Kubernetes集群中如何利用北极星因果指标设置正确的POD规格——CPU篇

在 Kubernetes 容量规划中,追求的是集群的稳定性和资源使用效率之间的平衡:
- 资源分配过多会造成浪费。
- 资源分配过少则会导致用户请求时延上升,影响集群的稳定性。
背景
公众号之前翻译了一篇 Sysdig 的文章,Kubernetes 容量规划:如何合理设置集群资源介绍了如何设置合理的资源参数。
虽然按照那�篇文章设置可以有一定的帮助,但仍然可能存在风险。本文将详细说明这些风险,并介绍如何通过北极星指标对 POD 的规格进行调整,以达到时延和资源的完美平衡。
Kubernetes 中的 POD CPU 规格参数
在 Kubernetes 中,POD 的 CPU 规格主要包括以下两个参数:
-
requests: POD 启动时请求的 CPU 资源量。Kubernetes 调度器会根据这个参数将 POD 调度到能够满足资源需求的节点上。
-
limits: POD 运行时能够使用的最大 CPU 资源量。如果 POD 尝试使用超过这个限制的 CPU 资源,会被限制在定义的 limit 值内。
Kubernetes 中的现存指标
要判断 POD 规格是否合适,需通过合适的指标来评估。当前 Kubernetes 中常见的 CPU 指标包括:
- CPU 利用率(container_cpu_usage_seconds_total): 通过类似 PQL 语句获得:
irate(container_cpu_usage_seconds_total{namespace="XXXX", container="XXXX"}[5m])
该指标反映了 CPU 利用率。
-
系统负载:node_load1、node_load5、node_load15 表示系统在 1 分钟、5 分钟和 15 分钟内的平均负载。一般认为负载与 CPU 核数相当即可。
-
CPU 节流(throttle):container_cpu_cfs_throttled_seconds_total, 通过类似 PQL 语句获得:
irate(container_cpu_cfs_throttled_seconds_total{namespace="XXXX", container="XXXX"}[5m])
该指标表示容器由于 CPU 配额不足而被节流的 CPU 核心时间总量。
尽管这些指标对了解 CPU 资源使用情况有帮助,但各自存在局限性,难以单独作为唯一且关键的指标。
北极星指标的应用
所谓北极星指标,是指唯一且最关键的指标。在 Kubernetes 中,该用哪个指标来衡量容器的 CPU 资源是否充足呢?
CPU 利用率指标的局限性
CPU 利用率指标的主要局限性在于:
- 单一性: CPU 利用率反映了容器对 CPU 资源的需求和使用情况。如果利用率持续高企,可能表明容器需要更多的 CPU 资源。然而,仅凭这一指标无法全面反映系统的性能状态。
- 响应时间和性能: 需要考虑容器内应用的响应时间和性能。如果响应时间变长或性能下降,即使 CPU 利用率不高,也可能意味着 CPU 资源不足。
- 并发负载: 在高并发场景下,瞬时的负载高峰可能导致性能问题。CPU 利用率可能无法及时反映这些短期高峰负载的影响。
Load指标的局限性
Load 指标代表有多少执行单元等待调度器执行,但它无法单独衡量 CPU 资源是否充足。
CPU节流指标的局限性
container_cpu_cfs_throttled_seconds_total 指标用于衡量容器因 CPU 资源不足而遭受的 CPU 节流(throttling)。如果该指标的值不为零并且持续增加,通常意味着:
1. CPU 资源不足: 容器的 CPU 使用需求超出了为其分配的 CPU 配额,导致它无法获得足够的 CPU 时间来执行其任务。
2. 性能影响: CPU 节流可能会导致容器内应用的性能下降,因为它们没有足够的 CPU 时间来及时完成任务。
虽然该指标能够直接反映容器是否遭受 CPU 节流,但仅凭它来判断资源是否充足可能会忽略其他重要的性能指标和系统状态。即使 container_cpu_cfs_throttled_seconds_total 不增长,但如果 CPU 调度器队列很长,仍然可能出现 CPU 资源不足的情况。
北极星因果指标中的 CPU 调度耗时
北极星因果指标中的 CPU 调度耗时能够反映出 CPU 节流和高负载下的 CPU 调度延时,包括以下几种情况:
-
CPU 调度队列长: 当程序执行完数据库等网络操作后,如果CPU充分,应该被立马执行,但是当调度队列长时,就会产生等待被调度到 CPU 上的时间。
-
CPU 节流: 代码执行时间片被执行完后,等待下一个调度周期才能被调度到 CPU 上执行的时间。
北极星因果指标中的 CPU 调度耗时能够反映出 CPU 节流和高负载下的 CPU 调度延时。只要该指标不高,即可说明容器的 CPU 资源是充分的;如果该指标高,则说明容器的 CPU 资源是不充分的。
通过准确监控和调整这些指标,可以实现 Kubernetes 集群的稳定可靠性和资源使用效率之间的最佳平衡。
北极星因果指标的CPU调度耗时实际用法举例
Demo环境的route-service的CPU调度耗时异常修复过程
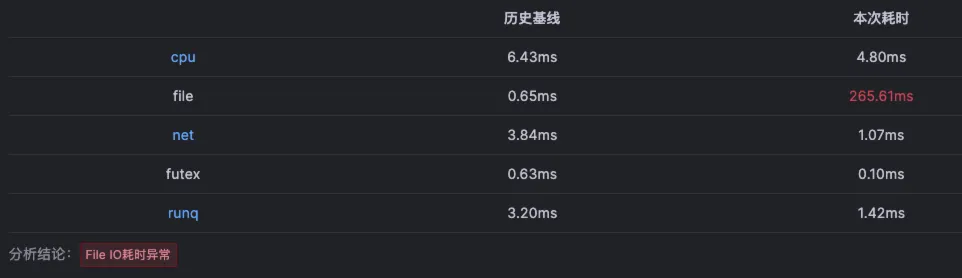
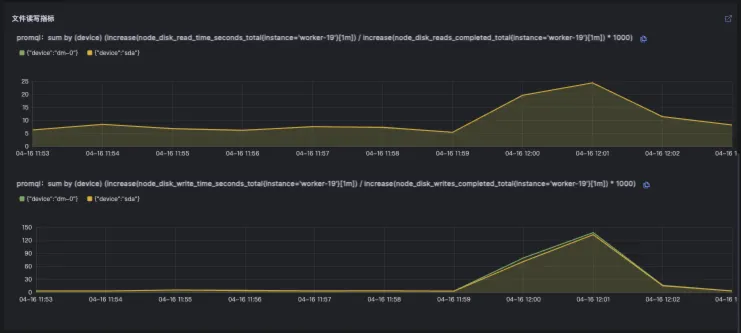
在云观秋毫的Demo环境中,通过北极星因果指标巡检,发现route-service的CPU调度耗时较长,其90分位线经常超过10ms,甚至达到20ms左右。 此时指标已经说明了route-service的CPU资源不充分。

怎么解决呢?是不是直接去增加POD limit的设置呢?
POD规格调整原则一:如果发现CPU节流(throttling)时间高,才需要增加POD limit的配置
通过查询route-service的CPU节流(throttling)指标,发现其CPU节流时间很少,几乎没有波动。这与route-service北极星因果指标中每次请求都有10ms左右情况不符合,说明北极星因果指标中的CPU调度耗时并不是由于CPU节流导致的,也就意味着提高POD limit无法解决问题。
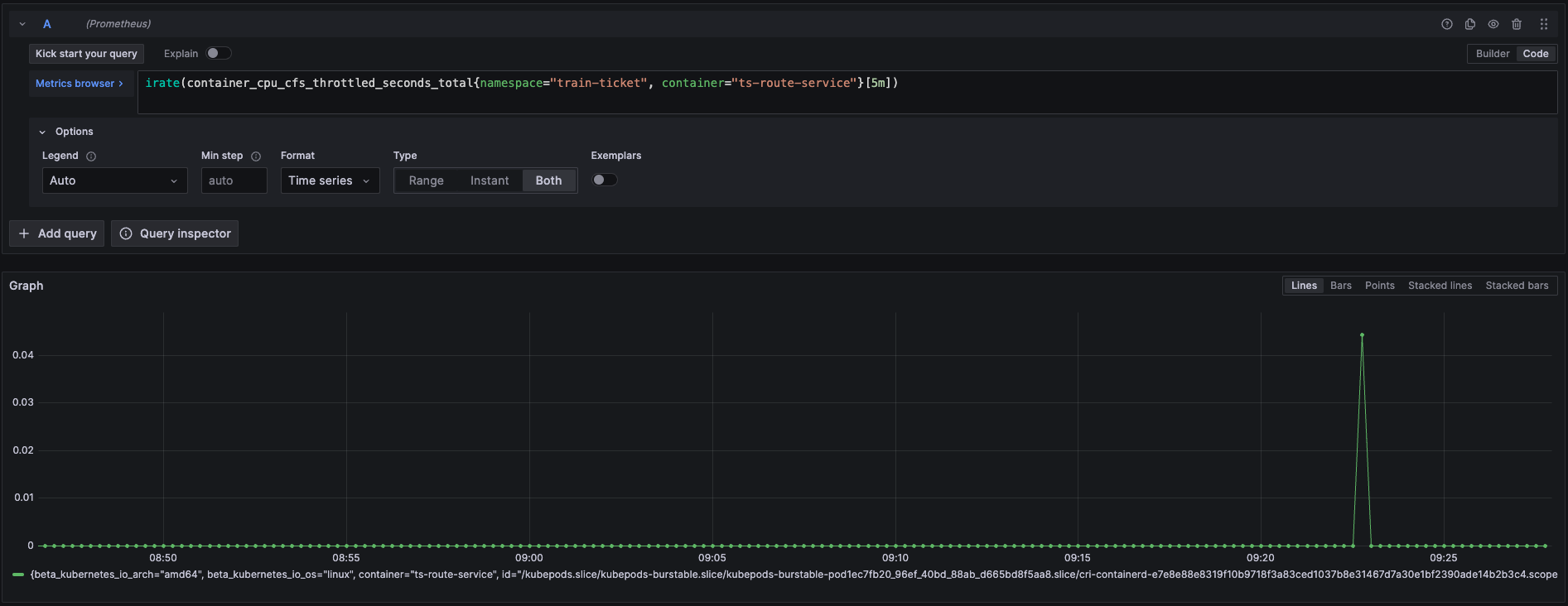
那这种情况只能说明当时的CPU队列很长,当一次任务如数据库调用完成之后,程序需要重新调度到CPU上而产生了调度耗时。为了验证这点,我们继续查看下其CPU利用率指标和节点的Load指标。
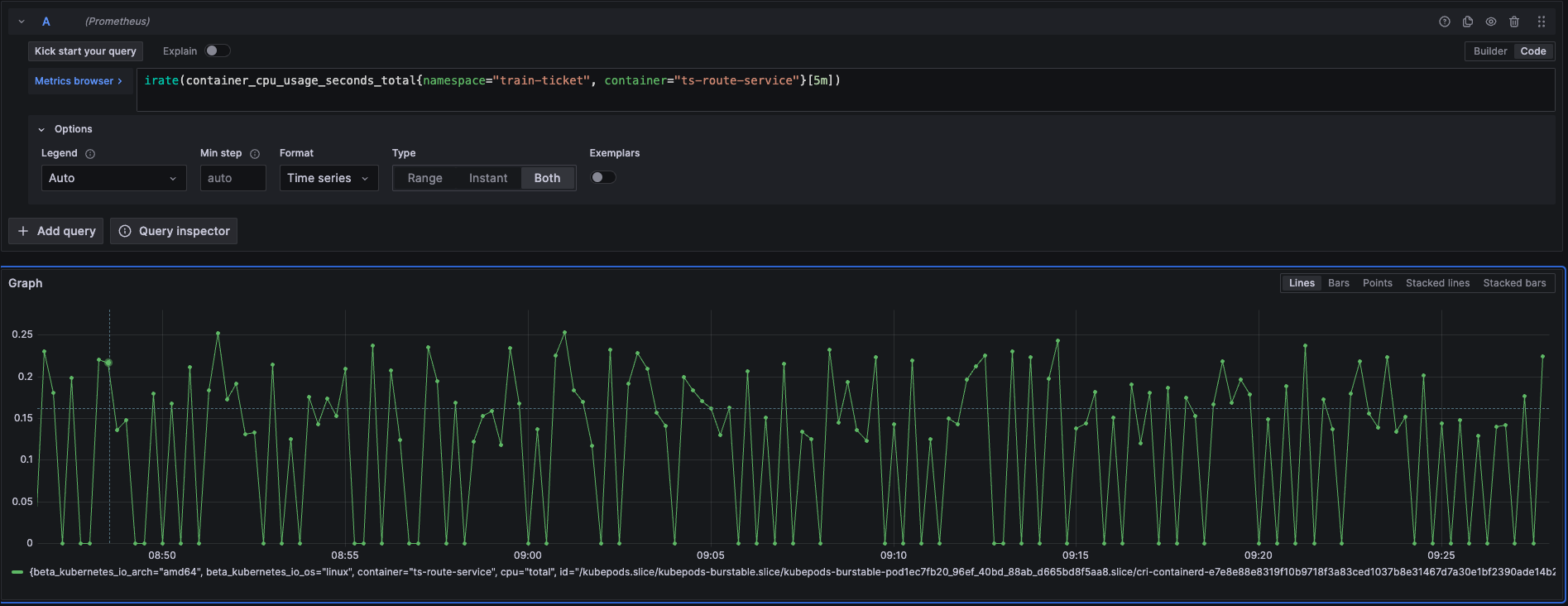

CPU利用率显示其CPU资源是非常充足的,因为route-service所在机器的节点CPU核数为8核,load指标最高位7.13,也是符合预期的。 此时如果没有北极星因果指标,也不知道每次请求有这么高的CPU调度耗时,但是要优化性能,提高容量也就无从谈起了。
为了证明北极星因果指标的正确性,我们将route-service调度到另外一台机器上,在调度之前其load如下:

当调度完成之后,我们再次查看北极星因果指标,发现每次请求CPU调度耗时已经降低了很多,此时调度耗时在90分位线最高也只有8ms,绝大多数请求CPU调度耗时在4ms以下。

此时我们再去查看rout-service的相应延时,发现延时也有了显著的优化:可以看到平均延时在重新调度之前延时是普遍大于20ms的,而调整之后rout-service的延时已经没有高于20ms的了。

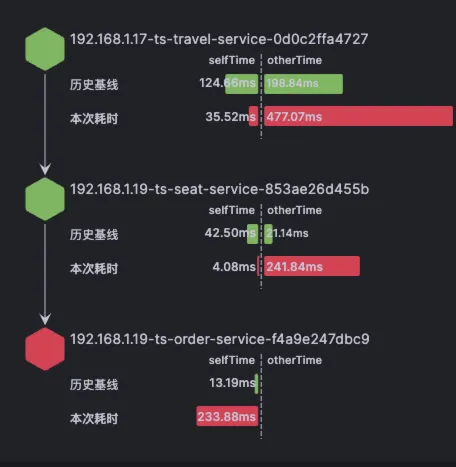
Demo环境的order-service的CPU调度耗时异常修复过程
在云观秋毫的Demo环境中,通过北极星因果指标巡检,发现order-service的CPU调度耗时较长,其90分位线经常超过80ms,甚至达到90ms左右。 此时指标已经说明了order-service的CPU资源不充分。

根据POD规格调整原则一,先去查看容器的CPU节流指标,发现其节流时间确实很大,说明POD的规格Limit设置过小了。
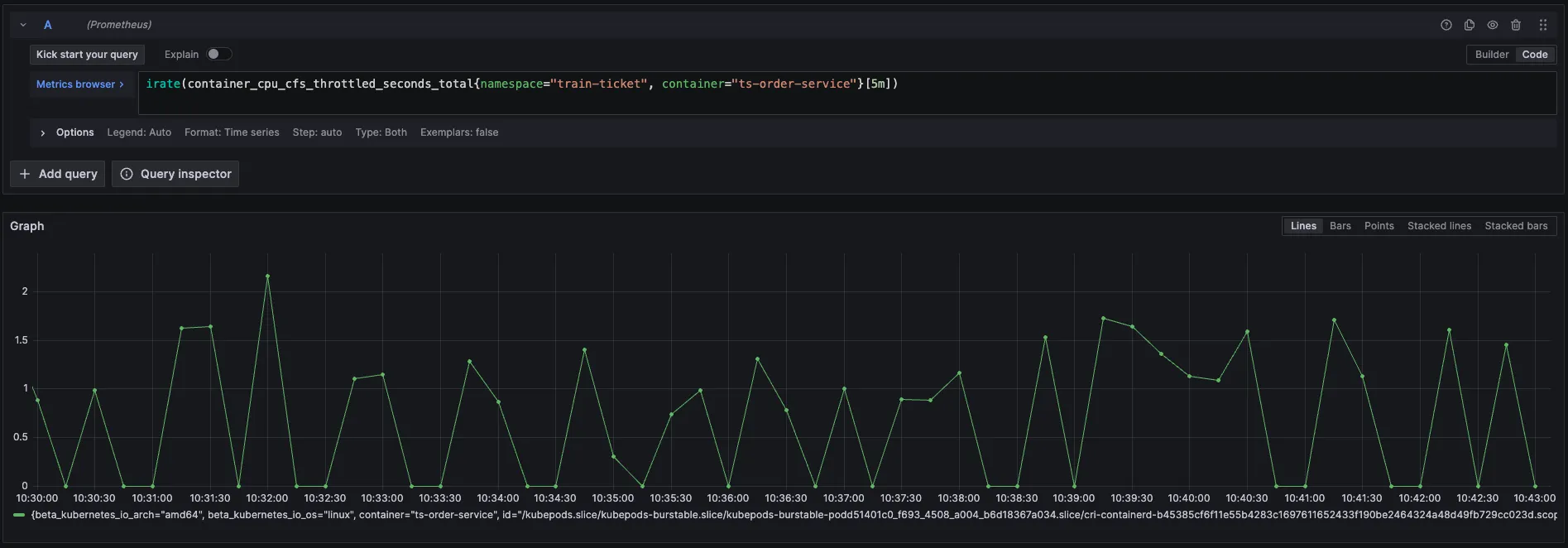
如果只看CPU 利用率,其实还好,并不是一直很高,而是周期性飙高。
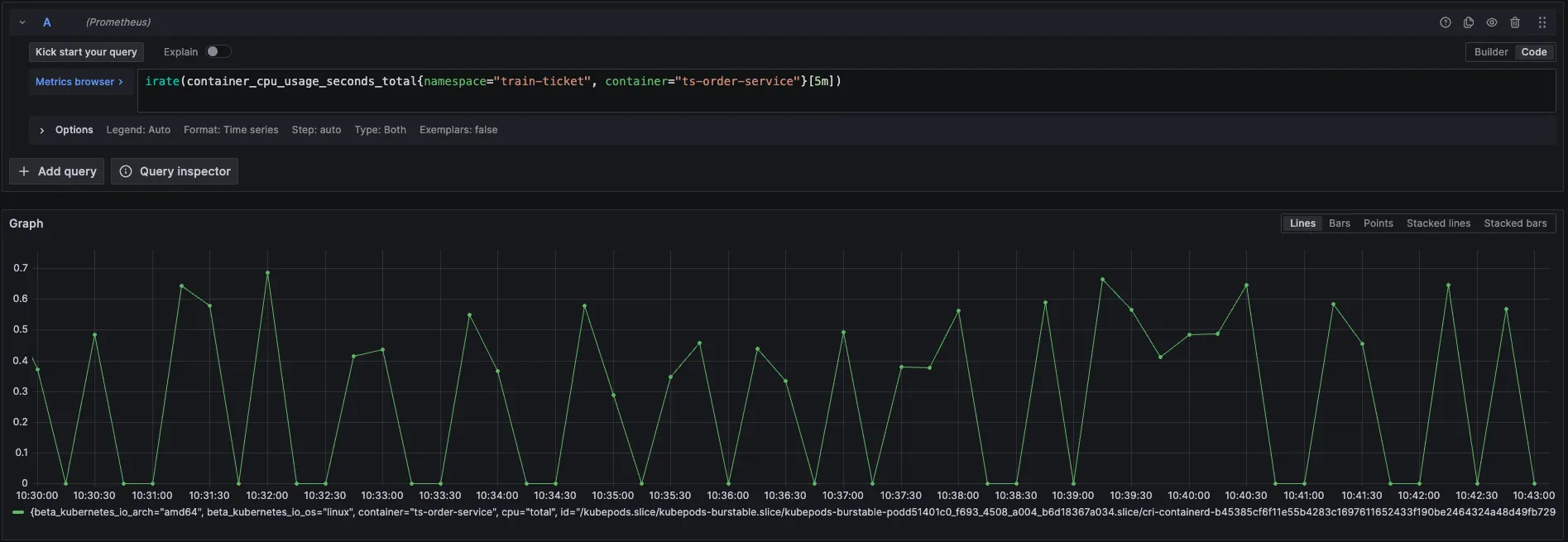
POD规格调整原则二:调整POD Limit设置之时,不需要翻倍的增加CPU核数,而是一个核增加完之后,观察数据,确保最省资源的方式满足业务需求
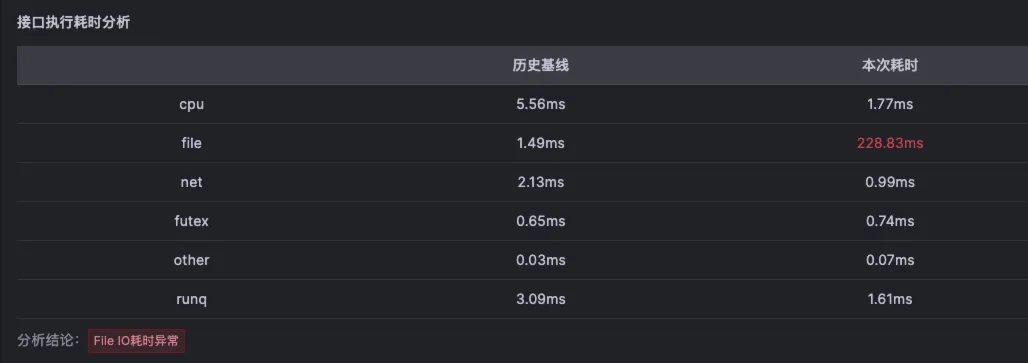
当对order-service的limit增加之后,再看节流指标,此时节流已经很少发生了。
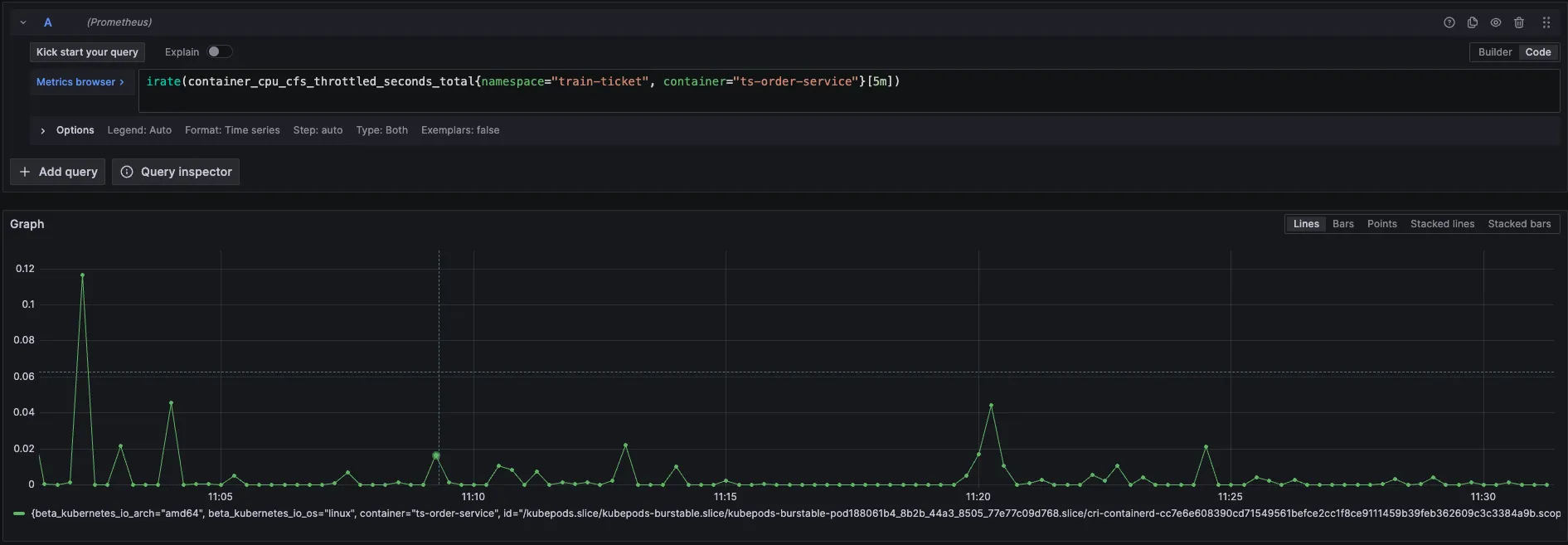
然后我们再看北极星因果指标中的每次请求CPU调度耗时指标,数据从原来的80-90ms 降到了1~2ms左右,甚至90分线最高值才5ms,说明其CPU现在是充分供应了。

最后我们再看看调整前后的时延对比,从调整之前�的90分位线100ms降到了调整之后不到10ms左右。

利用北极星因果指标轻松识别POD运行的应用是CPU密集型还是IO密集型,并完成调度,保证应用的健康状态是最佳的
在计算机知识中,大家都知道不同应用有着不同特征,典型的分类就是CPU密集型和IO密集型,但是我们怎么判断应用是IO密集型还是CPU密集型呢?绝大多数情况下大家是通过主观经验判断,缺少证据证明。
POD调度原则:根据POD应用类型来实现调度
如果根据北极星因果指标中每次请求CPU执行时间超过了响应时间的一半,一般认为其应用为CPU密集型。 根据这个原则发现绝大多数在线业务都不属于CPU密集型,只有那些执行时间非常�短的应用不到20ms的应用,其cpu时间才有可能超过一半。
所以调度原则简化成可以把响应时间短的应用和响应时间长的应用混合调度在一台机器上能够保证应用健康状态是最佳的。