Kindling-OriginX 在快手 Staging 环境的异常诊断效果分享

业务可用性问题的快速诊断,历来是行业互联网公司面临的重大挑战,快手也不外如是。Kindling-OriginX的体系化设计理念快速打动了我们的工程师。快手随即开始了内部真实业务的验证落地;落地过程中,Kindling-OriginX能高效覆盖大部分线上问题的快速定界,其中20%可直接给出根因,缩短业务影响时长。未来,我们希望与Kindling-OriginX在异常场景和诊断效率上继续深度合作,进一步缩短业务异常的恢复时长,以及提升工程师研发幸福感。
---周辉,容器云稳定性团队负责人
Originx注:快手团队对根因的要求比较高,比如一般团队遇到请求被锁住,得到锁的代码堆栈就够了,但是快手团队要求更高,更希望知道为什么代码发生了锁住originx目前还只能给出哪段代码堆栈导致锁住。
目的
愿景:缩短对线上稳定性问题的定位时长,帮助业务快速止损,减轻日常问题排查的人力成本。
1.是否能在在公司落地,给实际的问题诊断带来帮助;
2.为问题诊断提供借鉴思路:通过ebpf采�集系统层面指标,打通业务请求链路。
结论
OriginX 诊断能力
结论:能够进行问题的定界。
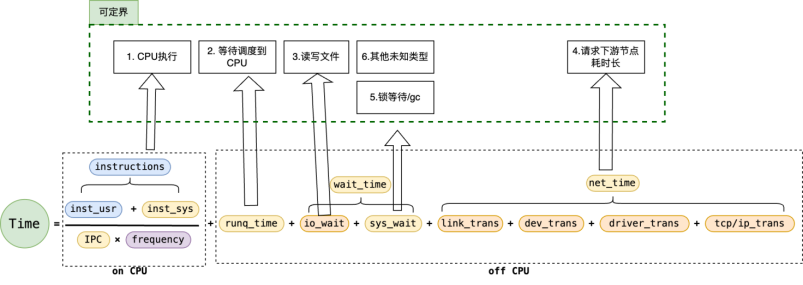
延时耗时示意图
初步分支定界
可以对问题起到初步分支定界的作用,能初步判断出是问题哪个或哪些类别,即 :
1.CPU 执行(onCPU)
- 是否能够下钻
- 对 frequency 问题的判定效果?可以设置 frequency 吗【Originx 目前支持各种频率 CPU 采样,但是需要重启探针】
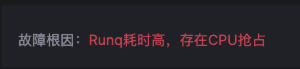
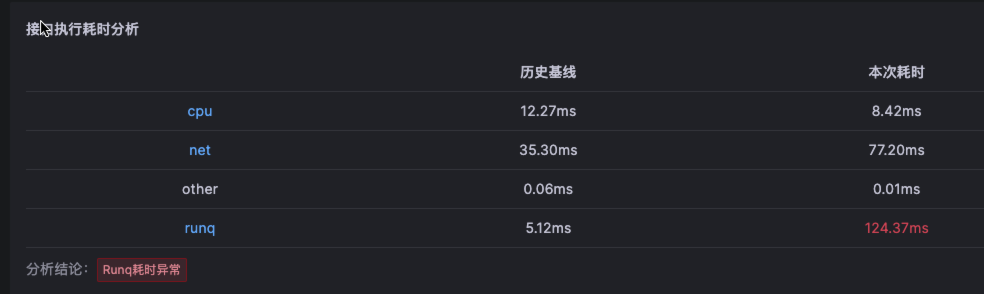
2.等待调度到 CPU(RUNQ)
- 较少发生,主机有较高的负载的场景
3.读写文件(VFS 的直接读写关联存储相关问题)
- 如何确定拿到的文件和请求是相关
- Originx 通过与请求过程中的系统调用关联,按照时间能精准匹配到请求时的系统调用
4.请求下游节点耗时长(网络调用)
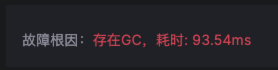
5.锁等待或内存 GC 类型(futex 等)
- 如何确定拿到的这个锁和这个请求有关
- Originx 通过与请求过程中的系统调用关联,按照时间能精准匹配到请求时的系统调用
Originx 不擅长的故障种类:
1.对 CPU 算力分层类、夯机类、硬件类等问题的分析 Kindling-OriginX 诊断相对比较薄弱;
2.对Java 类服务的支持友好,接入 Kindling-OriginX 需要适配公司的 “全链路追踪系统”。
Originx 存在优化空间
快手使用的 Originx 版本在确定故障报告时存在多种可能性,需要人为排除噪音干扰因素。
1.由于一个采样报告只能得出一种结论,故障发生所在的时间段内若干采样点产生的多个报告,可能结论不一致,需要自己来判断具体是哪方面原 因占主导,排除干扰因素; 有时会出现----未发现明显异常的结论,如
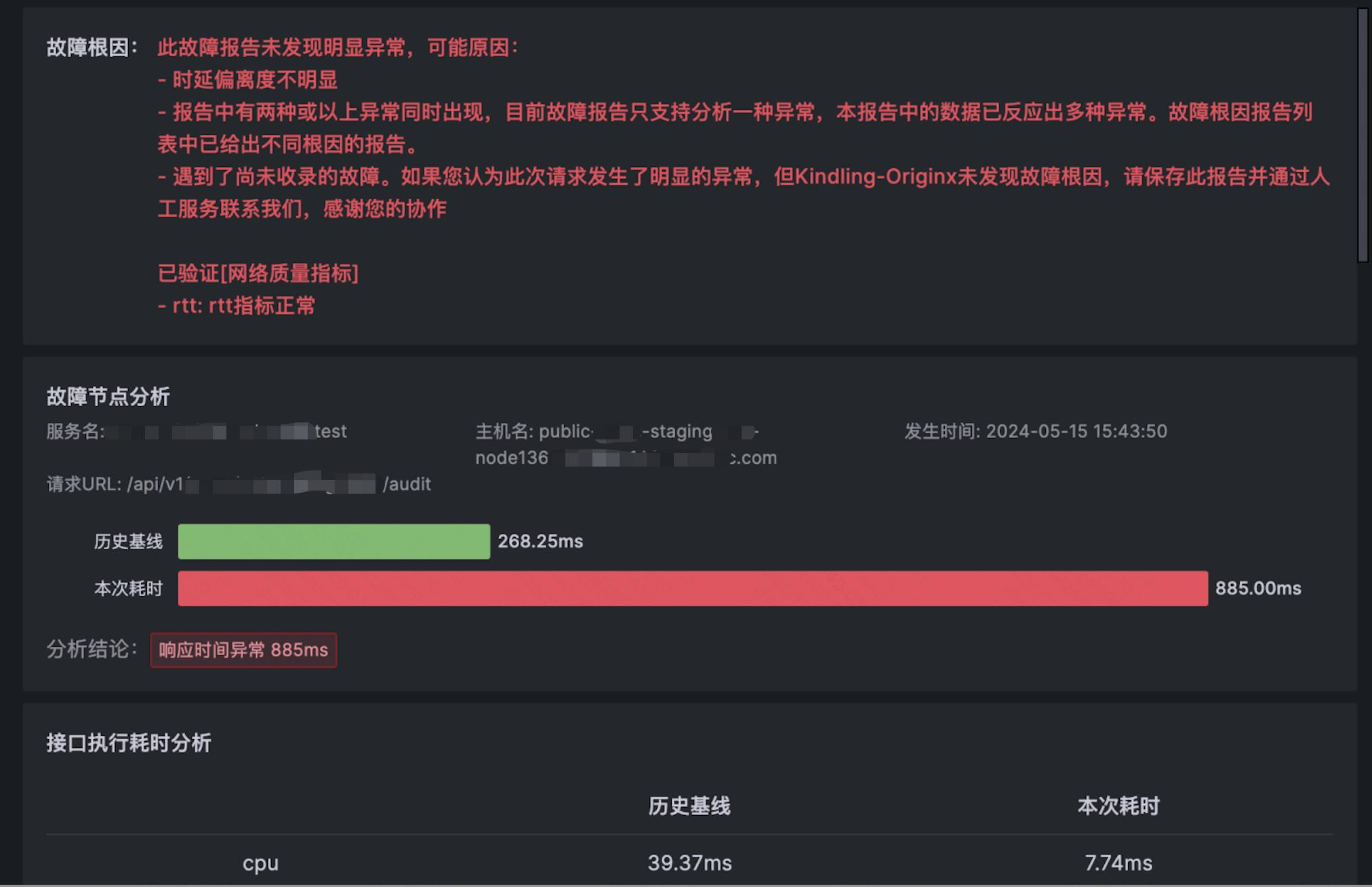
2.故障分为慢故障和故障两大类。对于慢故障,请求调用时长与历史数据相对比,发现其大于 24h 内历史 P90(或 p99,p95) 数据,将其判定为慢故障。假设极端情况,存在故障的实例的请求时延在 24h 内一直都很高,那么后续的请求也会被判断为正常请求,产生漏判。
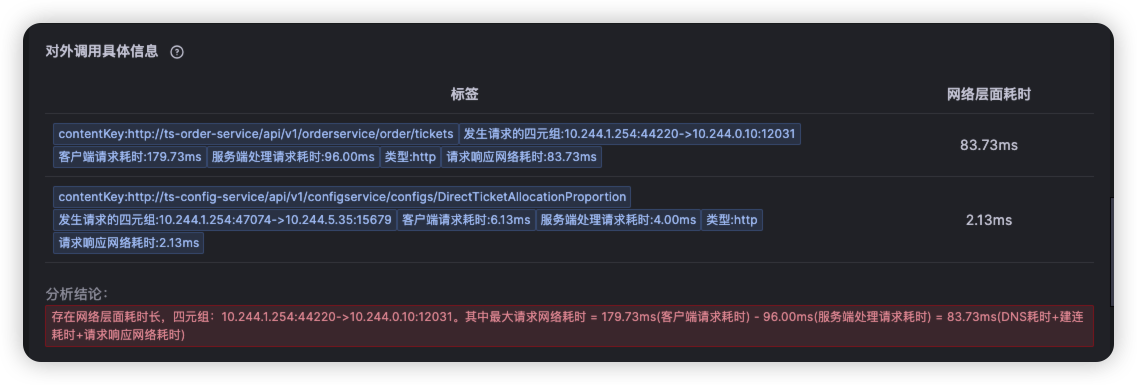
3.下钻诊断能力不足,当前除了对网络故障具备更细粒度的诊断(需接入 DeepFlow,在根因报告中对于对外调用网络耗时长的问题,根 因推导能够回答网络耗时分布的根因,例如是客户端网络问题还是服务端网络问题,是 RTT 问题还是丢包重传问题),其他类型问题 有待关联更多数据提供更多的下转能力。
原理
请求故障评估标准
业务请求时延指标大于 P90(或者 P95,P99 阈值),就会判定为慢请求故障。
线程状态分析方法(TSA)
有别于从资源视角的 USE 方法是从整理上找破绽来缩小异常的范围,给出可能性的方向,TSA 是从主体(线程)角度出发进一步明确线程时间消耗在哪里的方式。
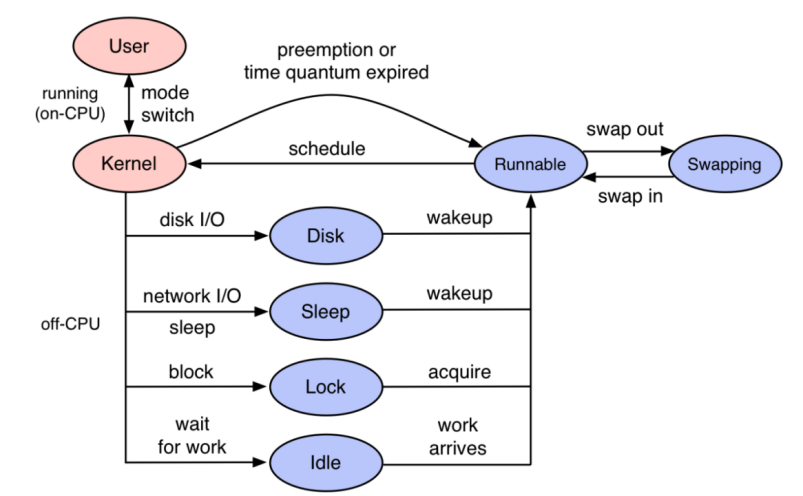
TSA 与 Trace 结合
内核视角缺少业务属性,Trace-Profiling 通过 TSA 的方法论产生的数据与 Trace 打通,做到了与业务关联,这样在生产环境就可以做到某个业务因为什么原因卡住了。
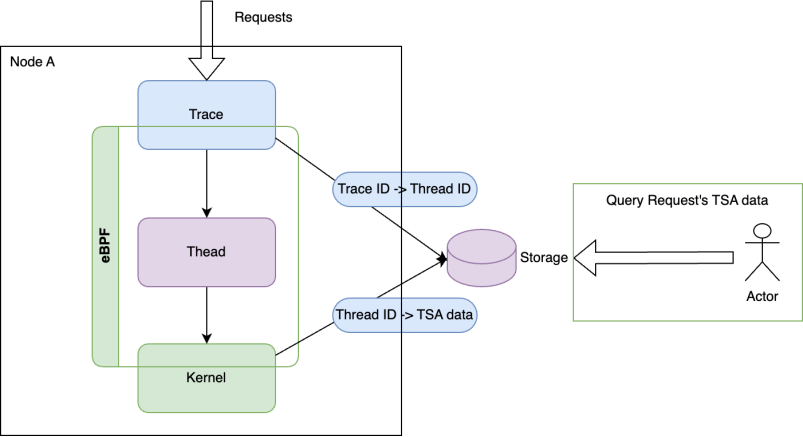
skywalking 会给请求打一个 trace id,利用 ebpf 的能力将 trace 通过 PID 和 TID 底层的 syscall 相关联利用
eBPF 技术能够深入内核,拦截线程执行用户代码的关键点位获取信息,在获得线程执行关键信息之后能够还原线程的执行过程。如 果只从线程维度看程序执行过程是很难分析出故障的,因为开发和运维的谈的故障都是 URL 维度的用户请求调用,所以光有线程维度程序 执行过程是不够的,需要和 Tracing 系统关联。当线程执行过程与 Tracing 系统关联之后,即可完整还原用户一次请求的执行过程。TraceProfiling 中关联了可观测性所需要的数据。
指标说明
Kindling-OriginX 并不直接提供 Trace 能力,而是采用接入 Trace 数据的形式,即通过接入目前成熟的 Trace 产品与提供标准接入 SDK 方 式,例如 Skywalking、OpenTelemetry、ARMS 等,利用 eBPF 能力将 Trace 数据进行扩展,将其与底层的系统调用相关联,进而实现整 的可观测性,消除程序执行与 Trace 数据中的盲区。
用决策树结合 TSA 实现对内核事件的自动化翻译
基于内核事件统计分析,可以形成这样的决策树,最终给出故障的根因。
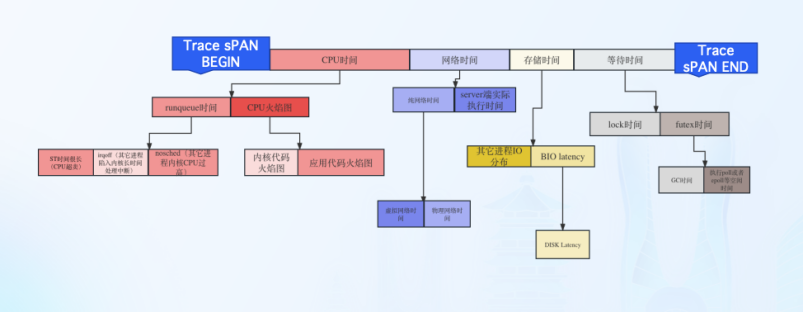
北极星排障指标-CPU 时间程序
在 CPU 资源上所消耗的时间
-
OnCPU
程序代码执行所消耗的 CPU cycles,可以通过程序火焰图确认代码在 CPU 上执行消耗的时间与代码堆栈。
-
Runqueue
线程的状态是 Ready,如果 CPU 资源是充分,线程应该被调度到 CPU 上执行,但是由于各种原因,线程并未调度到 CPU 执行,从而产生的等待时间。
北极星排障指标-网络时间
网络时间属于两次 OnCPU 时间之间的 OffCPU 时间
-
网络时间打标过程
第一次 OnCPU 最后一个系统调用执行为 sock write 与第二次 OnCPU 第一个系统调用为 sock read,也可以理解为网络包出网卡至网络包从网卡收回的时间。
-
网络时间分类
DNS,TCP 建连,常规网络调用。
北极星排障指标-存储时间
属于两次 OnCPU 时间之间的 OffCPU 时间
-
存储时间打标过程
第一次 OnCPU 最后一个系统调用执行为 VFS read/write 与第二次 OnCPU 第一个系统调用为 VFS read/wirte。
-
存储时间真实情况
存储真实执行情况,由于内核的 pagecache 存在,所以绝大多数 VFS read/write 从程序视 角看:执行时间不超过 1 毫秒。
北极星排障指标-等待时间
-
futex
通常指的是一个线程在尝试获取一个 futex 锁时因为锁已经被其他线程占用而进入等待状态的时间。在这段时间内,线程不会执行任何操 作,它会被内核挂起。
-
mutex_lock
线程在尝试获取互斥锁时,因为锁已经被其他线程持有而进入等待状态的时间长度。这段时间对于程序的性能至关重要,因为在等待期 间,线程不能执行任何有用的工作。
实际使用效果
历史稳定性分布问题
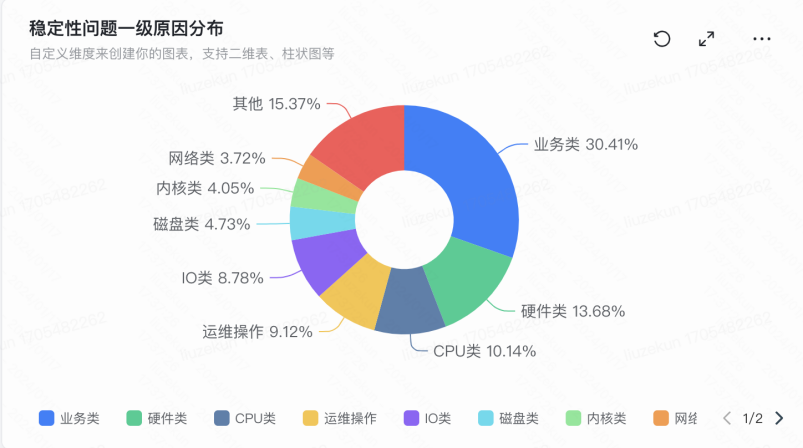
效果汇总
| 故障类型 | 故障案例 | 人工时长 | 使用Oirignx预计定界时长 | 召回率 | 准确率 |
|---|---|---|---|---|---|
| OnCPU(CPU执行)时间过长 | 代码缺陷,直播服务故障 | 16min(5+位领域专业同学投入) | 10min | 80% | 80% |
| 极高的中断负载 | 4h | 10min | 90% | 80% | |
| 等待调度到CPU时间过长 | 宿主机CPU负载过高 | 1h | 5min | 90% | 70% |
| 读写文件耗时长(IO) | P2P拉镜像卡死 | 2天(需基础平台多位高级同学参与分析,链路长) | 8min | 90% | 70% |
| 高磁盘读取负载 | 1h | 5min | 90% | 60% | |
| 请求下游节点耗时长(网络调用耗时长) | 网卡时延过长(网卡上tc注入时延) | 4h | 5min | 90% | 80% |
| epoll耗时异常 | 4h | 5min | 90% | 70% | |
| 调用中间件耗时长 | 4h | 5min | 80% | 70% | |
| 锁等待或GC | 内核osq_lock锁竞争问题 | 1周(基础平台累计10+位领域专业同学投入,蹲守凌晨业务高峰得以查明) | 10min | 80% | 80% |
| 服务异常(内核死锁问题) | 1周(基础平台累计10+位领域专业同学投入) | 10min | 80% | 80% | |
| Java锁耗时长 | 4h | 5min | 80% | 90% | |
| 内存问题 | 虚拟内存压力 | 1h | 5min | 70% | 70% |
| 用户页错误 | 3h | 5min | 80% | 80% |

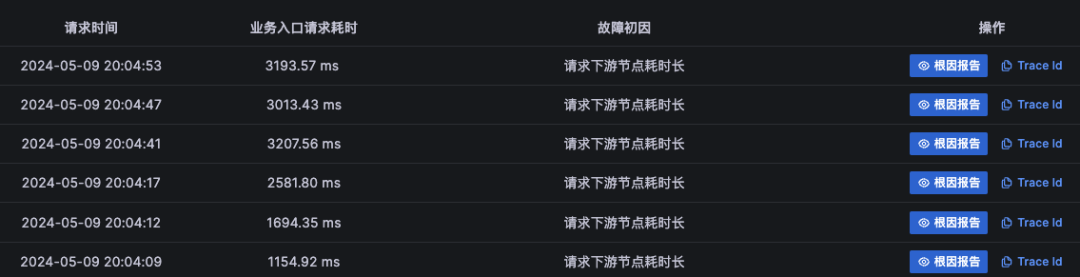

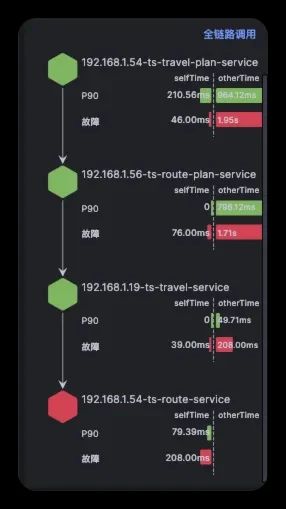

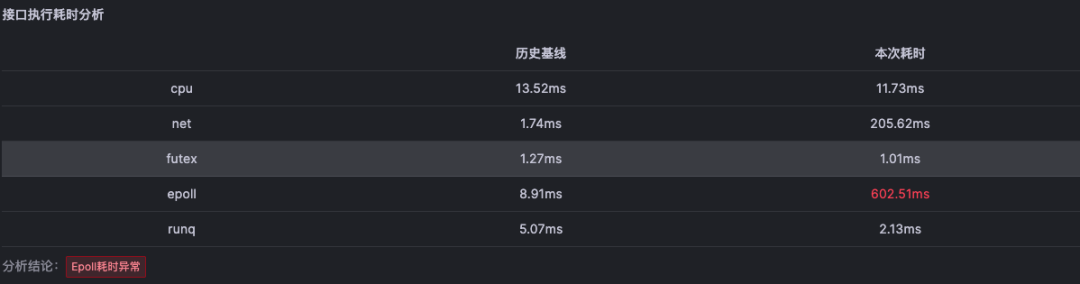


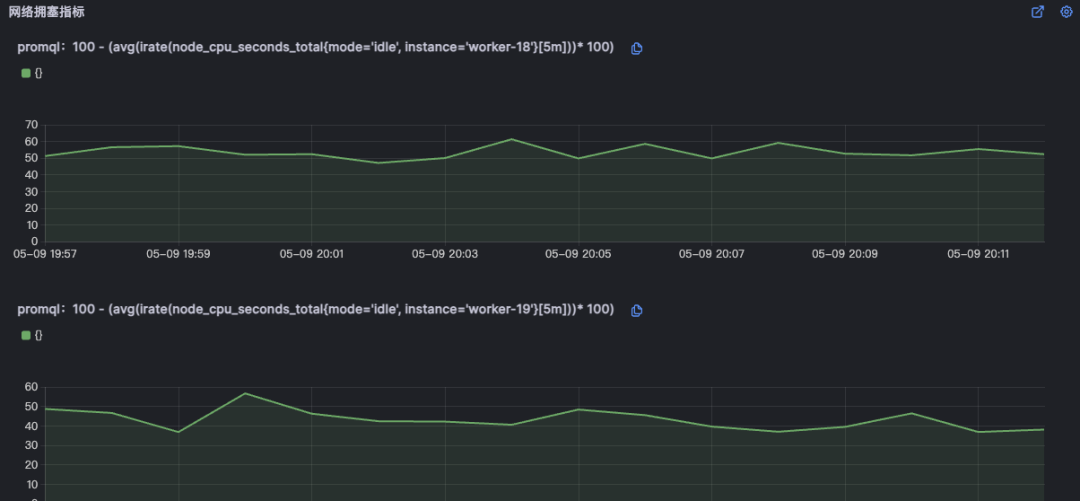

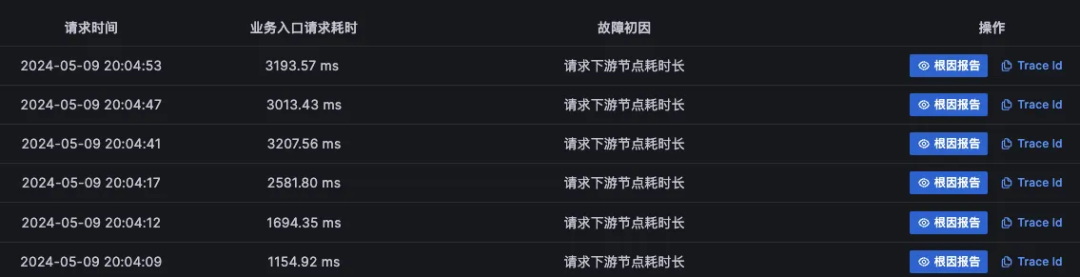


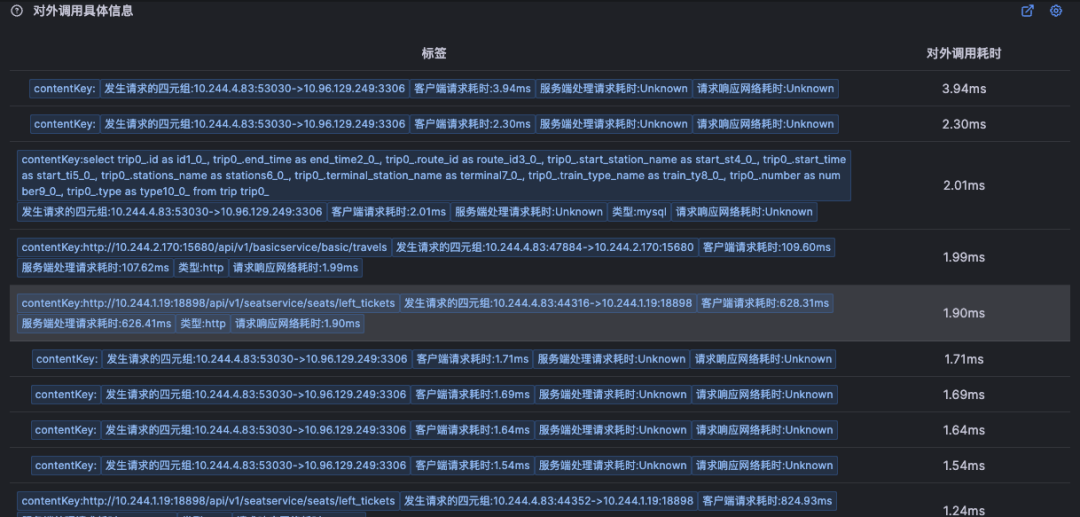

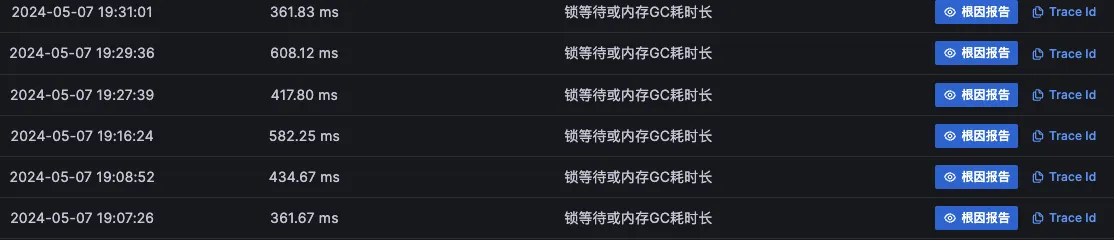



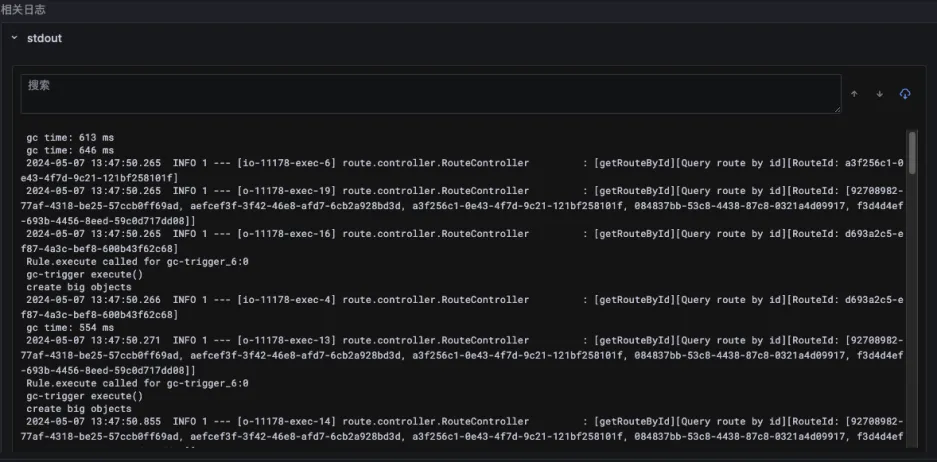


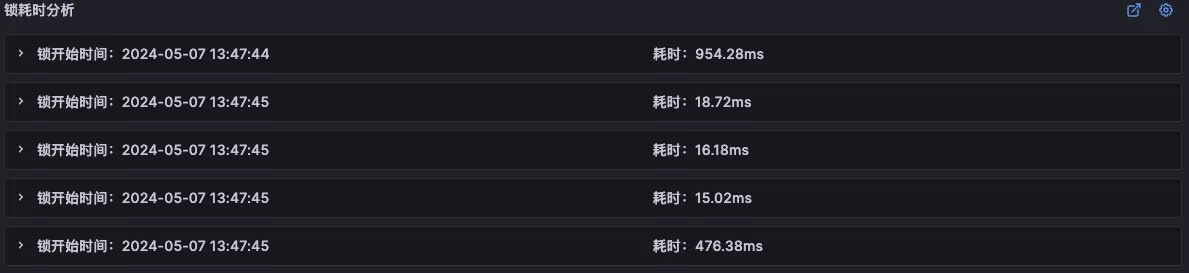
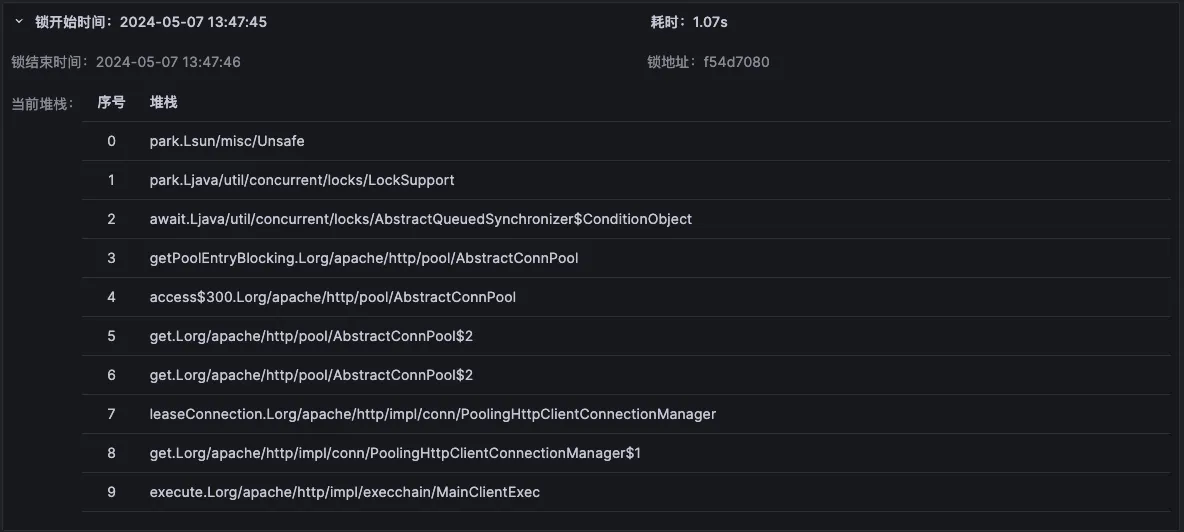
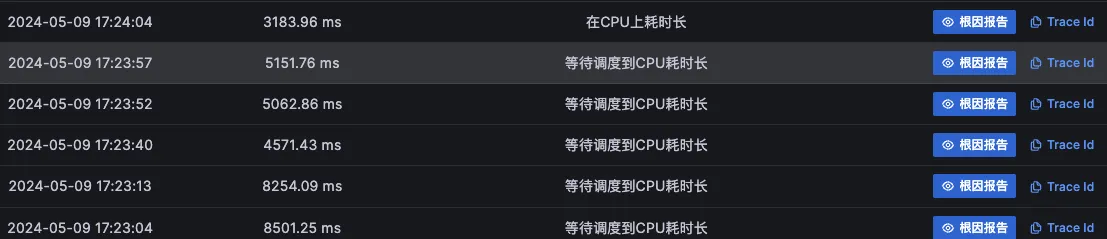



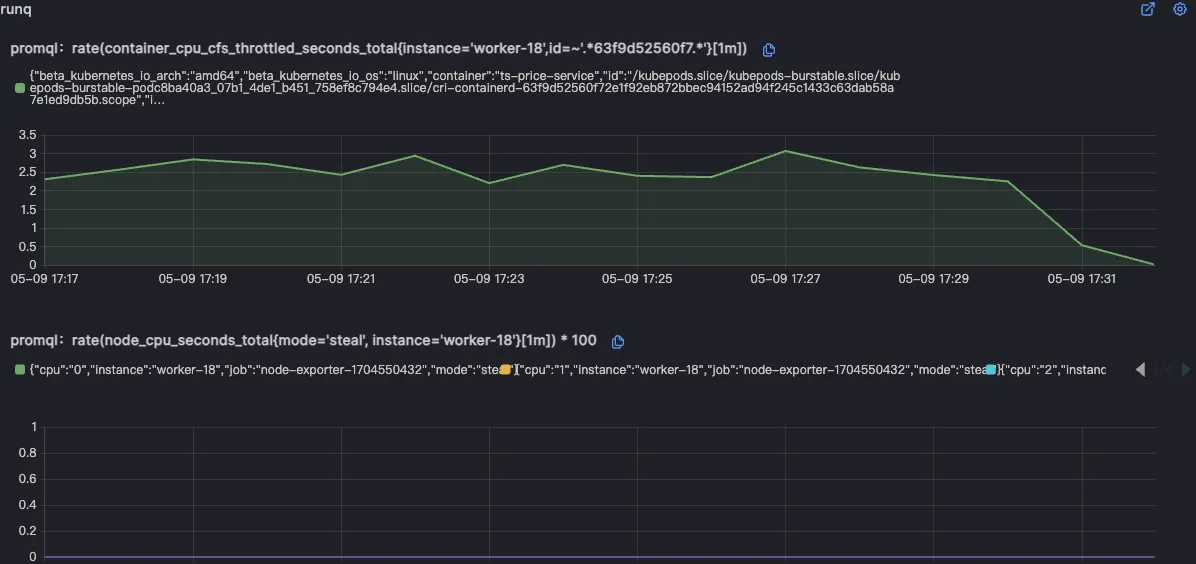
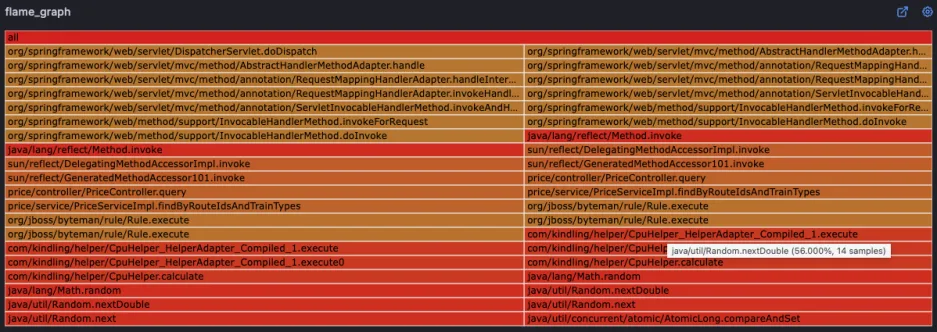


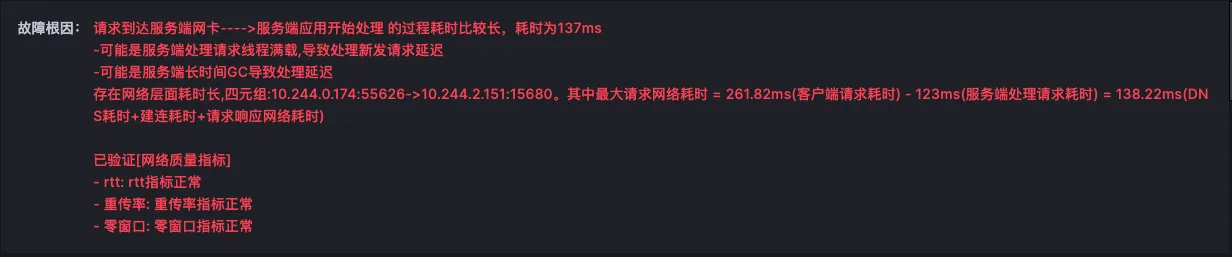



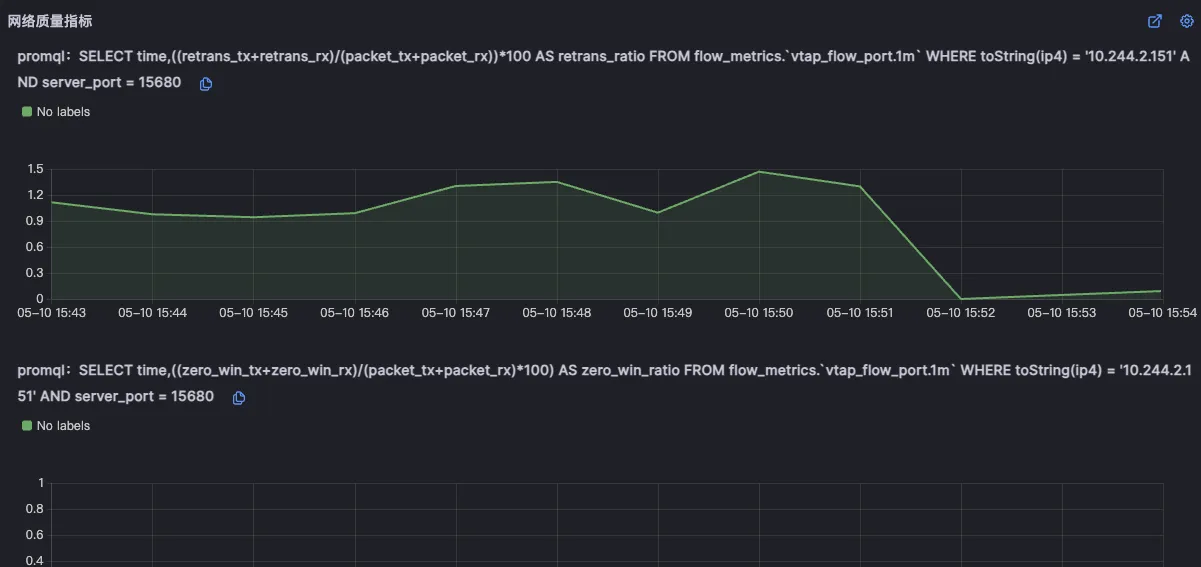



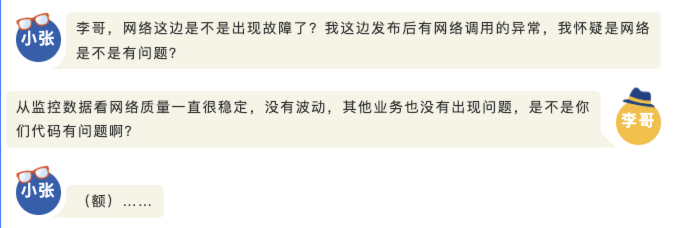



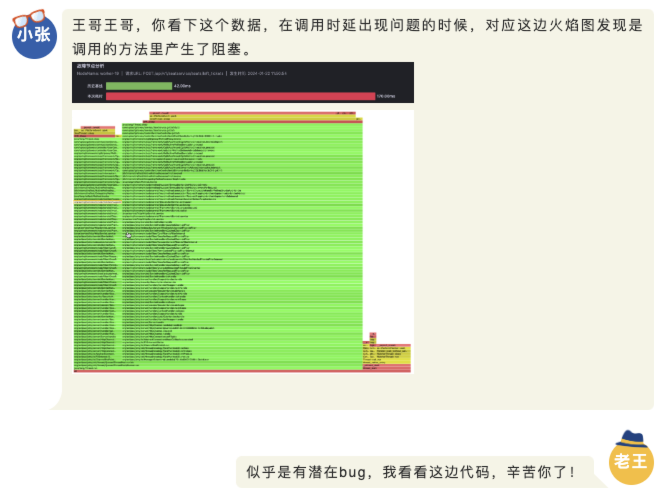
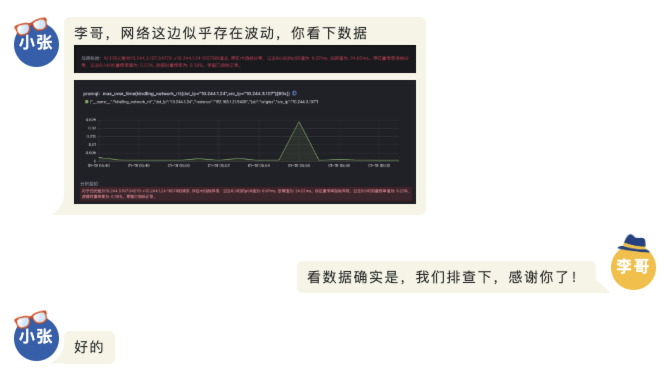
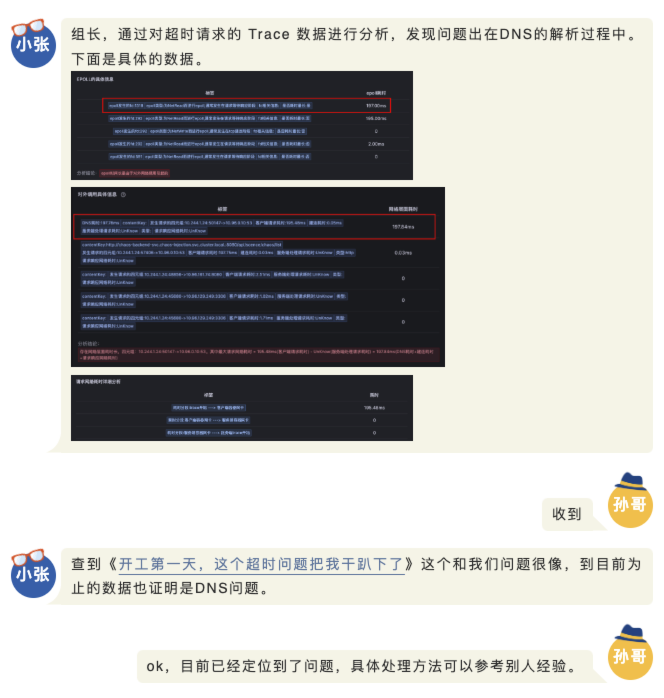 对于难以明确排查方向,无法定界的故障,Kindling-OriginX 快速组织和分析故障线索,通过自动化 Tracing 关联分析,以给出可解释的根因报告的方式,为这类故障提供可操作的排查方法。
对于难以明确排查方向,无法定界的故障,Kindling-OriginX 快速组织和分析故障线索,通过自动化 Tracing 关联分析,以给出可解释的根因报告的方式,为这类故障提供可操作的排查方法。


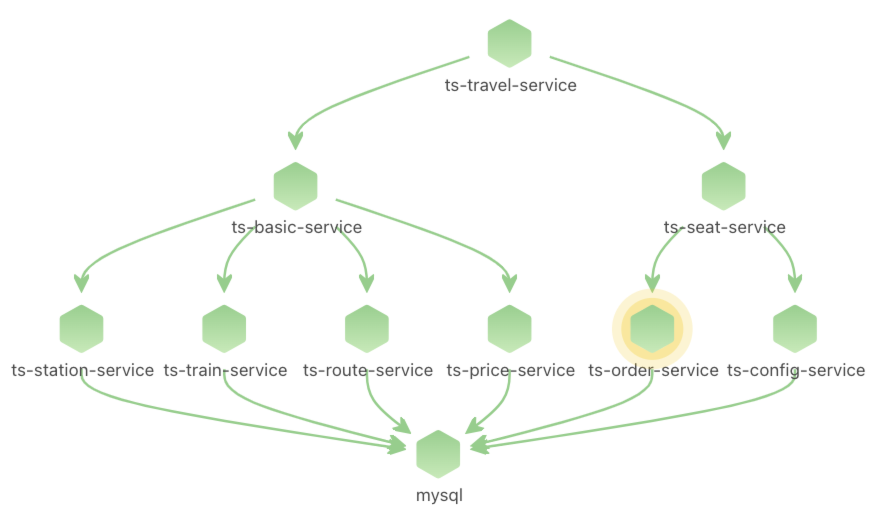
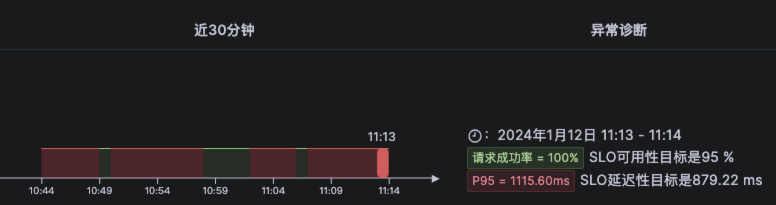
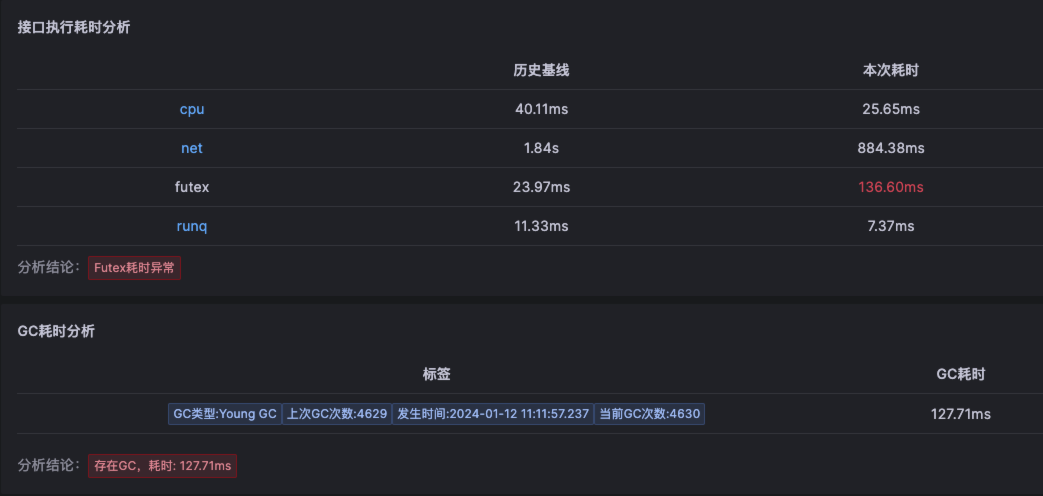
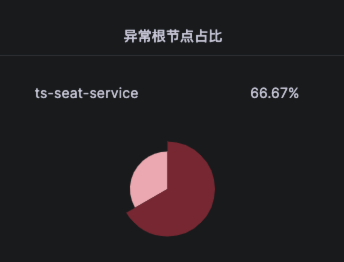

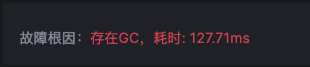

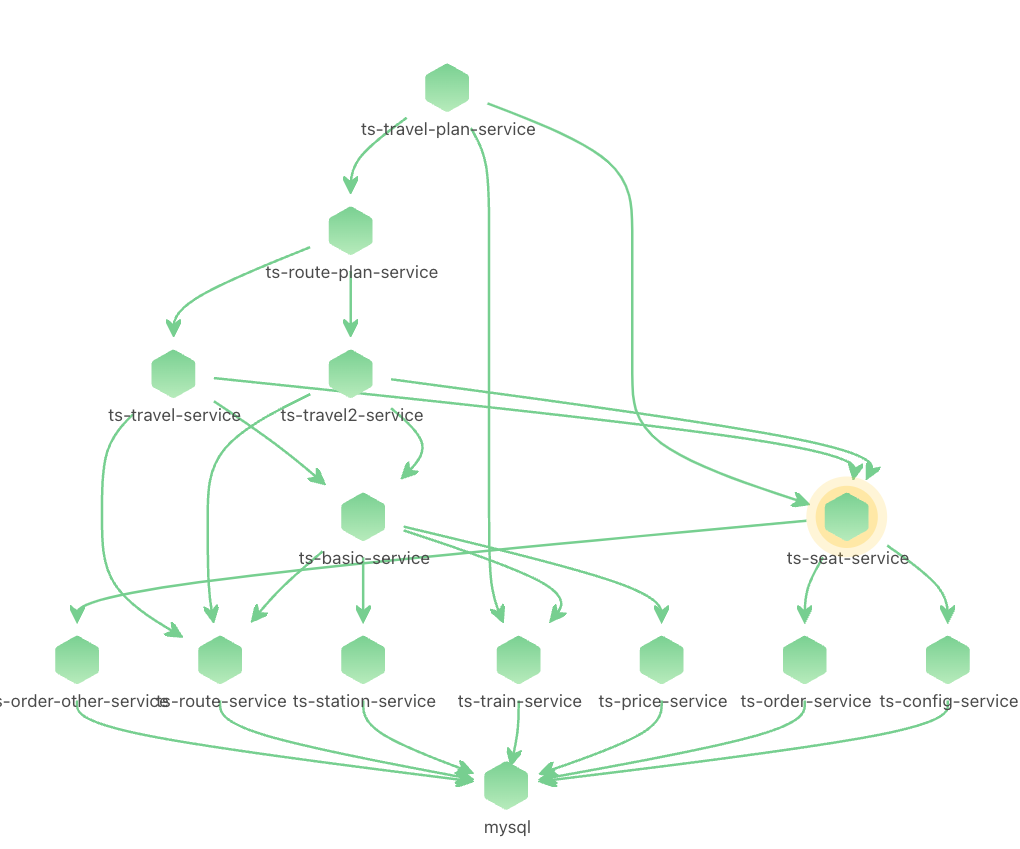
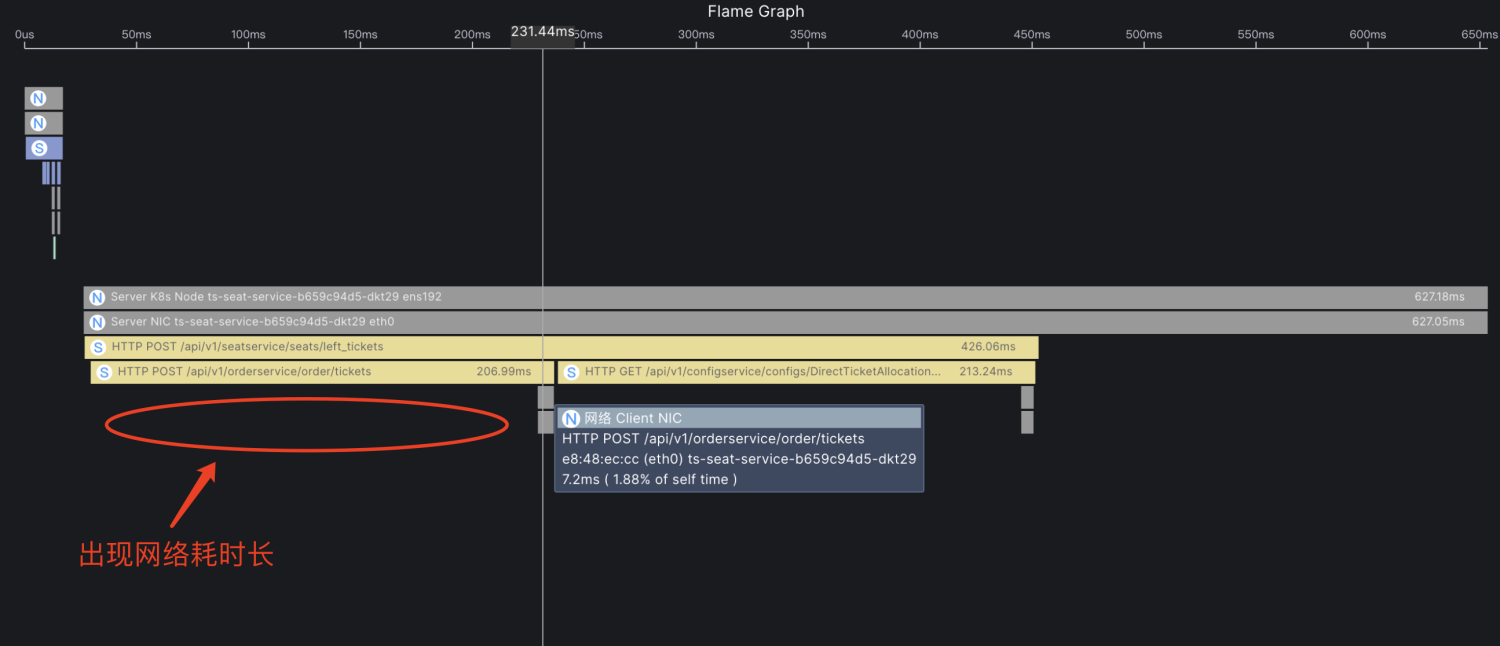
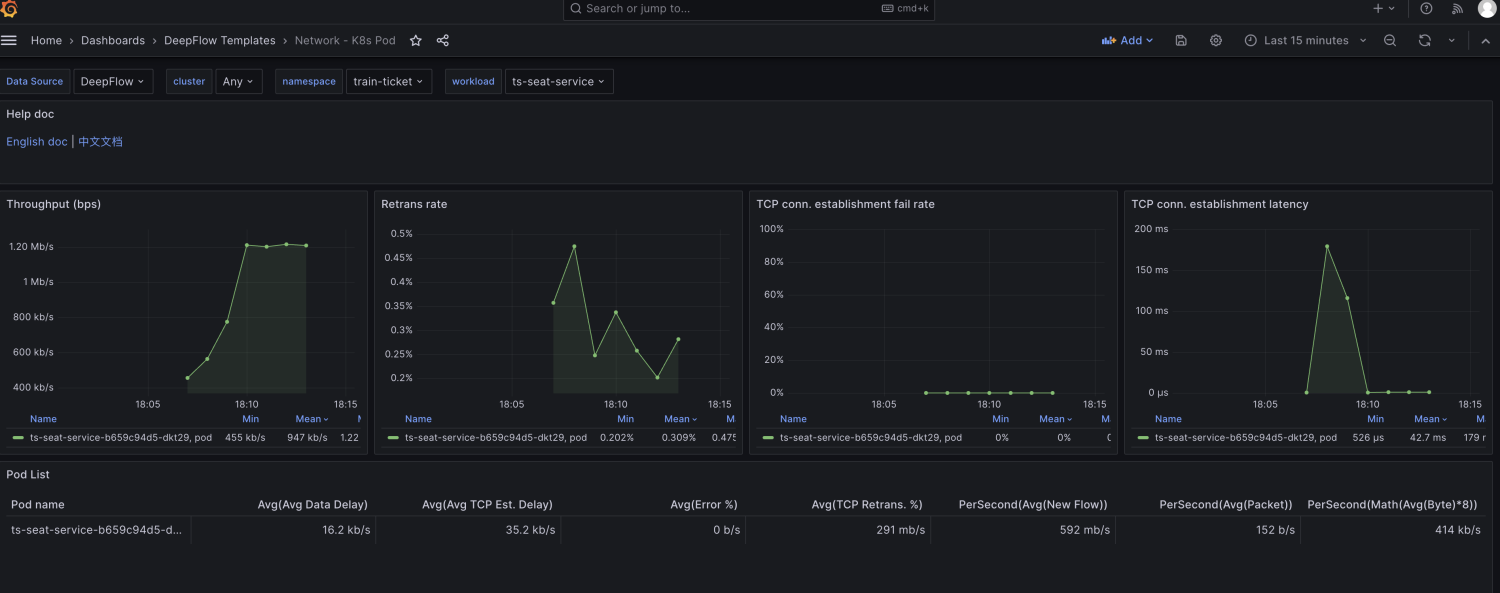
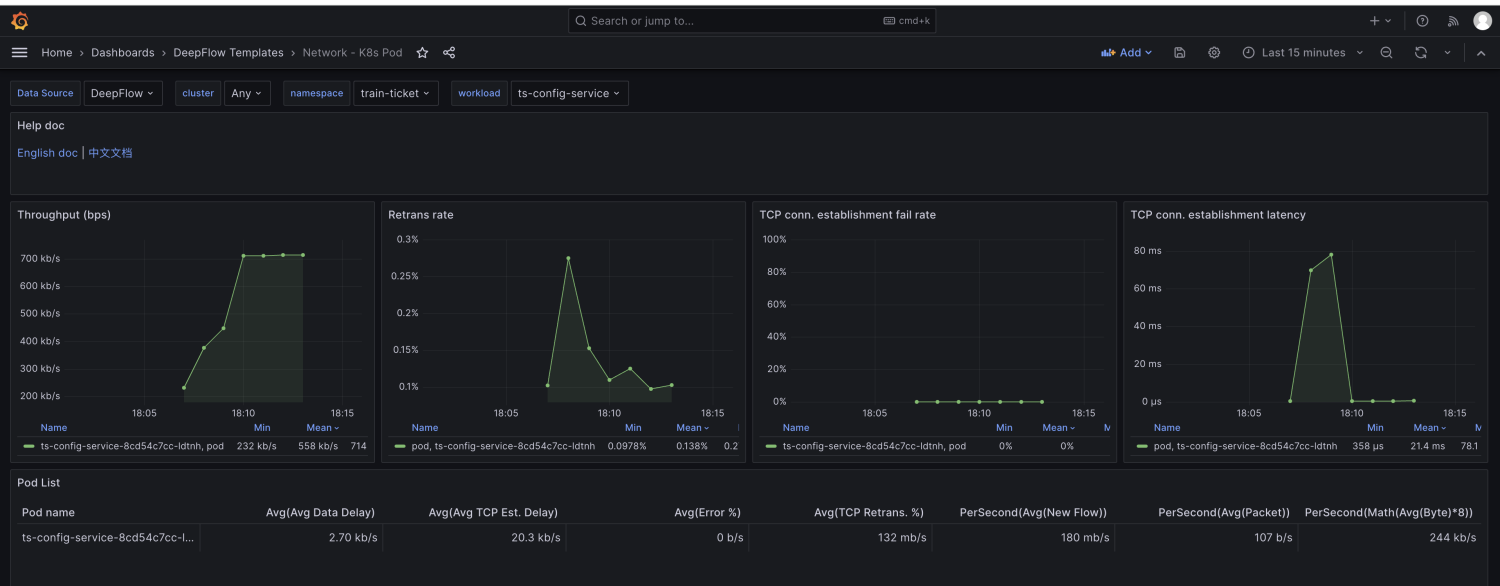

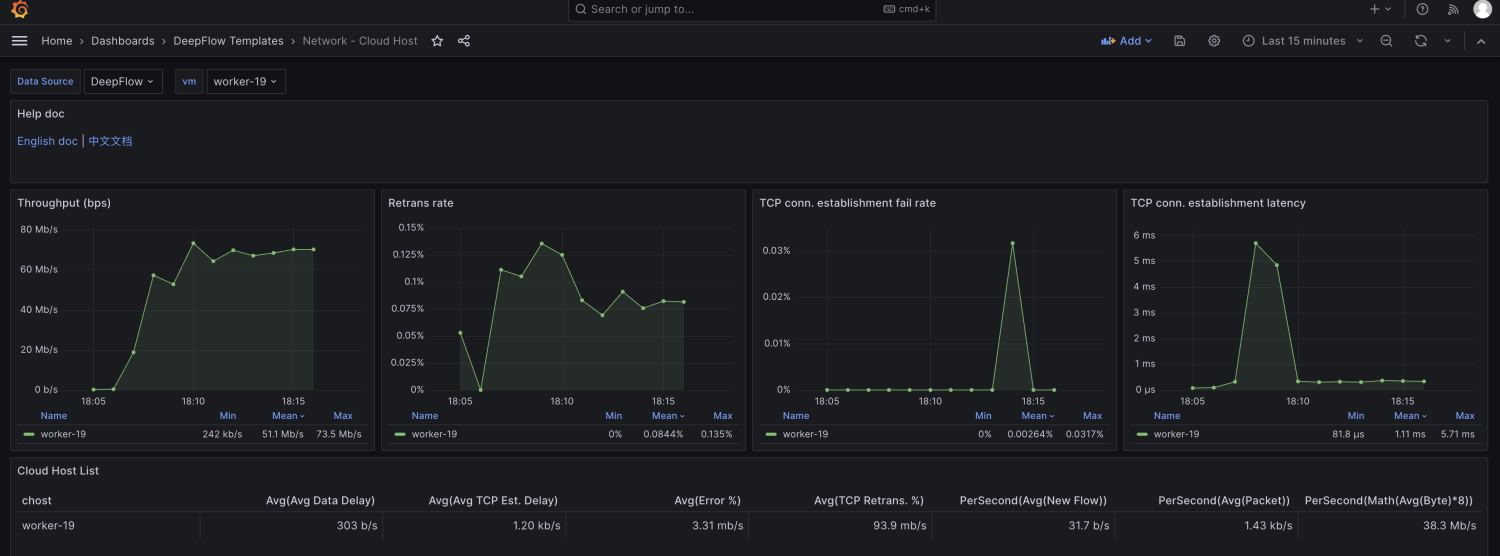
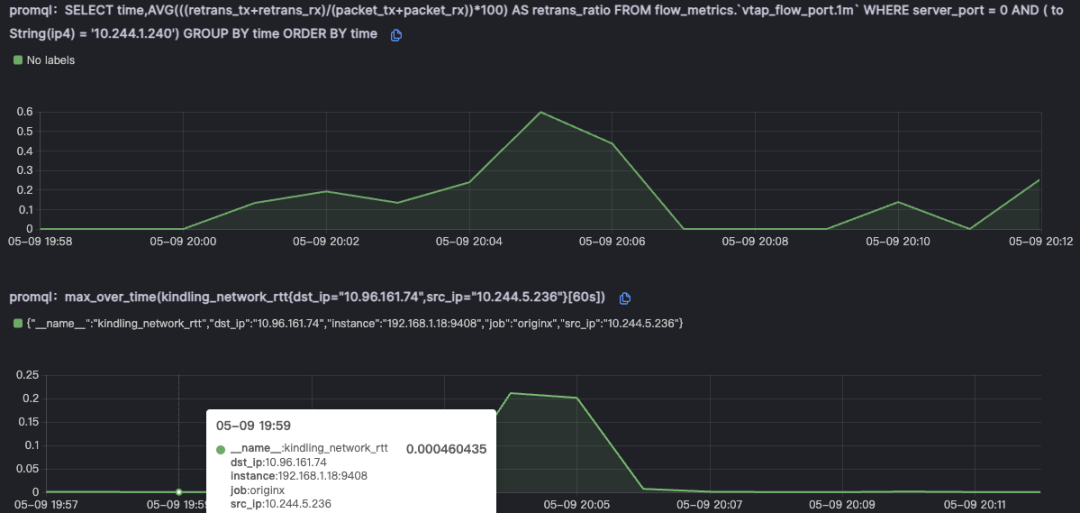
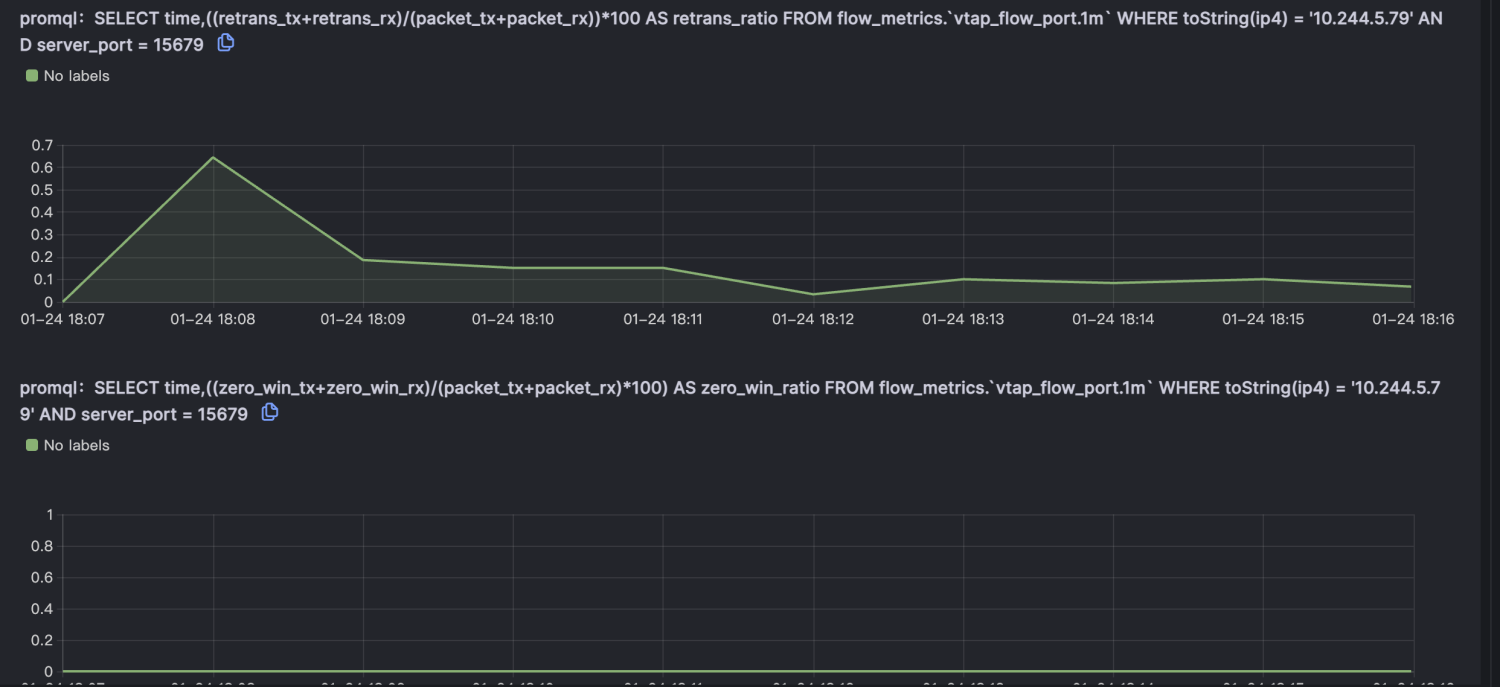
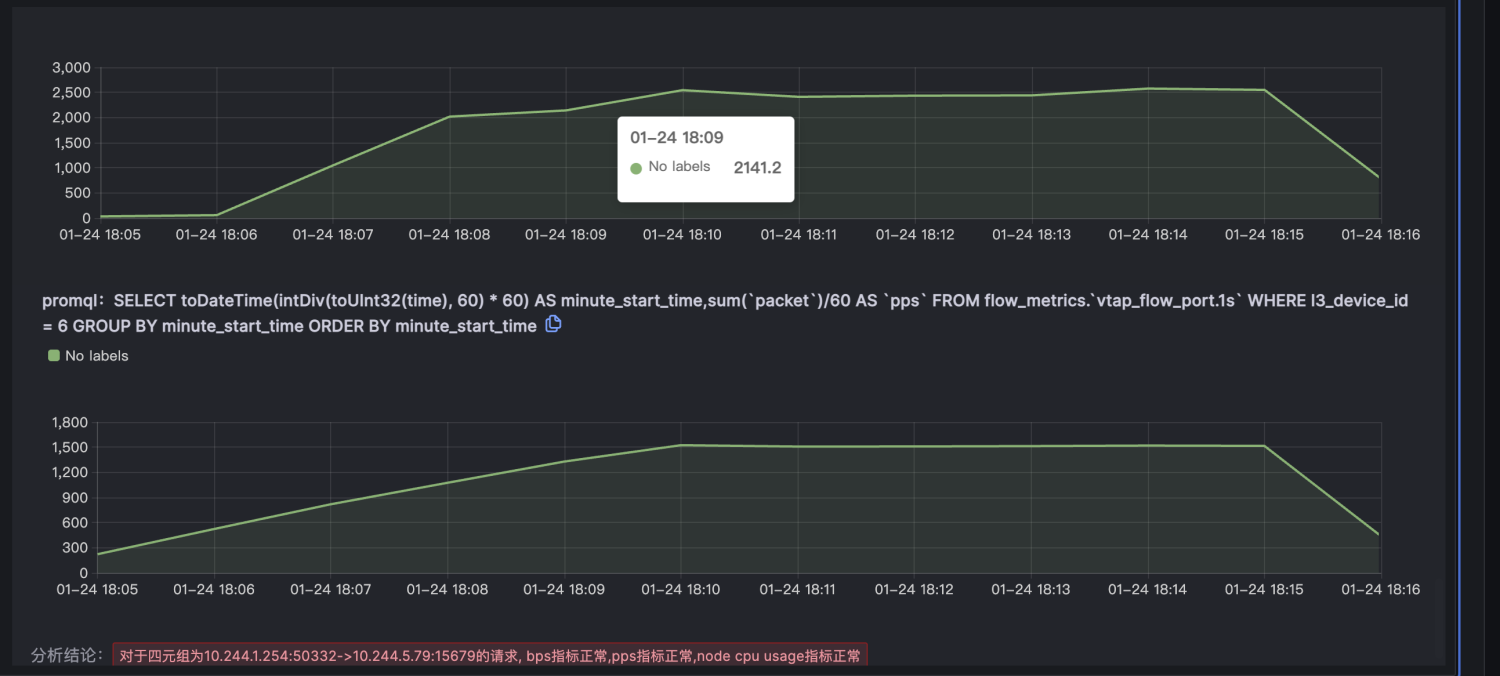
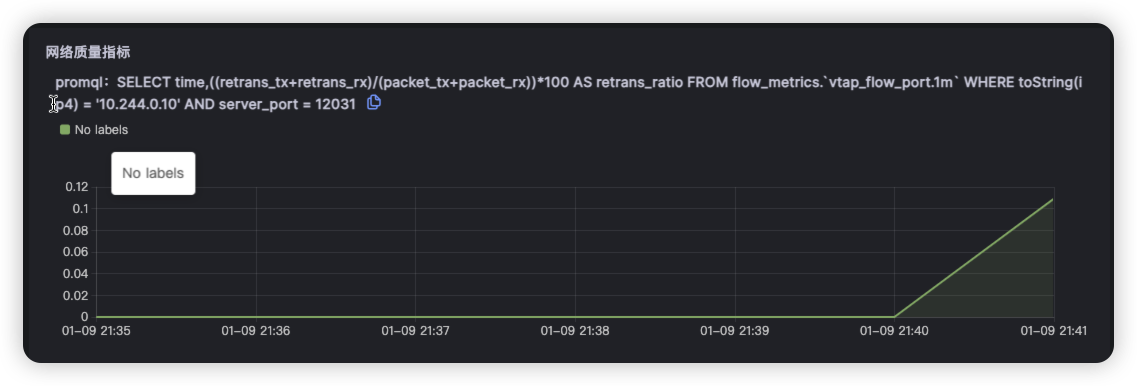
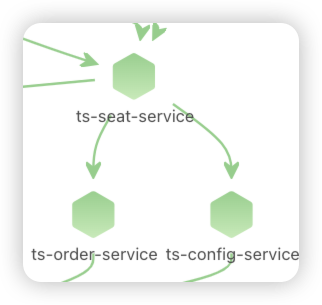
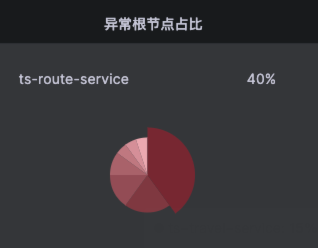
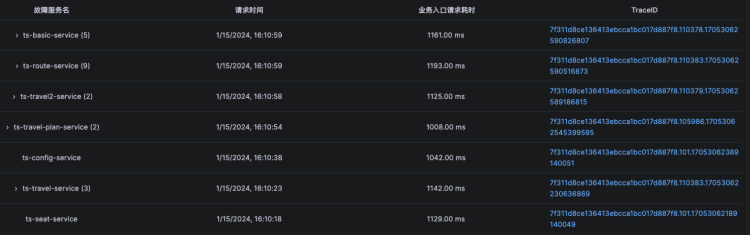
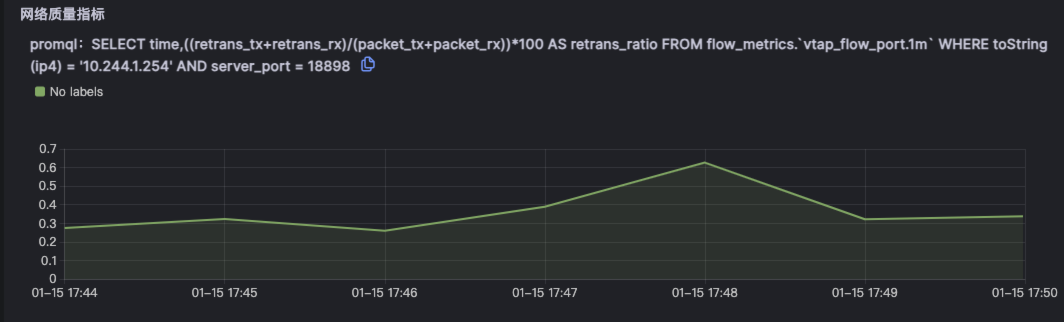
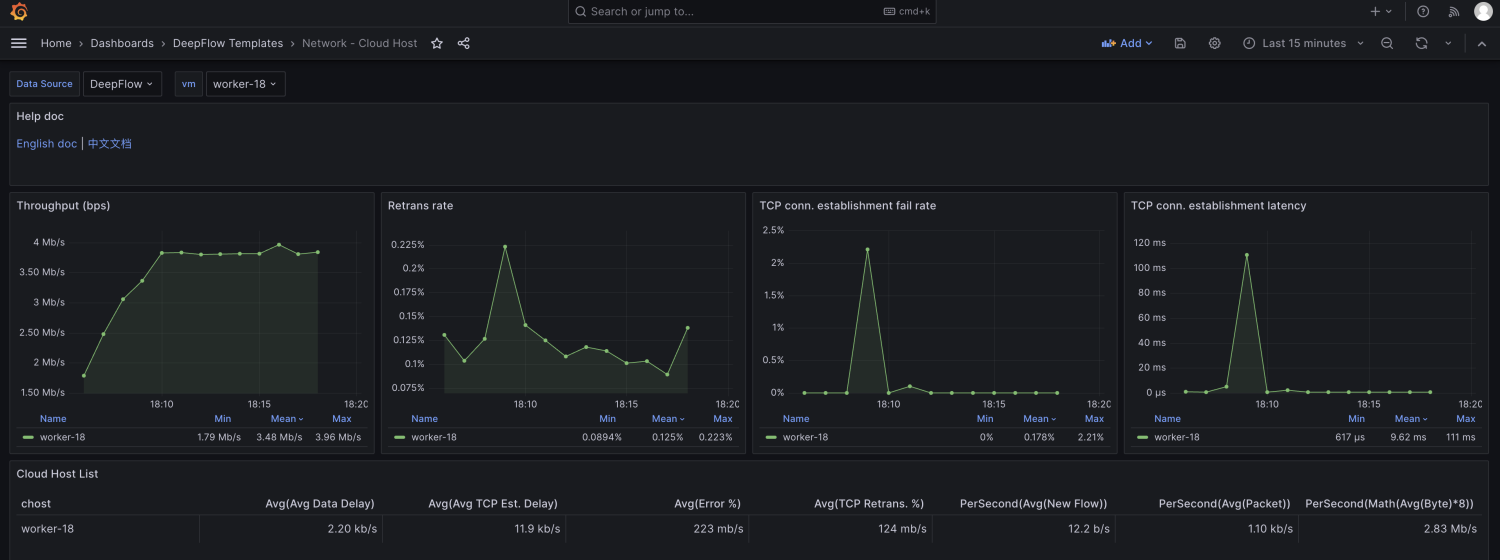 由于node级别的网络指标没有出现明显异常,最终确定是seat-service的pod级别rtt指标异常。
由于node级别的网络指标没有出现明显异常,最终确定是seat-service的pod级别rtt指标异常。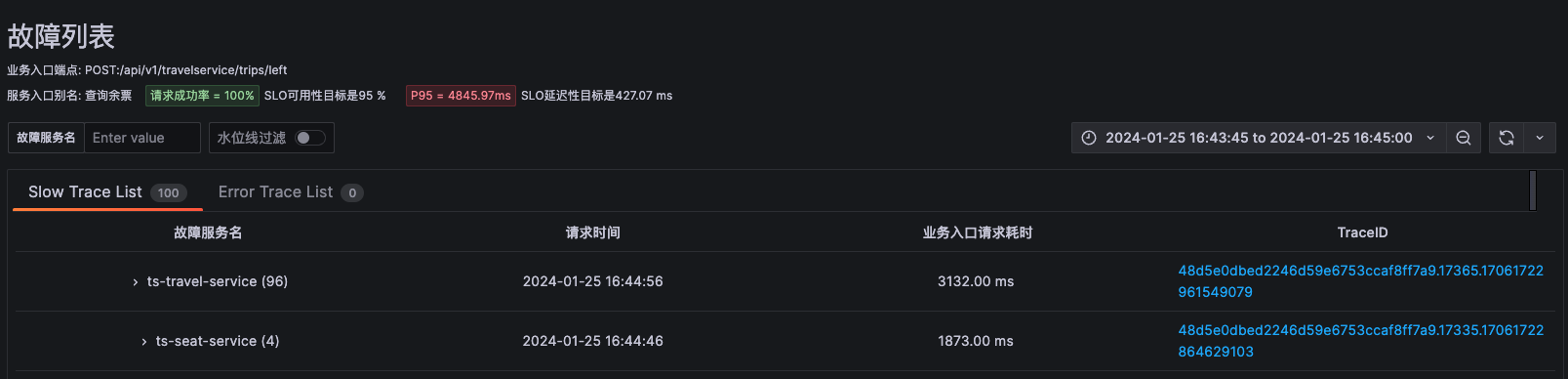


 Kindling-OriginX 将整个故障推理都在一页报告中完成,并且每个数据来源都是可信可查的。
Kindling-OriginX 将整个故障推理都在一页报告中完成,并且每个数据来源都是可信可查的。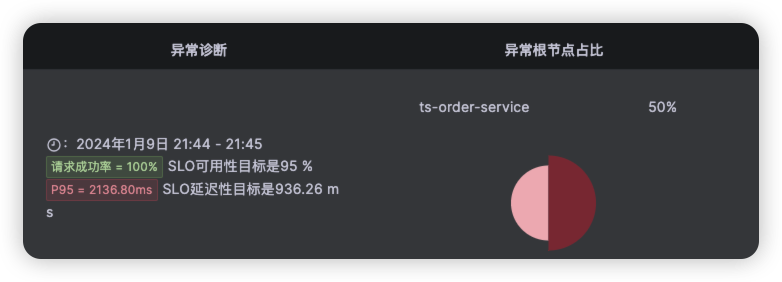
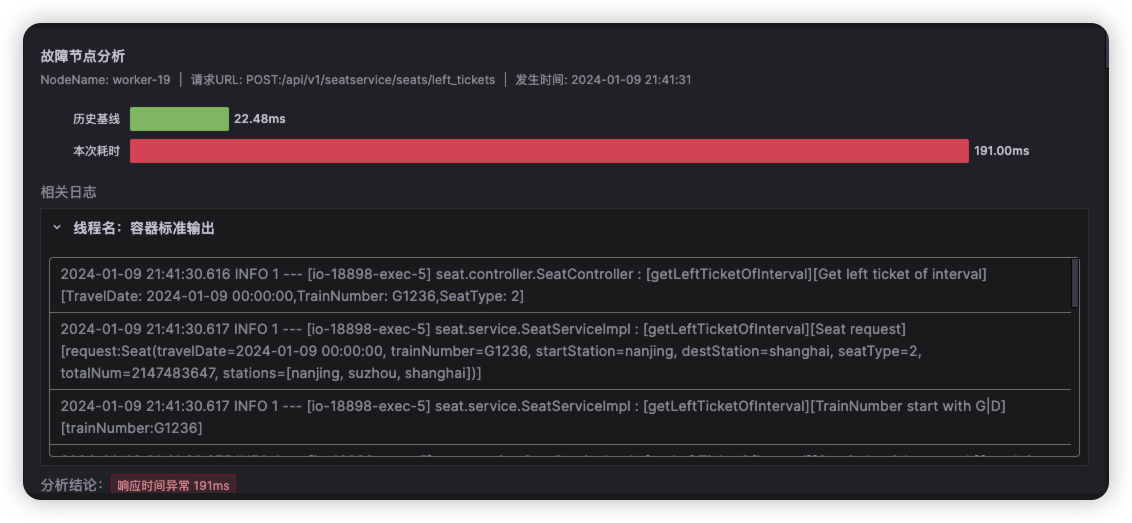
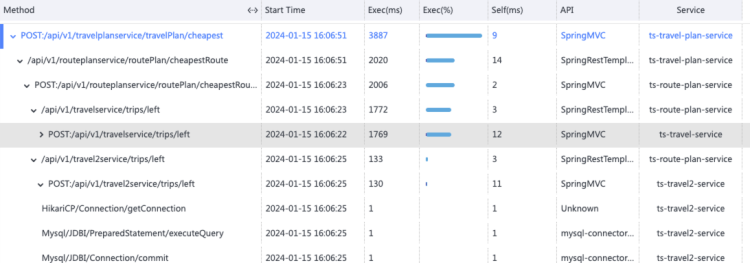
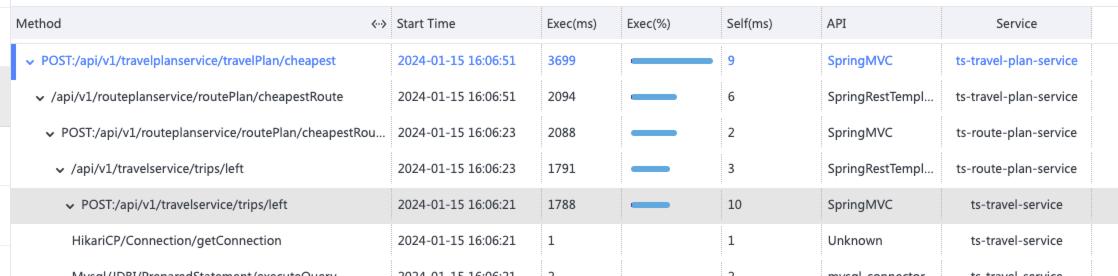
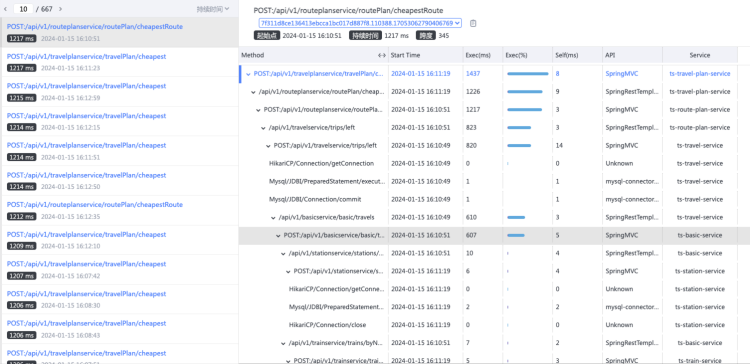
 点击ts-seat-service的TraceID后进入该节点最新的故障报告。一份故障根因诊断报告有部分内容及多种相关Log、Trace�、Metrics数据聚合分析而成,这里分别简单介绍。
点击ts-seat-service的TraceID后进入该节点最新的故障报告。一份故障根因诊断报告有部分内容及多种相关Log、Trace�、Metrics数据聚合分析而成,这里分别简单介绍。













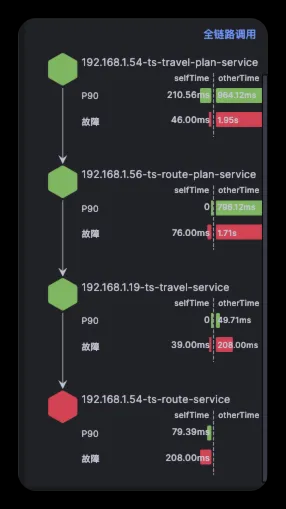
 Kindling-OriginX 提供了一种新的处理级联故障的思路和方法,快速组织和分析故障线索,给出根因报告,并根据优先级原则进行故障处理。这种方法可以加速故障定位,避免级联故障中排查方向错误,同时能够以标准化的流程进行级联故障的排查,真正的有机会去在实践中落地 1-5-10 故障响应机制。
Kindling-OriginX 提供了一种新的处理级联故障的思路和方法,快速组织和分析故障线索,给出根因报告,并根据优先级原则进行故障处理。这种方法可以加速故障定位,避免级联故障中排查方向错误,同时能够以标准化的流程进行级联故障的排查,真正的有机会去在实践中落地 1-5-10 故障响应机制。