Syncause 智能体推理视图:让根因分析可验证、可信任

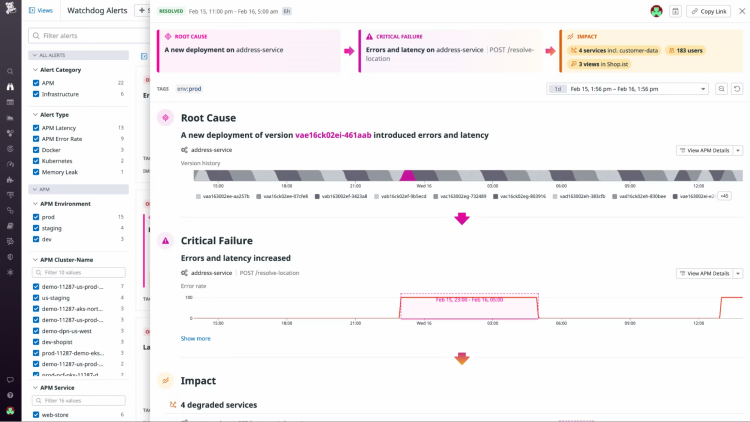
我们的 AI SRE 智能体 Syncause 致力于通过AI技术提升故障诊断效率。前几天,我们发布了根因分析场景的准确率测试结果。在Train Ticket微服务系统的根因定位任务中,Syncause的AC@3准确率(前3候选根因命中真实故障的概率)达到96.67%,成为目前公开可复现的最高水平。
那么,准确率高就足够了吗?几年前AIOps也承诺较高的根因分析准确率,但在实际落地中因缺少可解释性而不被信任。所以,高准确率仅是起点,在实践中,AI结论的可信度与可验证性同样关键。准确率再高,没有可见的证据,也难以建立真正的信任。
准确率之外的信任困境
生产环境故障的决策成本极高,工程师无法将关键判断权交给一个“不可解释”的系统。即使AI输出正确结果,若无法追溯其推理路径,仍可能导致以下问题:
- 信任缺失:结论缺乏证据支撑,难以形成团队共识;
- 重复验证成本:工程师需独立复核AI结论,抵消效率优势;
- 风险控制失效:无法复盘错误推理逻辑,阻碍系统迭代优化。
为此,Syncause推出推理视图功能,通过结构化、可视化的推理链路,实现AI诊断过程的全透明化。
推理视图详解
树状结构化证据展示推理路径
在 AI 根因分析中,如果工程师只能看到最终结论,就很难判断其背后的验证路径。而复杂系统的诊断往往涉及多层级、多假设的推演过程。
推理视图通过 树状结构 展示 AI 的推理步骤,包括:
- 假设生成:基于故障上下文提出初步假设,如基础设施资源问题、依赖服务问题、数据库问题等;
- 验证步骤:通过指标、日志、链路或事件验证假设的合理性;
- 状态标记:节点状态(正常/异常)直观反映诊断进展。
异常路径通过高亮标记快速定位关键问题,从而帮助工程师快速锁定关键路径。

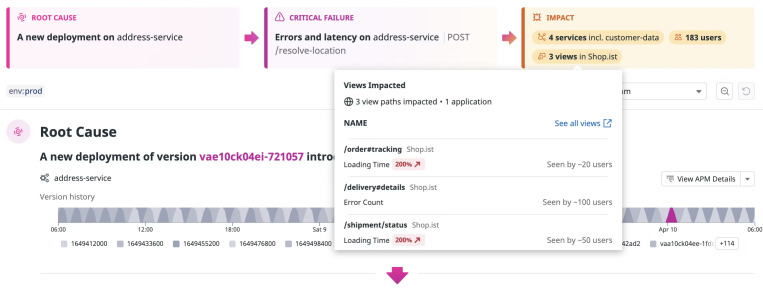
可视化证据:即时验证上下文
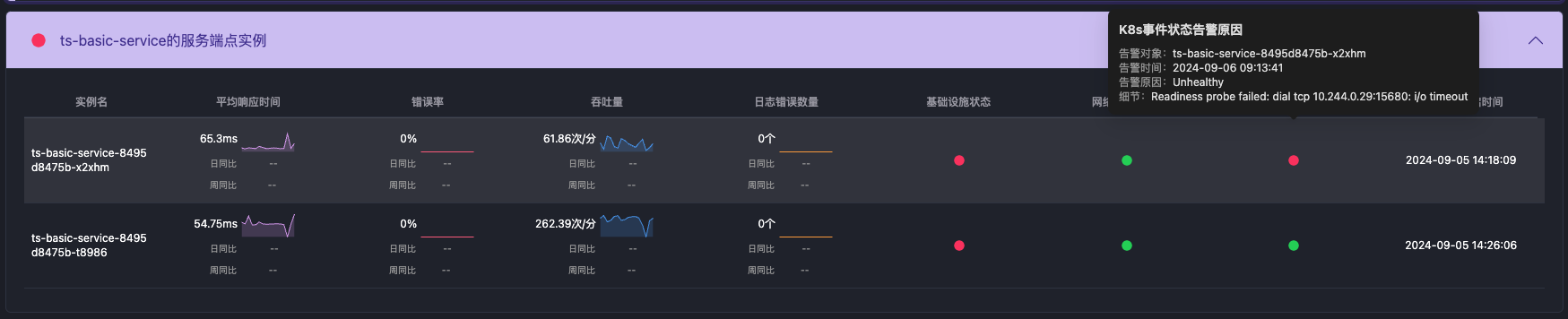
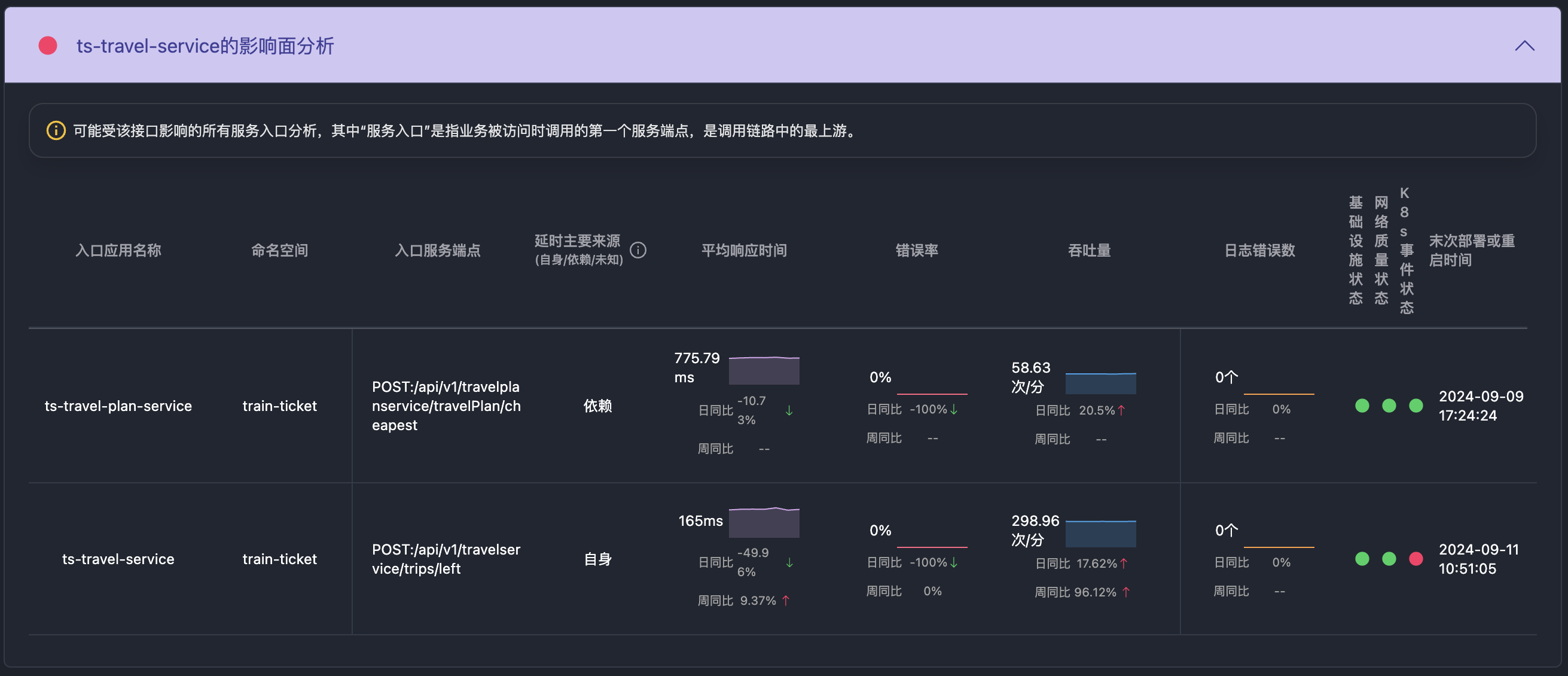
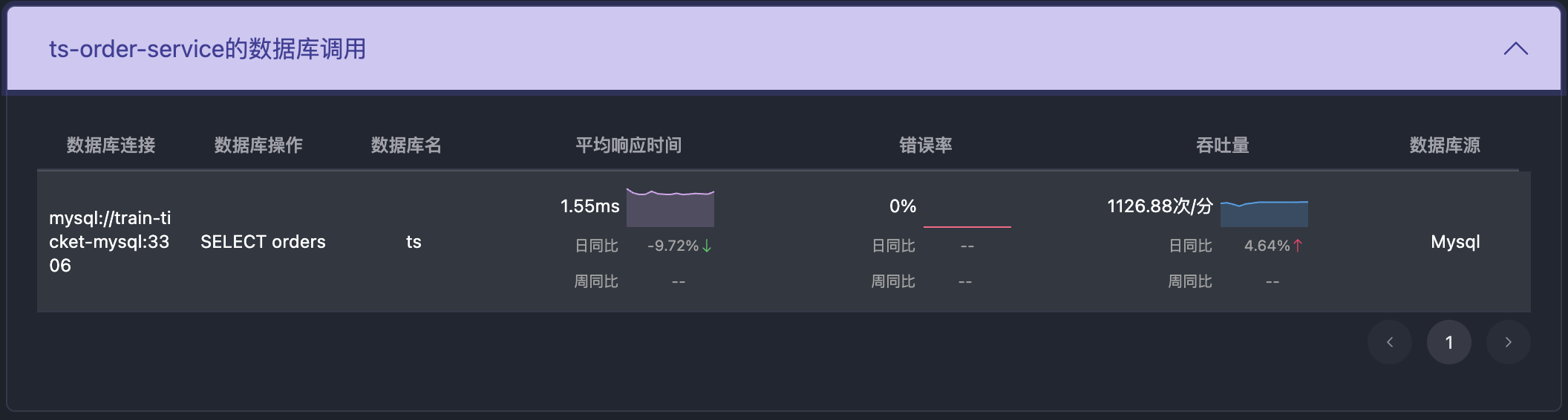
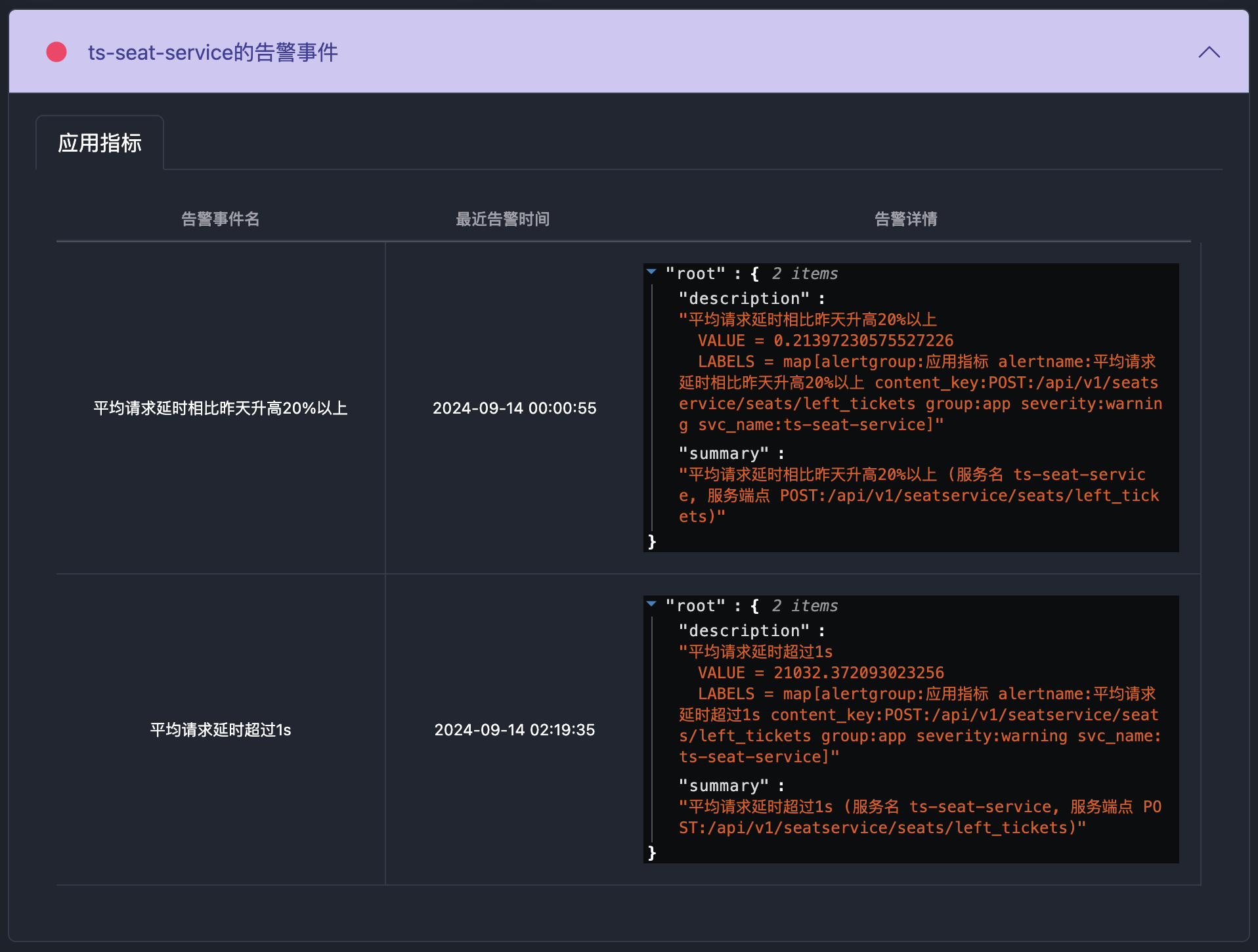
推理链条的可信度依赖证据质量。因此,我们将每个推理节点都设计为可展开查看证据来源和内容,包括指标曲线(如CPU利用率、请求延迟)、错误日志、上下游调用链、数据库慢查询日志等。
所有数据来自实际监控系统或日志源,在这里可以快速判断 AI 的推理是否符合事实,而不必跳转回原有的监控系统中进行验证。

防幻觉:算法与大模型的协同
在故障诊断中,避免幻觉比生成答案更重要。为实现这一点,我们采用了混合式的推理架构:
- 由确定性算法执行异常检测:采用统计方法、规则、特定模型,确保不会“编造”异常
- 大模型负责抽象理解、上下文串联与推理方向选择:负责抽象推理与上下文关联分析,生成可解释的诊断路径。
两者的结合既保证了诊断的严谨性,又保留了大模型对复杂场景的泛化能力。
延伸价值:从可信验证到效率提升
推理视图不仅解决信任问题,更通过降低重复验证成本提升整体故障排查效率:
- 减少人工复核:AI已验证的路径可直接作为诊断参考;
- 支持流程自动化:未来将支持自定义检查流程的集成,AI自动执行标准验证步骤。
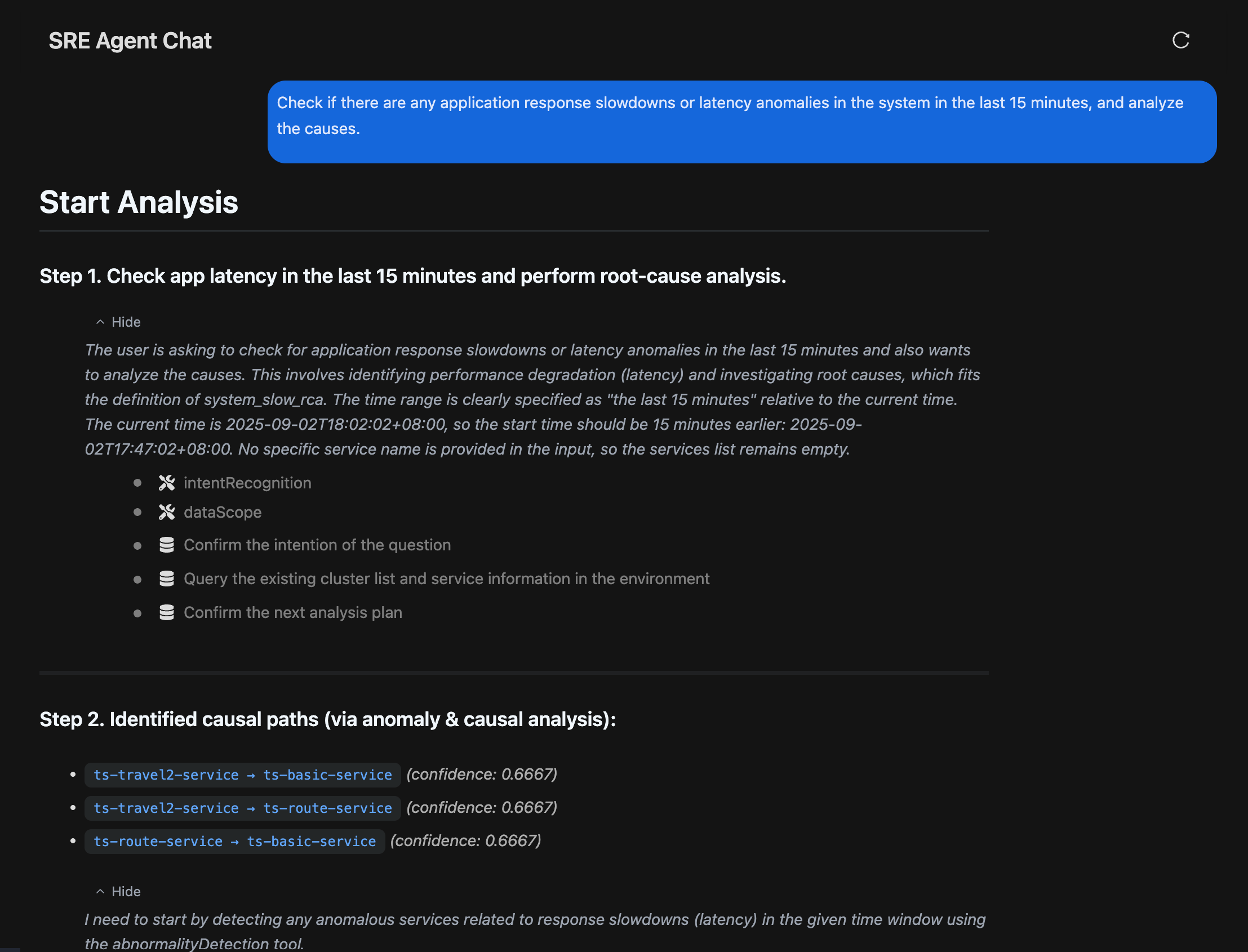
演示
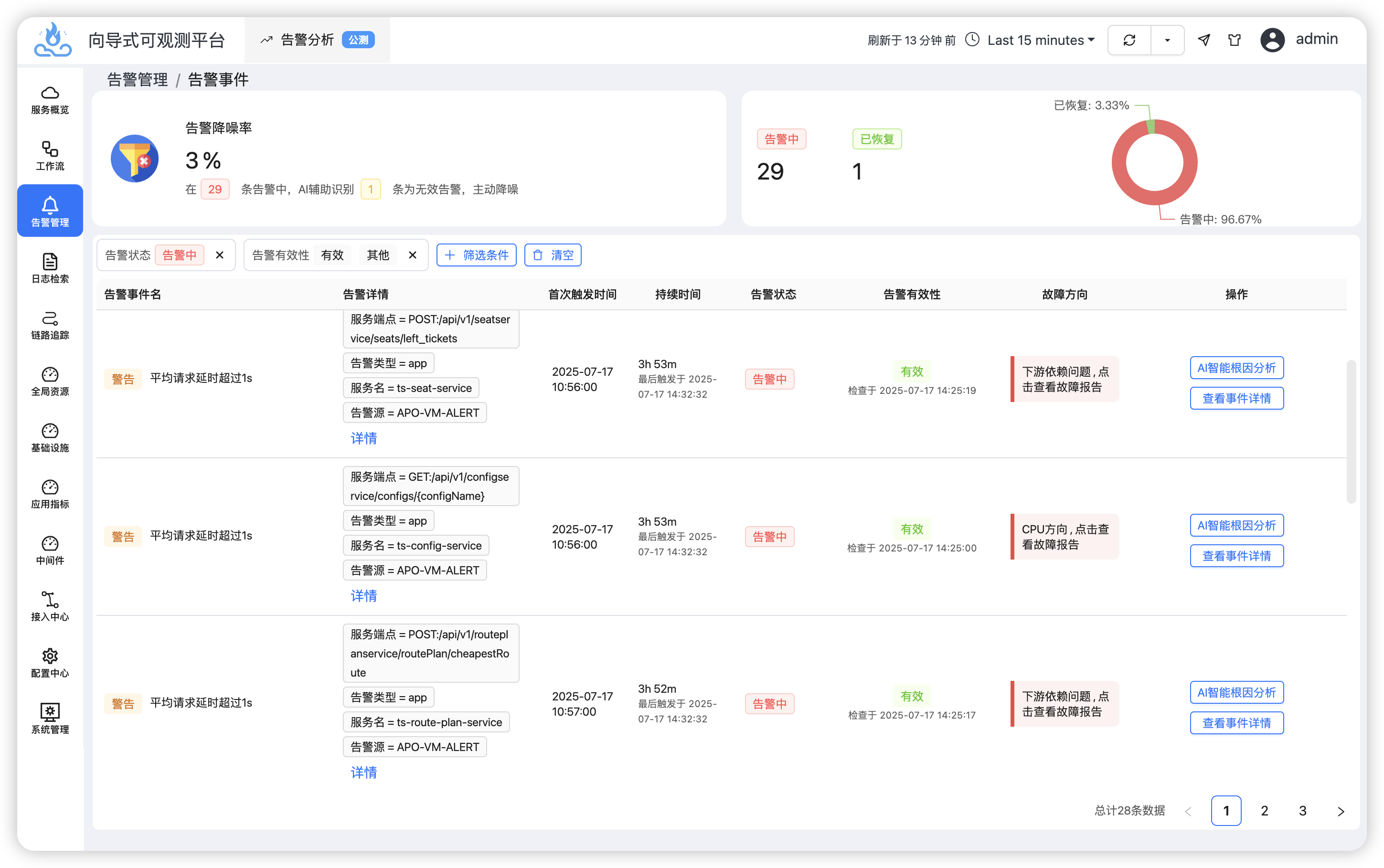
当用户抱怨访问速度变得很慢,我们可以第一时间向Syncause提问:“用户抱怨系统访问很慢,帮我做根因分析”,Syncause会马上响应并开始查��询数据进行分析。

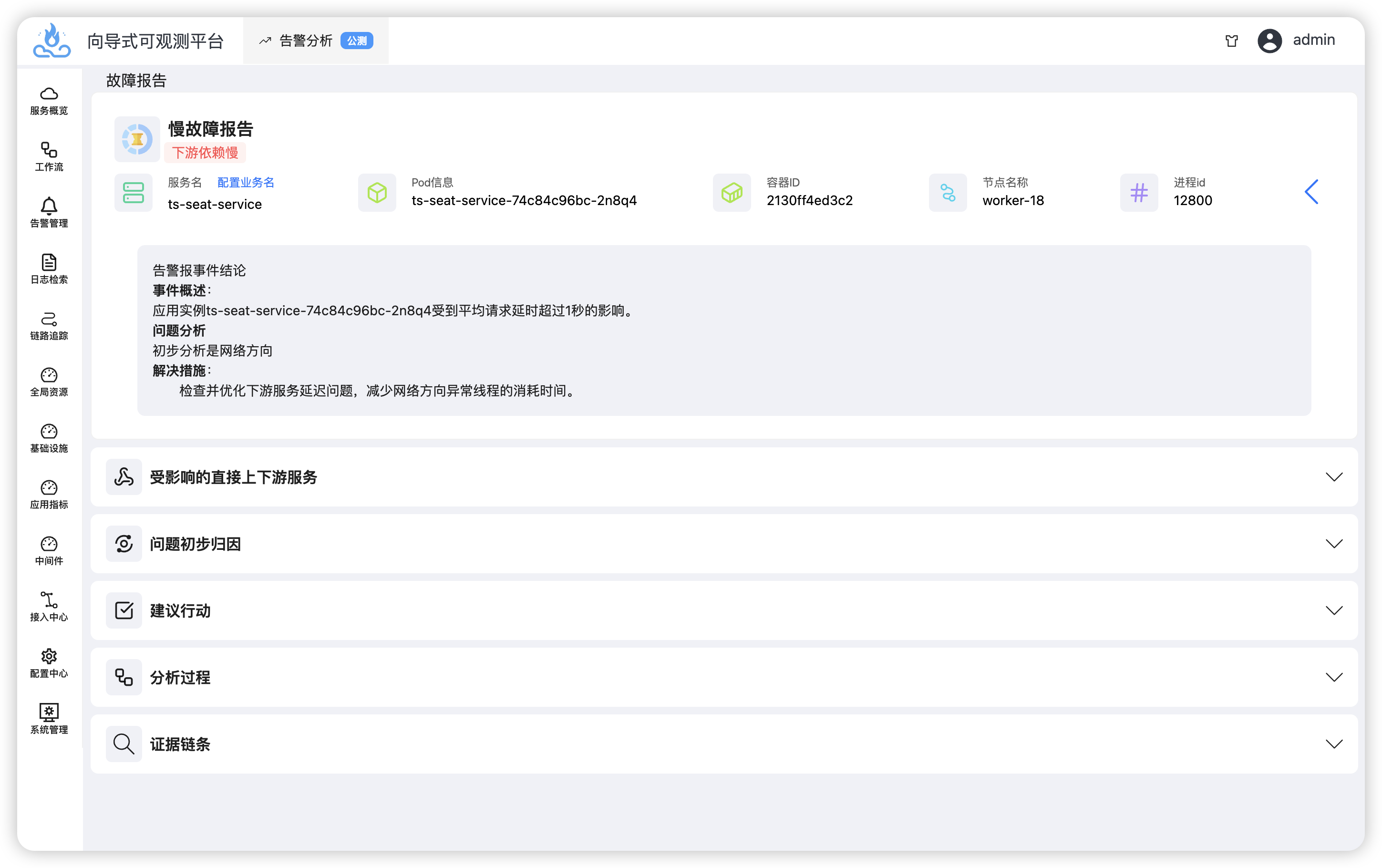
AI通过检查指标、链路等数据执行多步骤分析,得出结论,是由于ts-price-service的CPU使用率异常升高,导致延时影响了整体,在“结构化证据”中可以查看推理路径:

AI针对服务检查了依赖服务、依赖数据库、基础设施和自身代码执行情况,发现CPU资源升高是罪魁祸首。
共建AI运维新范式
我们相信,AI在运维领域的终极形态不是"替代工程师",而是成为可信赖的智能协作者。它的每一步操作都要有记录,每一个结论都要有依据,每一次失败都可以复盘。
而这,才是人类与AI协作最该有的样子。
Syncause 目前已经开放注册,如果你希望在真实场景中试用,欢迎通过微信联系我们或通过官网注册使用。
我们期待与先进团队一起验证、改进并推动这项能力在实际生产环境中的落地。