Kindling-OriginX工作原理
传统可观测性产品在落地过程中的局限��性
很多公司已经落地了 Tracing、Metrics、Logging,但是在实际使用中效果不如预期主要由以下几个原因:
- Tracing、Metrics、Logging 数据之间归属于不同产品,排查问题之时需要再不同产品之间跳转,对于问题排查效率影响较大。
- Tracing、Metrics 对于开发和运维而言不熟悉,不会使用,对指标代表的技术含义理解不深入,最终排障都是依赖于专家牛人的个人经验。可观测性系统推广之后,业务团队使用起来效果差强人意。
- 专家排障的时候也受限于已有经验,缺乏标准化流程,在不断猜测验证过程中,容易丢失掉 1-5-10 的目标。
- 耗费人力和物力资源建设了一系列的可观测性项目,但是最终仍然很难落地1分钟识别故障、5分钟识别故障初因、10分钟回复业务。
什么是 Trace
分布式链路追踪(Distributed Tracing,简称Trace)又名全链路数据追踪,为业务系统提供了整个服务调用链路的调用关系、延迟、结果等信息。相比访问日志这种记录顺时请求结果的数据,Trace则把内部的各种请求连接起来,组成一个服务调用的关系图。用户请求的处理过程会形成一条 Trace。Trace ID 作为 Trace 数据的唯一标识,在面对海量请求的时候,需要保证其唯一性。当前市面上有很多优秀成熟的 Trace 产品,例如 Skywalking 等。
Kindling-OriginX 并不直接提供 Trace 能力,而是采用接入 Trace 数据的形式,即通过接入目前成熟的 Trace 产品与提供标准接入SDK方式,例如Skywalking、OpenTelemetry、ARMS等,利用 eBPF 能力将 Trace 数据进行扩展,将其与底层的系统调用相关联,进而实现完整的、彻底的可观测性,消除程序执行与 Trace 数据中的盲区。
什么是 eBPF 技术
eBPF(extended Berkeley Packet Filter)是一种先进的系统内核技术,最初源自于 Berkeley Packet Filter(BPF)。它是一种在 Linux 内核中执行高度优化的程序的框架,允许用户编写并插入小型程序(称为 eBPF 程序)来对系统内核的行为进行扩展和控制。 eBPF 允许用户在不更改内核源代码或重新编译的情况下,通过加载在内核中运行的小型程序来扩展内核功能。这些程序可以捕获和分析系统运行时的事件、执行网络分析、实现安全策略、执行性能调优等操作。 eBPF 的一些关键特性和优势包括:
- 安全性:eBPF 程序在一个受限的虚拟机中运行,不会影响系统稳定性和安全性。
- 灵活性:可以动态加载、卸载和更新eBPF程序,无需重新启动系统。
- 性能:eBPF 程序经过优化,能够在内核中高效执行。
- 可观察性:能够捕获和分析系统运行时的各种事件,有助于故障排除和性能分析。
eBPF 技术在多个领域得到应用,包括网络编程(例如网络包过滤、路由)、性能分析、安全监控、容器技术等。它已经成为许多现代系统中实现高级功能和控制的重要工具之一。
目前业内已有许多基于 eBPF 的可观测性项目,例如 DeepFlow,其基于 eBPF 采集精细的链路追踪数据和网络基础数据。当 Kindling-OriginX 识别出网络侧出现问题时,就会关联 DeepFlow 的网络侧数据进行数据下钻。Kindling-OriginX 自身关注在通过 eBPF 能力将业务层的 Trace 数据与底层的系统调用关联起来,消除程序执行的盲区。
什么是 TraceProfiling 技术
用户开发的代码都是以线程形式运行在操作系统之上,即便Go语言有协程的概念,go协程在执行过程中仍然绑定在操作系统内核线程上执行。操作系统内核线程的完整运行周期如下图所示。
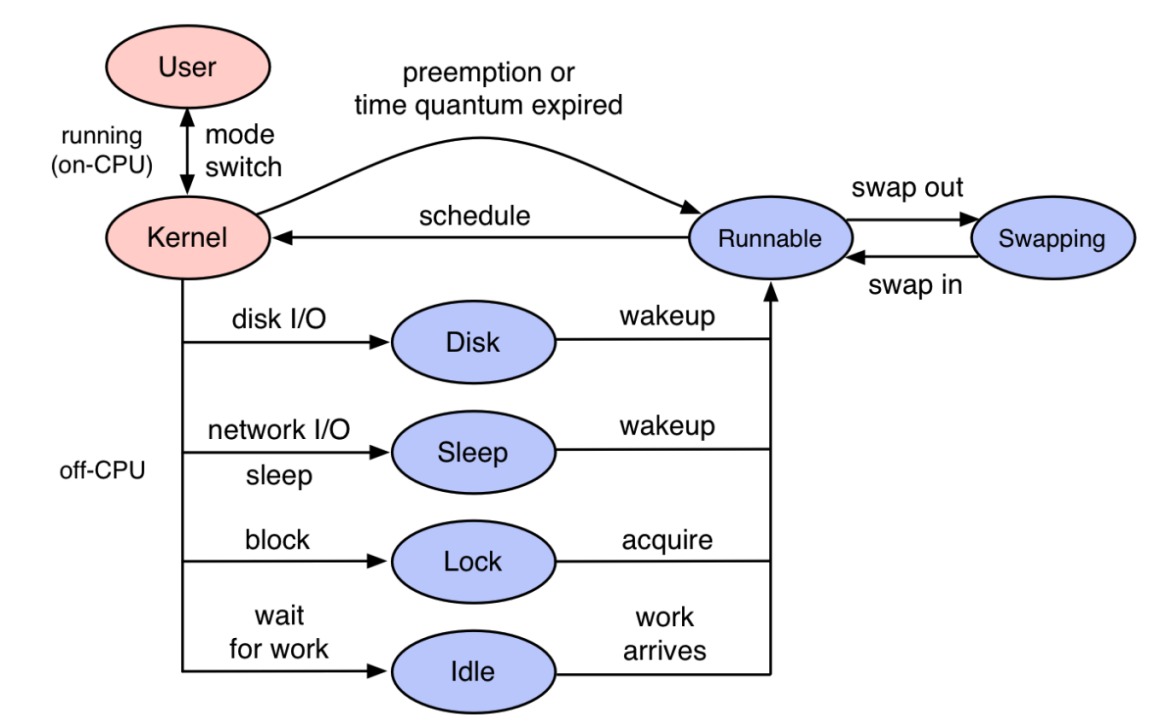
利用 eBPF 技术能够深入内核,拦截线程执行用户代码的关键点位获取信息,在获得线程执行关键信息之后能够还原线程的执行过程。 如果只从线程维度看程序执行过程是很难分析出故障的,因为开发和运维的谈的故障都是URL维度的用户请求调用,所以光有线程维度程序执行过程是不够的,需要和 Tracing 系统关联。 当线程执行过程与 Tracing 系统关联之后,即可完整还原用户一次请求的执行过程。 TraceProfiling中关联了可观测性所需要的数据:
- 指标
- 日志
北极星排障指标体系(龙蜥社区与 Kindling 社区联合发布了北极星排障指标体系)
通过分析 TraceProfiling 数据,能够得到一次请求在Span中执行具体花了多少时间在CPU、网络、存储、等待。将 TraceProfiling 数据进行聚合可以得到北极星排障指标体系,从而指导标准化的排障过程。
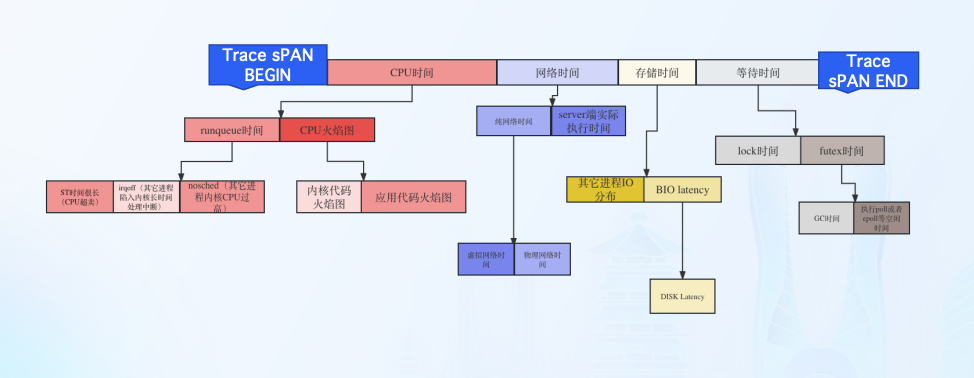
指标说明
北极星排障指标-CPU时间
程序在CPU资源上所消耗的时间
- OnCPU
程序代码执行所消耗的CPU cycles,可以通过程序火焰图确认代码在 CPU上执行消耗的时间与代码堆栈.
- Runqueue
线程的状态是Ready,如果CPU资源是充分,线程应该被调度到 CPU上执行,但是由于各种原因,线程并未调度到CPU执行,从而产生的等待 时间。
北极星排障指标-网络时间
网络时间属于两次OnCPU时间��之间的OffCPU时间
- 网络时间打标过程
第一次OnCPU最后一个系统调用执行为sock write与第二次 OnCPU第一个系统调用为sock read,也可以理解为网络包出网卡至网络包从网卡收回的 时间。
- 网络时间分类
DNS,TCP建连,常规网络调用
北极星排障指标-存储时间
属于两次OnCPU时间之间的OffCPU时间
- 存储时间打标过程
第一次OnCPU最后一个系统调用执行为VFS read/write与第二次 OnCPU第一个系统调用为VFS read/wirte。
- 存储时间真实情况
存储真实执行情况,由于内核的pagecache存在,所以绝大多数VFS read/write从程序视 角看:执行时间不超过1毫秒。
北极星排障指标-等待时间
- futex
通常指的是一个线程在尝试获取一个futex锁时因为锁已经被其他线程占用而进入等待状态的时间。在这段时间内,线程不会执行任何操作,它会被内核挂起。
- mutex_lock
线程在尝试获取互斥锁时,因为锁已经被其他线程持有而进入等待状态的时间长度。这段时间对于程序的性能至关重要,因为在等待期间,线程不能执行任何有用的工作。
基于北极星指标体系的推理过程
对于单次接口进行统计分析能够得到开发者更容易理解的时间消耗视角
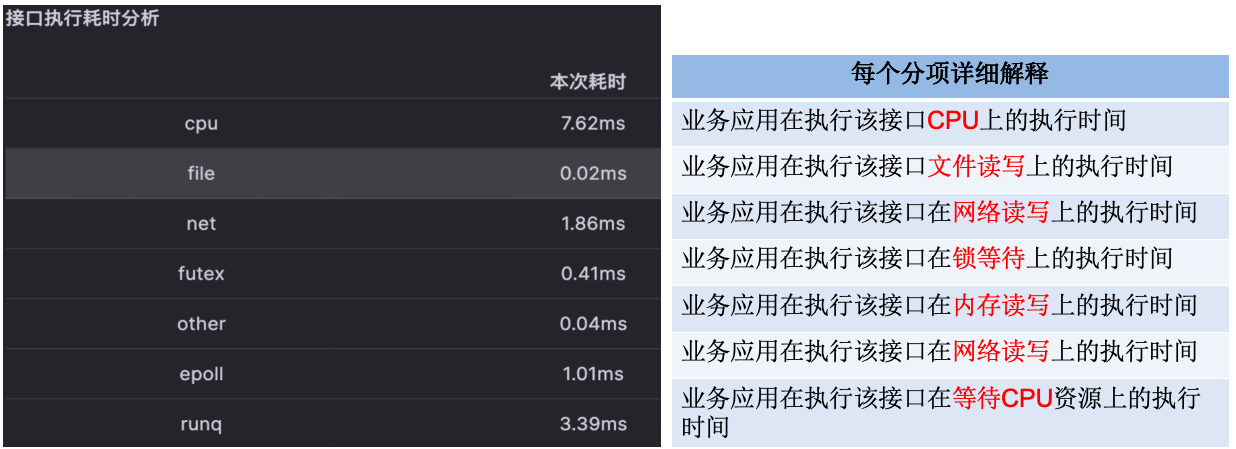
然后对每次接口执行的数据做历史基线即可得到接口历史时间消耗基线
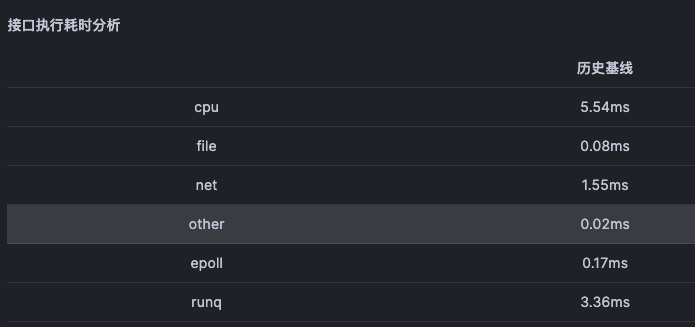
最终当请求异常之时,通过对比异常数据与基线能够得到排障方向
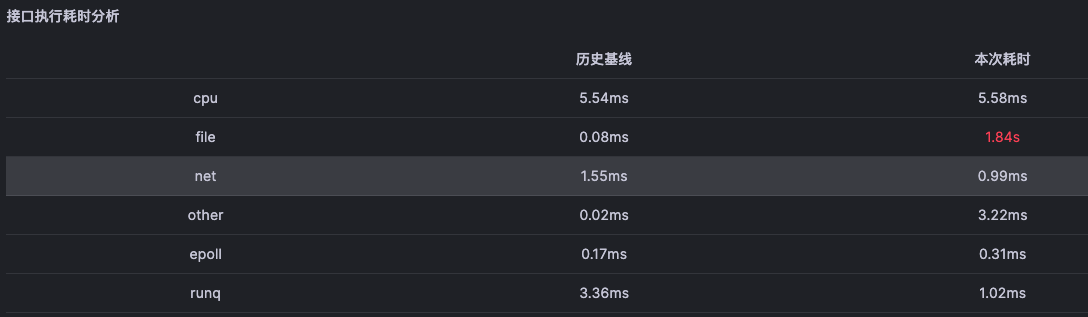
对节点请求进行统计可以得到节点的故障特征
Kindling-OriginX 的故障根因推导
依据标准北极星排障指标体系及其推理过程,Kindling-OriginX 能够自动化推导出故障根因,从根本上解释一次请求慢的根源是在于CPU、网络、磁盘中的具体哪一部分。 Kindling-OriginX 不仅仅给出依据北极星排障指体系的故障根因,还将整个故障根因的推导过程呈现出来,帮助用户更好的理解系统运行的过程。 Kindling-OriginX 为了能够让结论更有可解释性,Kindling-Originx通过与Skywalking,deepflow, prometheus等数据对接获得��更多的指标,并依赖专家经验自动化组织和关联分散的监控指标与日志,用户在一个界面就可以将所需要的指标与日志收集齐全,并确认故障根因是否推导合理。
更多信息参考
KubeCon 2023 中国 :Trace-Profiling: A New Way About How to Track Application Behavior - Cheng Chang
KCD 杭州 :基于 eBPF 采集的排障北极星指标构建故障根因推导流程
eBPF 大会 2024 西安 : 解密如何使用北极星指标体系如何实现根因推理