用户能够正常使用。
第三阶段:深度追因。 业务恢复后,找到导致故障的根本原因。是哪一行代码?哪个配置项?哪次变更?这个阶段是为了彻底解决问题,避免再次发生。
当然,现实往往没有这么理想化。简单的问题可能在第一阶段就找到了根本原因,复杂的问题可能需要多个轮次的循环。但这个框架帮助我们更清晰地思考 AI Agent 应该解决什么问题。
Syncause 目前主要聚焦解决前两个阶段的问题:
- 它会先帮你快速缩小范围,告诉你问题出现在应用或主机上;
- 它会自动把指标、日志、链路,甚至 eBPF 收集到的内核层面信号,串在一起;
- 它会判断出问题是 CPU、磁盘、网络,还是更高层的调用;
- 然后,它还会给出切实可行的恢复建议,让你在压力最大的时刻,能快一步止损。
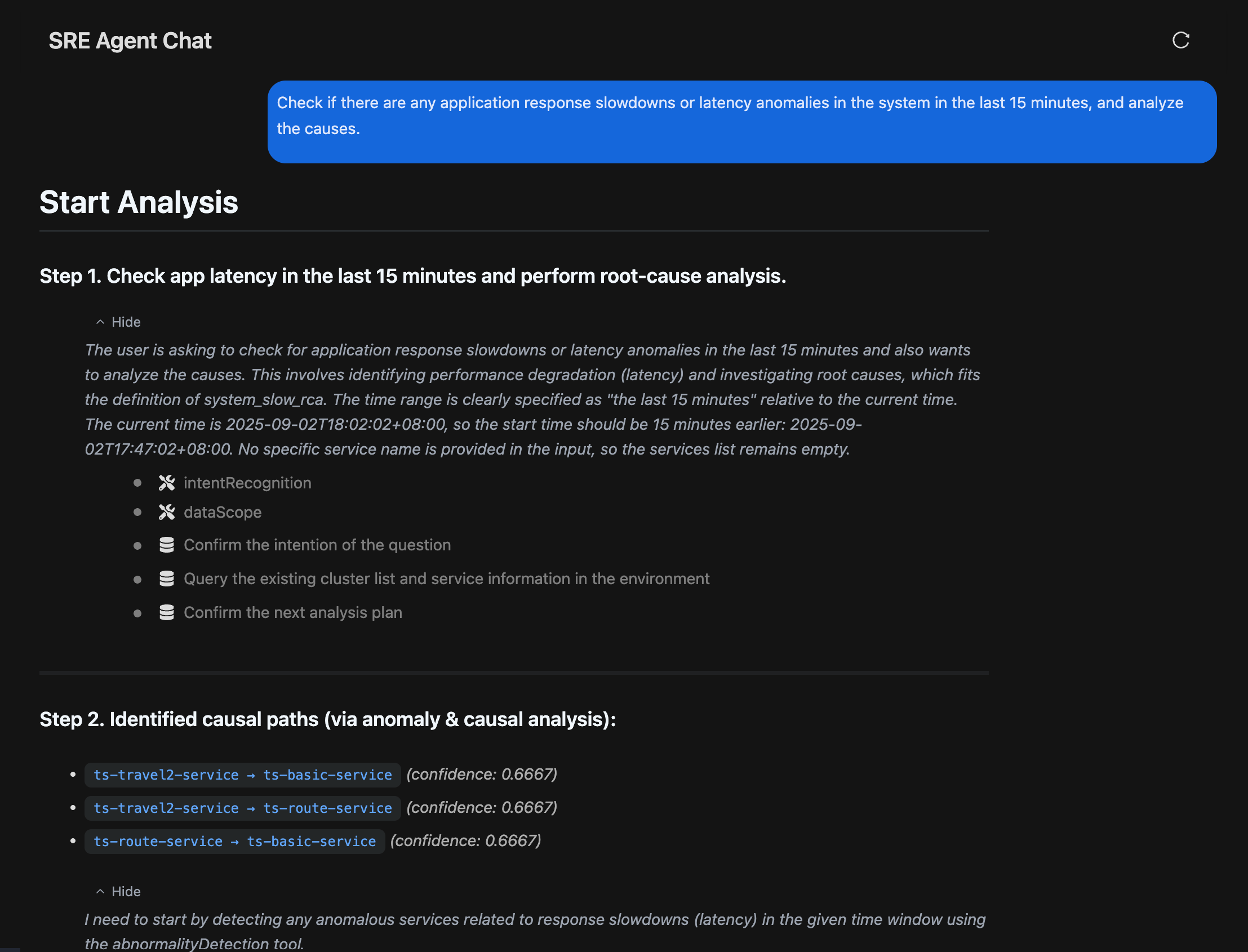
另外,Syncause 被设计成一个开放的平台,能够集成各类可观测产品的数据。无论你用的是Prometheus、Jaeger、Grafana、ELK,还是商业化的APM工具,Syncause 都能帮你把这些分散的数据整合起来,统一分析。
我们准备了问答环境,你可以亲手试试
Syncause 还在内测阶段,但我们搭建了一个 Sandbox 环境可以直接测试效果。
Sandbox 里面跑着一组测试应用,这些应用会“故意”出现各种问题。你只需要直接跟 Syncause 对话,让它来帮你分析原因、提出方案。
甚至,你也可以自己重新部署一个应用,然后注入不同的故障,看看 Syncause 如何一步步陪你走过排查的过程。
我们想把 Syncause 打造成一个真正对你有用的产品。所以特别欢迎你来试用,甭管是建议还是批评,都尽管告诉我们。
如果你感兴趣可以加入 Waitlist,成为早期用户与我们共创,和我们一起把这个 Agent 打磨到极致,我们会提供永久免费使用。
点击链接:https://sandbox.syn-cause.com 即可进入Sandbox环境。